

Überwindung des vollständigen Fine-Tunings mit nur 0,2% der Parameter
Tabelle der Links
Abstrakt und 1. Einleitung
-
Hintergrund
2.1 Mixture-of-Experts
2.2 Adapter
-
Mixture-of-Adaptations
3.1 Routing-Richtlinie
3.2 Konsistenzregularisierung
3.3 Zusammenführung von Adaptationsmodulen und 3.4 Gemeinsame Nutzung von Adaptationsmodulen
3.5 Verbindung zu Bayesschen neuronalen Netzen und Modell-Ensembling
-
Experimente
4.1 Experimenteller Aufbau
4.2 Wichtigste Ergebnisse
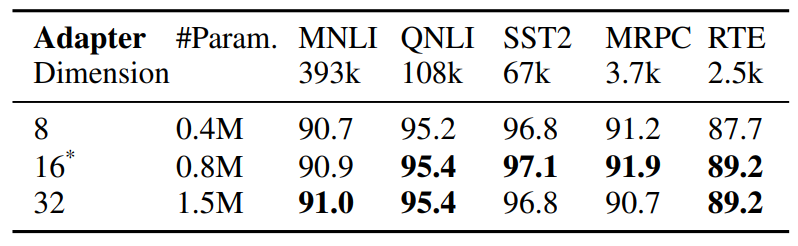
4.3 Ablationsstudie
-
Verwandte Arbeiten
-
Schlussfolgerungen
-
Einschränkungen
-
Danksagung und Referenzen
Anhang
A. Few-shot NLU Datensätze B. Ablationsstudie C. Detaillierte Ergebnisse zu NLU-Aufgaben D. Hyperparameter
5 Verwandte Arbeiten
Parametereffizientes Fine-Tuning von PLMs. Neuere Arbeiten zum parametereffizienten Fine-Tuning (PEFT) können grob in zwei Kategorien eingeteilt werden
\ 
\ Kategorien: (1) Tuning einer Teilmenge vorhandener Parameter, einschließlich Head-Fine-Tuning (Lee et al., 2019), Bias-Term-Tuning (Zaken et al., 2021), (2) Tuning neu eingeführter Parameter, einschließlich Adapter (Houlsby et al., 2019; Pfeiffer et al., 2020), Prompt-Tuning (Lester et al., 2021), Prefix-Tuning (Li und Liang, 2021) und Low-Rank-Adaptation (Hu et al., 2021). Im Gegensatz zu früheren Arbeiten, die mit einem einzelnen Adaptationsmodul arbeiten, führt AdaMix eine Mischung von Adaptationsmodulen mit stochastischem Routing während des Trainings und Zusammenführung von Adaptationsmodulen während der Inferenz ein, um die gleichen Rechenkosten wie bei einem einzelnen Modul beizubehalten. Darüber hinaus kann AdaMix auf jeder PEFT-Methode eingesetzt werden, um deren Leistung weiter zu steigern.
\ Mixture-of-Expert (MoE). Shazeer et al., 2017 führten das MoE-Modell mit einem einzigen Gating-Netzwerk mit Top-k-Routing und Lastausgleich zwischen Experten ein. Fedus et al., 2021 schlagen Initialisierungs- und Trainingsschemata für Top-1-Routing vor. Zuo et al., 2021 schlagen Konsistenzregularisierung für zufälliges Routing vor; Yang et al., 2021 schlagen k Top-1-Routing mit Experten-Prototypen vor, und Roller et al., 2021; Lewis et al., 2021 befassen sich mit anderen Lastausgleichsproblemen. Alle oben genannten Arbeiten untersuchen spärliches MoE mit Vortraining des gesamten Modells von Grund auf. Im Gegensatz dazu untersuchen wir die parametereffiziente Anpassung vortrainierter Sprachmodelle, indem wir nur eine sehr kleine Anzahl spärlicher Adapterparameter optimieren.
\ Mittelung von Modellgewichten. Neuere Untersuchungen (Szegedy et al., 2016; Matena und Raffel, 2021; Wortsman et al., 2022; Izmailov et al., 2018) untersuchen die Modellaggregation durch Mittelung aller Modellgewichte. (Matena und Raffel, 2021) schlagen vor, vortrainierte Sprachmodelle zusammenzuführen, die auf verschiedene Textklassifikationsaufgaben feinabgestimmt wurden. (Wortsman et al., 2022) untersucht die Mittelung von Modellgewichten aus verschiedenen unabhängigen Durchläufen für dieselbe Aufgabe mit unterschiedlichen Hyperparameter-Konfigurationen. Im Gegensatz zu den oben genannten Arbeiten zum vollständigen Modell-Finetuning konzentrieren wir uns auf parametereffizientes Fine-Tuning. Wir untersuchen die Gewichtsmittelung für die Zusammenführung von Gewichten von Adaptationsmodulen, die aus kleinen abstimmbaren Parametern bestehen, die während der Modellabstimmung aktualisiert werden, während die großen Modellparameter fixiert bleiben.
6 Schlussfolgerungen
Wir entwickeln ein neues Framework AdaMix für parametereffizientes Fine-Tuning (PEFT) großer vortrainierter Sprachmodelle (PLM). AdaMix nutzt eine Mischung von Adaptationsmodulen, um die Leistung nachgelagerter Aufgaben zu verbessern, ohne die Rechenkosten (z.B. FLOPs, Parameter) der zugrunde liegenden Adaptationsmethode zu erhöhen. Wir zeigen, dass AdaMix mit verschiedenen PEFT-Methoden wie Adaptern und Niedrigrang-Zerlegungen bei NLU- und NLG-Aufgaben funktioniert und diese verbessert.
\ Durch die Abstimmung von nur 0,1 − 0,2% der PLM-Parameter übertrifft AdaMix das vollständige Modell-Fine-Tuning, das alle Modellparameter aktualisiert, sowie andere moderne PEFT-Methoden.
7 Einschränkungen
