

Lösung des größten Engpasses bei der 3D-Segmentierung
:::info Autoren:
(1) George Tang, Massachusetts Institute of Technology;
(2) Krishna Murthy Jatavallabhula, Massachusetts Institute of Technology;
(3) Antonio Torralba, Massachusetts Institute of Technology.
:::
Inhaltsverzeichnis
Abstract und I. Einleitung
II. Hintergrund
III. Methode
IV. Experimente
V. Fazit und Referenzen
\ 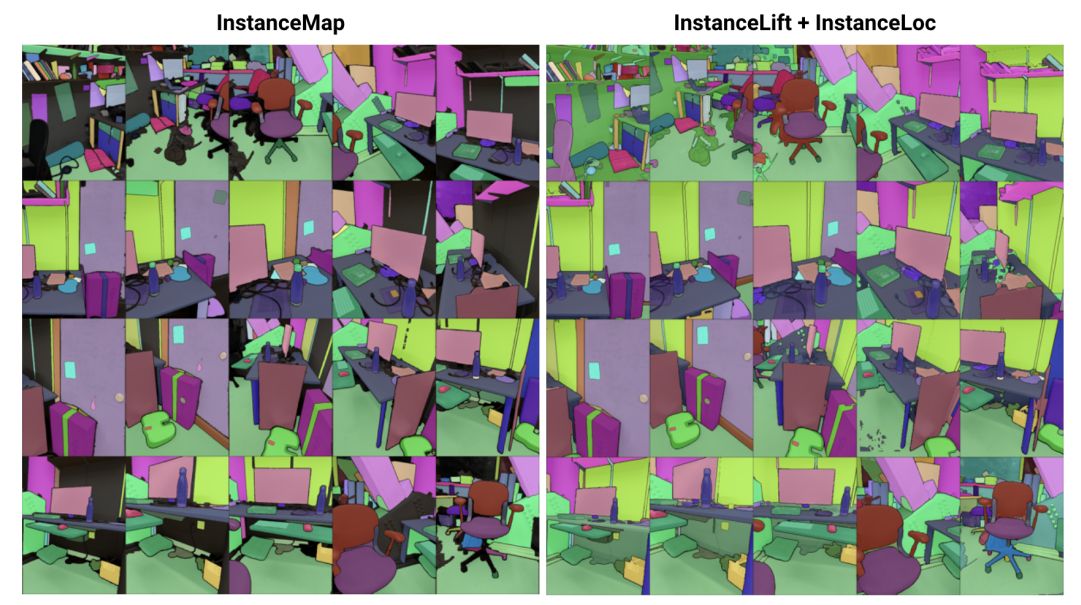
\ Abstract— Wir befassen uns mit dem Problem, eine implizite Szenenrepräsentation für die 3D-Instanzsegmentierung aus einer Sequenz von posierten RGB-Bildern zu lernen. Dazu stellen wir 3DIML vor, ein neuartiges Framework, das effizient ein Labelfeld erlernt, das aus neuen Blickwinkeln gerendert werden kann, um ansichtskonsistente Instanzsegmentierungsmasken zu erzeugen. 3DIML verbessert die Trainings- und Inferenzlaufzeiten bestehender impliziter Szenenrepräsentationsmethoden erheblich. Im Gegensatz zu früheren Ansätzen, die ein neuronales Feld selbstüberwacht optimieren und komplizierte Trainingsverfahren und Verlustfunktionsdesigns erfordern, nutzt 3DIML einen zweiphasigen Prozess. Die erste Phase, InstanceMap, nimmt als Eingabe 2D-Segmentierungsmasken der Bildsequenz, die von einem Frontend-Instanzsegmentierungsmodell generiert wurden, und ordnet entsprechende Masken über Bilder hinweg 3D-Labels zu. Diese fast ansichtskonsistenten Pseudolabel-Masken werden dann in der zweiten Phase, InstanceLift, verwendet, um das Training eines neuronalen Labelfelds zu überwachen, das von InstanceMap verpasste Regionen interpoliert und Mehrdeutigkeiten auflöst. Zusätzlich stellen wir InstanceLoc vor, das eine nahezu Echtzeit-Lokalisierung von Instanzmasken ermöglicht, indem es Ausgaben aus einem trainierten Labelfeld und einem handelsüblichen Bildsegmentierungsmodell fusioniert. Wir evaluieren 3DIML auf Sequenzen aus den Replica- und ScanNet-Datensätzen und demonstrieren die Effektivität von 3DIML unter milden Annahmen für die Bildsequenzen. Wir erreichen eine große praktische Beschleunigung gegenüber bestehenden impliziten Szenenrepräsentationsmethoden bei vergleichbarer Qualität und zeigen damit das Potenzial, ein schnelleres und effektiveres 3D-Szenenverständnis zu ermöglichen.
