

ELK, Loki und Graylog waren übertrieben, also habe ich Log Bull entwickelt
Seit etwa fünf Jahren stehe ich vor der Aufgabe, Logs zu sammeln, typischerweise von kleinen bis mittelgroßen Codebasen. Das Senden von Logs aus dem Code ist kein Problem: Java und Go haben dafür praktisch sofort einsatzbereite Bibliotheken. Aber etwas zu implementieren, um sie zu sammeln, ist ein Kopfschmerz. Ich verstehe, dass es eine lösbare Aufgabe ist (schon vor ChatGPT, und jetzt erst recht). Dennoch sind alle Logging-Systeme in erster Linie auf die große Unternehmenswelt und ihre Anforderungen ausgerichtet, anstatt auf kleine Teams oder einzelne Entwickler mit ein paar Stöcken, Klebstoff und einer "gestern"-Deadline.
Das Starten von ELK ist für mich jedes Mal eine Herausforderung: eine Menge Einstellungen, eine nicht-triviale Bereitstellung, und wenn ich die Benutzeroberfläche betrete, werden meine Augen wild von den Tabs. Mit Loki und Graylog ist es etwas einfacher, aber es gibt immer noch viel mehr Funktionen, als ich brauche. Gleichzeitig ist die Trennung von Logs zwischen Projekten und das Hinzufügen anderer Benutzer zum System, damit sie nichts sehen, was sie nicht sehen sollten, auch kein offensichtlicher Prozess.
Also habe ich mich vor etwa einem Jahr entschieden, mein eigenes Log-Sammelsystem zu erstellen. Eines, das so einfach wie möglich zu benutzen und zu starten ist. Es würde mit einem einzigen Befehl auf dem Server bereitgestellt werden, ohne Konfiguration oder unnötige Tabs in der Benutzeroberfläche. So entstand Log Bull, und jetzt ist es Open Source: ein Log-Sammelsystem für Entwickler mit mittelgroßen Projekten.
Inhaltsverzeichnis:
- Über das Projekt
- Wie wird Log Bull bereitgestellt?
- Wie sendet man Logs?
- Wie betrachtet man Logs?
- Fazit
Über das Projekt
Log Bull ist ein Log-Sammelsystem mit Schwerpunkt auf Benutzerfreundlichkeit (minimale Konfiguration, minimale Funktionen, Zero-Config beim Start). Das Projekt ist vollständig Open Source unter der Apache 2.0-Lizenz. Meine Hauptpriorität war es, eine Lösung zu schaffen, die es einem Junior-Entwickler ermöglicht, leicht herauszufinden, wie man das System startet, wie man Logs daran sendet und wie man sie in etwa 15 Minuten betrachtet.

Hauptmerkmale des Projekts:
- Bereitstellung mit einem einzigen Befehl über ein .sh-Skript oder einen Docker-Befehl.
- Sie können mehrere isolierte Projekte zum Sammeln von Logs erstellen (und Benutzer hinzufügen).
- Extrem einfache Benutzeroberfläche mit minimaler Konfiguration und keine Konfiguration beim Start erforderlich (Zero-Config).
- Bibliotheken für Python, Java, Go, JavaScript (TS \ NodeJS), PHP, C#. Rust und Ruby sind geplant.
- Kostenlos, Open Source und selbst gehostet.
- Keine Notwendigkeit, LogQL, Kibana DSL oder andere Abfragesprachen zu kennen, um Logs zu durchsuchen.
https://www.youtube.com/watch?v=8H8jF8nVzJE&embedable=true
Das Projekt wird in Go entwickelt und basiert auf OpenSearch.
Projekt-Website - https://logbull.com
Projekt GitHub - https://github.com/logbull/logbull
P.S. Wenn Sie das Projekt nützlich finden und ein GitHub-Konto haben, geben Sie ihm bitte einen Stern ⭐️. Die ersten Sterne sind schwer zu sammeln. Ich wäre äußerst dankbar für Ihre Unterstützung!
Wie wird Log Bull bereitgestellt?
Es gibt drei Möglichkeiten, ein Projekt bereitzustellen: über ein .sh-Skript (was ich empfehle), über Docker und über Docker Compose.
Methode 1: Installation über Skript
Das Skript installiert Docker, platziert das Projekt im Ordner /opt/logbull und konfiguriert den Autostart beim Neustart des Systems. Installationsbefehl:
sudo apt-get install -y curl && \ sudo curl -sSL https://raw.githubusercontent.com/logbull/logbull/main/install-logbull.sh \ | sudo bash Methode 2: Start über Docker Compose
Erstellen Sie die Datei docker-compose.yml mit folgendem Inhalt:
services: logbull: container_name: logbull image: logbull/logbull:latest ports: - "4005:4005" volumes: - ./logbull-data:/logbull-data restart: unless-stopped healthcheck: test: ["CMD", "curl", "-f", "http://localhost:4005/api/v1/system/health"] interval: 5s timeout: 5s retries: 30 Und führen Sie den Befehl docker compose up -d aus. Das System wird auf Port 4005 gestartet.