Die vorgeschlagene AdaMix-Methode ist etwas rechenintensiv, da sie das Fine-Tuning großer Sprachmodelle beinhaltet. Die Trainingskosten des vorgeschlagenen AdaMix sind höher als bei Standard-PEFT-Methoden, da das Trainingsverfahren mehrere Kopien von Adaptern umfasst. Basierend auf unseren empirischen Beobachtungen liegt die Anzahl der Trainingsiterationen für AdaMix normalerweise zwischen dem 1∼2-fachen des Trainings für Standard-PEFT-Methoden. Dies hat negative Auswirkungen auf den CO2-Fußabdruck beim Training der beschriebenen Modelle.
\ AdaMix steht orthogonal zu den meisten bestehenden Studien zum parametereffizienten Fine-Tuning (PEFT) und kann potenziell die Leistung jeder PEFT-Methode verbessern. In dieser Arbeit untersuchen wir zwei repräsentative PEFT-Methoden wie Adapter und LoRA, haben aber keine Experimente mit anderen Kombinationen wie Prompt-Tuning und Prefix-Tuning durchgeführt. Wir überlassen diese Studien zukünftigen Arbeiten.
8 Danksagung
Die Autoren möchten den anonymen Gutachtern für ihre wertvollen Kommentare und hilfreichen Vorschläge danken und möchten Guoqing Zheng und Ruya Kang für ihre aufschlussreichen Kommentare zum Projekt danken. Diese Arbeit wird teilweise von der US National Science Foundation unter den Grants NSFIIS 1747614 und NSF-IIS-2141037 unterstützt. Alle in diesem Material geäußerten Meinungen, Ergebnisse und Schlussfolgerungen oder Empfehlungen sind die der Autoren und spiegeln nicht unbedingt die Ansichten der National Science Foundation wider.
Referenzen
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. 2021. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7319– 7328, Online. Association for Computational Linguistics.
\ Roy Bar Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. 2006. The second PASCAL recognising textual entailment challenge.
\ Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. 2009. The fifth PASCAL recognizing textual entailment challenge. In TAC.
\ Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel HerbertVoss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
\ Ido Dagan, Oren Glickman, and Bernardo Magnini. 2005. The PASCAL recognising textual entailment challenge. In the First International Conference on Machine Learning Challenges: Evaluating Predictive Uncertainty Visual Object Classification, and Recognizing Textual Entailment.
\ Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Volume 1 (Long and Short Papers), pages 4171–4186.
\ William Fedus, Barret Zoph, and Noam Shazeer. 2021. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv preprint arXiv:2101.03961.
\ Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. 2020. Linear mode connectivity and the lottery ticket hypothesis. In International Conference on Machine Learning, pages 3259–3269. PMLR.
\ Yarin Gal and Zoubin Ghahramani. 2015. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. CoRR, abs/1506.02142.
\ Yarin Gal, Riashat Islam, and Zoubin Ghahramani. 2017. Deep Bayesian active learning with image data. In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1183–1192. PMLR.
\ Tianyu Gao, Adam Fisch, and Danqi Chen. 2021. Making pre-trained language models better few-shot learners. In Association for Computational Linguistics (ACL).
\ Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. 2017. The webnlg challenge: Generating text from rdf data. In Proceedings of the 10th International Conference on Natural Language Generation, pages 124–133.
\ Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and Bill Dolan. 2007. The third PASCAL recognizing textual entailment challenge. In the ACLPASCAL Workshop on Textual Entailment and Paraphrasing.
\ Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR.
\ Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
\ Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. 2018. Averaging weights leads to wider optima and better generalization. arXiv preprint arXiv:1803.05407.
\ Jaejun Lee, Raphael Tang, and Jimmy Lin. 2019. What would elsa do? freezing layers during transformer fine-tuning. arXiv preprint arXiv:1911.03090.
\ Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2020. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668.
\ Brian Lester
Das könnte Ihnen auch gefallen

Michael Saylors Strategie sichert Nasdaq 100-Platz während MSCI-Entscheidung bevorsteht

Messerangriff in Bergkamen: Mann sticht auf Mutter und ihre vier Kinder ein
