

混合人工智能模型如何平衡记忆与效率
链接表
摘要和1. 引言
-
方法论
-
实验和结果
3.1 在vQuality数据上的语言建模
3.2 关于注意力和线性递归的探索
3.3 高效长度外推
3.4 长上下文理解
-
分析
-
结论、致谢和参考文献
A. 实现细节
B. 额外实验结果
C. 熵测量详情
D. 局限性
\
A 实现细节
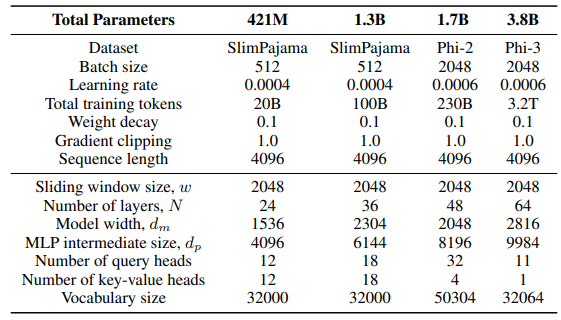
\ 对于滑动GLA架构中的GLA层,我们使用头数dm/384,键扩展比率为0.5,值扩展比率为1。对于RetNet层,我们使用的头数是注意力查询头数的一半,键扩展比率为1,值扩展比率为2。GLA和RetNet的实现来自Flash Linear Attention仓库[3] [YZ24]。我们使用基于FlashAttention的实现进行Self-Extend外推[4]。Mamba 432M模型的模型宽度为1024,Mamba 1.3B模型的模型宽度为2048。除非另有说明,所有在SlimPajama上训练的模型都具有相同的训练配置和与Samba相同的MLP中间大小。SlimPajama上的训练基础设施基于TinyLlama代码库的修改版本[5]。
\ 
\ 在下游任务的生成配置中,我们对GSM8K使用贪婪解码,对HumanEval使用核采样[HBD+19],温度τ = 0.2和top-p = 0.95。对于MBPP和SQuAD,我们设置τ = 0.01和top-p = 0.95。
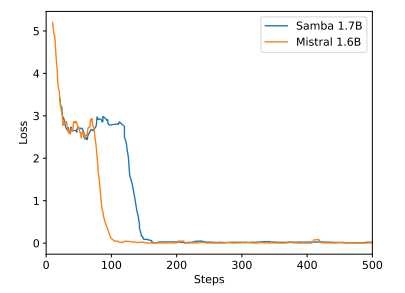
B 额外实验结果
\ 
\ 
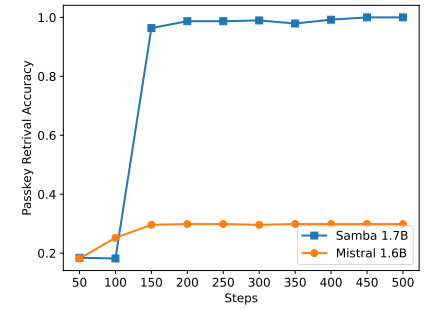
\ 
\
C 熵测量详情
\ 
\
D 局限性
尽管Samba通过指令调优展示了有希望的记忆检索性能,但其预训练基础模型的检索性能与基于SWA的模型相似,如图7所示。这为未来进一步提高Samba的检索能力而不损害其效率和外推能力开辟了方向。此外,Samba的混合策略在所有任务中并不始终优于其他替代方案。如表2所示,MambaSWA-MLP在WinoGrande、SIQA和GSM8K等任务上表现出改进的性能。这使我们有可能投资于更复杂的方法来执行基于SWA和基于SSM模型的输入依赖动态组合。
\
:::info 作者:
(1) Liliang Ren,微软和伊利诺伊大学厄巴纳-香槟分校 ([email protected]);
(2) Yang Liu†,微软 ([email protected]);
(3) Yadong Lu†,微软 ([email protected]);
(4) Yelong Shen,微软 ([email protected]);
(5) Chen Liang,微软 ([email protected]);
(6) Weizhu Chen,微软 ([email protected])。
:::
:::info 本论文可在arxiv上获取,采用CC BY 4.0许可。
:::
[3] https://github.com/sustcsonglin/flash-linear-attention
\ [4] https://github.com/datamllab/LongLM/blob/master/selfextendpatch/Llama.py
\ [5] https://github.com/jzhang38/TinyLlama
您可能也会喜欢

为何Crypto是AI Agent大规模落地的关键基础设施?

Pag-IBIG基金赢得GCG最佳可持续发展倡议奖