Methode 3: Start über Docker-Befehl
Führen Sie den folgenden Befehl im Terminal aus (das System wird auch auf Port 4005 gestartet):
docker run -d \ --name logbull \ -p 4005:4005 \ -v ./logbull-data:/logbull-data \ --restart unless-stopped \ --health-cmd="curl -f http://localhost:4005/api/v1/system/health || exit 1" \ --health-interval=5s \ --health-retries=30 \ logbull/logbull:latest Wie sendet man Logs?
Ich habe das Projekt mit Blick auf Benutzerfreundlichkeit konzipiert, vor allem für Entwickler. Deshalb habe ich Bibliotheken für die meisten gängigen Entwicklungssprachen erstellt. Ich habe dies mit der Idee getan, dass Log Bull ohne Änderung der aktuellen Codebasis als Prozessor an jede beliebte Bibliothek angeschlossen werden kann.
Ich empfehle dringend, die Beispiele auf der Website zu überprüfen, da es ein interaktives Panel zur Auswahl einer Sprache gibt:
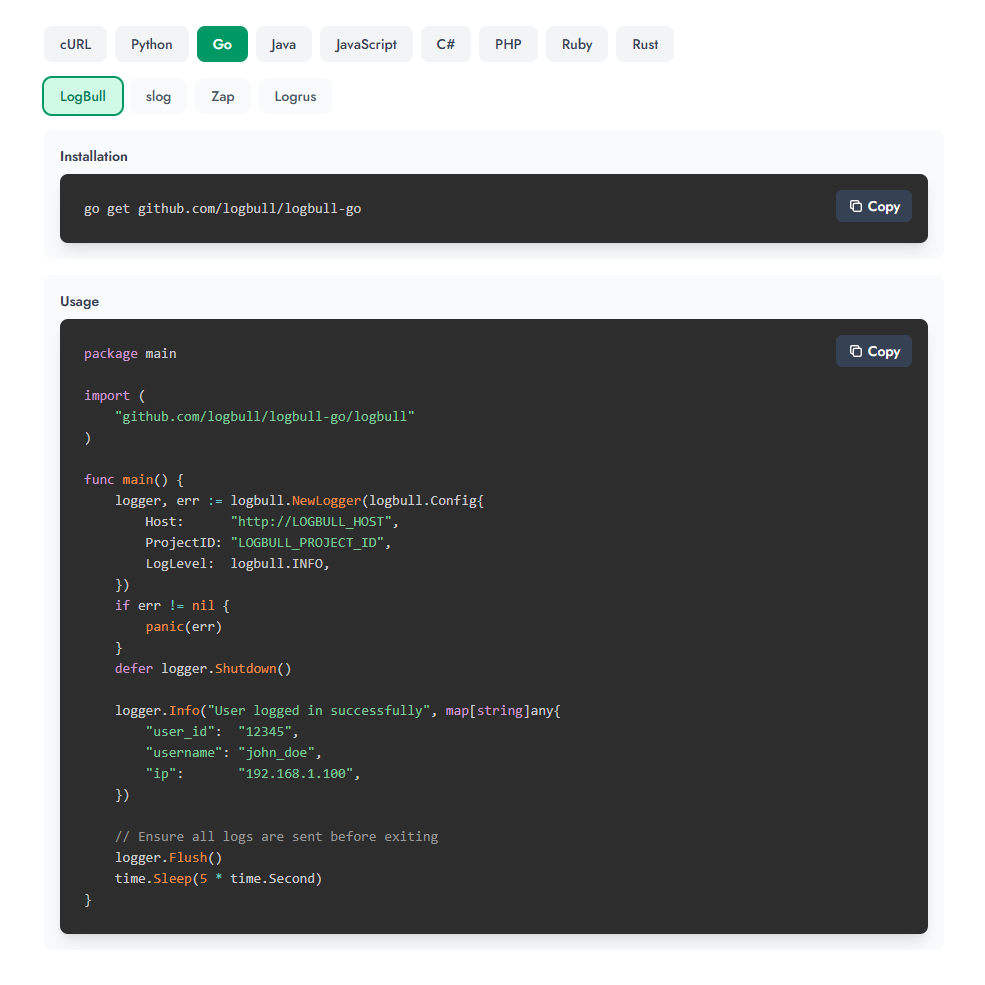
Nehmen wir Python als Beispiel. Zuerst müssen Sie die Bibliothek installieren (obwohl Sie sie auch über HTTP senden können; es gibt Beispiele für cURL):
pip install logbull Dann aus dem Code senden:
import time from logbull import LogBullLogger # Initialize logger logger = LogBullLogger( host="http://LOGBULL_HOST", project_id="LOGBULL_PROJECT_ID", ) # Log messages (printed to console AND sent to LogBull) logger.info("User logged in successfully", fields={ "user_id": "12345", "username": "john_doe", "ip": "192.168.1.100" }) # With context session_logger = logger.with_context({ "session_id": "sess_abc123", "user_id": "user_456" }) session_logger.info("Processing request", fields={ "action": "purchase" }) # Ensure all logs are sent before exiting logger.flush() time.sleep(5) Wie betrachtet man Logs?
Alle Logs werden sofort auf dem Hauptbildschirm angezeigt. Sie können:
-
Die Größe der Nachrichten reduzieren (durch Kürzen der Zeile auf ~50-100 Zeichen).
-
Die Liste der gesendeten Felder erweitern (user_id, order_id usw.).
-
Auf ein Feld klicken und es zum Filter hinzufügen. Logs-Suche mit Bedingungen:
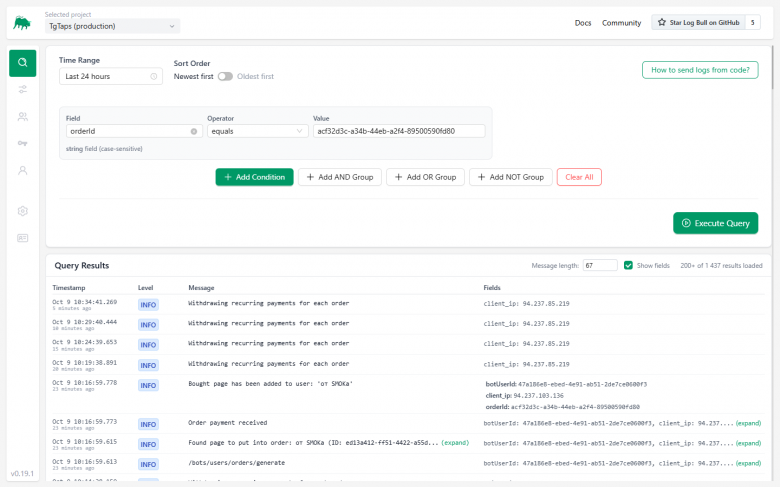
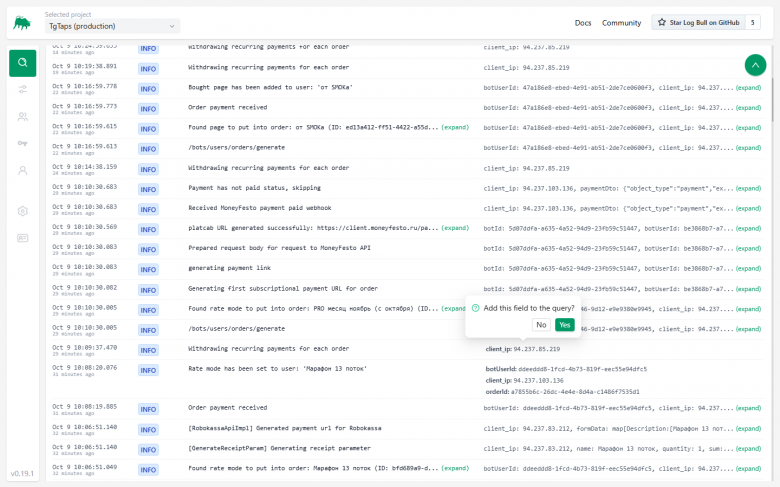
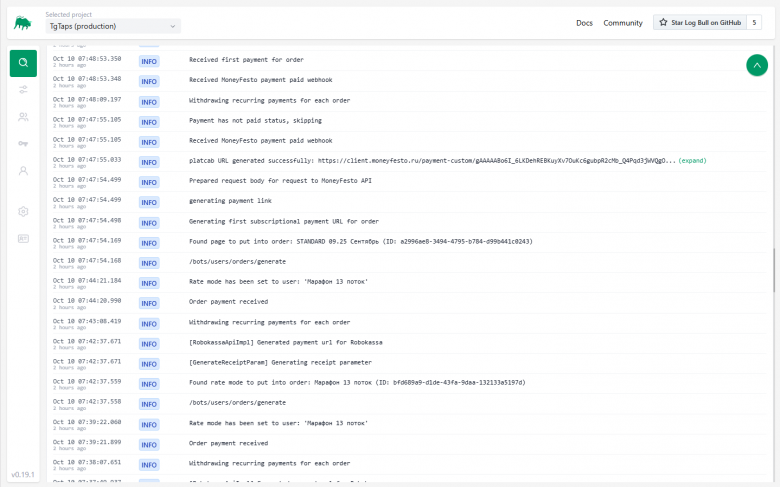
Sie können auch Gruppen von Bedingungen sammeln (zum Beispiel enthält die Nachricht bestimmten Text, schließt aber eine bestimmte Server-IP-Adresse aus).
Fazit
Ich hoffe, dass mein Log-Sammelsystem für diejenigen Entwickler nützlich sein wird, die keine "schwergewichtigen" Lösungen wie ELK implementieren wollen oder können (aufgrund begrenzter Projektressourcen). Ich verwende Log Bull bereits in Produktionsprojekten, und alles läuft gut. Ich freue mich über Feedback, Verbesserungsvorschläge und Issues auf GitHub.
Das könnte Ihnen auch gefallen

Mehrere durch Messer verletzt: Streit in einem Bus in Wuppertal eskaliert

Powell bekräftigt das duale Mandat der Fed als Zinsstrategie