I. EINLEITUNG
Intelligente Agenten benötigen ein Szenenverständnis auf Objektebene, um kontextspezifische Aktionen wie Navigation und Manipulation effektiv durchzuführen. Während die Segmentierung von Objekten aus Bildern mit skalierbaren Modellen, die auf Internet-Datensätzen trainiert wurden, bemerkenswerte Fortschritte gemacht hat [1], [2], bleibt die Erweiterung solcher Fähigkeiten auf den 3D-Bereich eine Herausforderung.
\ In dieser Arbeit befassen wir uns mit dem Problem, eine 3D-Szenenrepräsentation aus posierten 2D-Bildern zu lernen, die die zugrundeliegende Szene in ihre Menge von Bestandteilen zerlegt. Bestehende Ansätze zur Lösung dieses Problems haben sich auf das Training klassenagnostischer 3D-Segmentierungsmodelle [3], [4] konzentriert, die große Mengen annotierter 3D-Daten erfordern und direkt über explizite 3D-Szenenrepräsentationen (z.B. Punktwolken) arbeiten. Eine alternative Klasse von Ansätzen [5], [6] hat stattdessen vorgeschlagen, Segmentierungsmasken direkt aus handelsüblichen Instanzsegmentierungsmodellen in implizite 3D-Repräsentationen wie neuronale Strahlungsfelder (NeRF) [7] zu übertragen, wodurch sie 3D-konsistente Instanzmasken aus neuen Blickwinkeln rendern können.
\ Die auf neuronalen Feldern basierenden Ansätze sind jedoch notorisch schwer zu optimieren, wobei [5] und [6] mehrere Stunden benötigen, um für Bilder mit niedriger bis mittlerer Auflösung (z.B. 300 × 640) zu optimieren. Insbesondere skaliert Panoptic Lifting [5] kubisch mit der Anzahl der Objekte in der Szene, was verhindert, dass es auf Szenen mit Hunderten von Objekten angewendet werden kann, während Contrastively Lifting [6] ein kompliziertes, mehrstufiges Trainingsverfahren erfordert, was die Praktikabilität für den Einsatz in Roboteranwendungen behindert.
\ Zu diesem Zweck schlagen wir 3DIML vor, eine effiziente Technik zum Erlernen einer 3D-konsistenten Instanzsegmentierung aus posierten RGB-Bildern. 3DIML besteht aus zwei Phasen: InstanceMap und InstanceLift. Gegeben ansichtsinkonsistente 2D-Instanzmasken, die aus der RGB-Sequenz mit einem Frontend-Instanzsegmentierungsmodell [2] extrahiert wurden, erzeugt InstanceMap eine Sequenz von ansichtskonsistenten Instanzmasken. Dazu assoziieren wir zunächst Masken über Frames hinweg mit Keypoint-Matches zwischen ähnlichen Bildpaaren. Dann verwenden wir diese potenziell verrauschten Assoziationen, um ein neuronales Labelfeld, InstanceLift, zu überwachen, das die 3D-Struktur nutzt, um fehlende Labels zu interpolieren und Mehrdeutigkeiten aufzulösen. Im Gegensatz zu früheren Arbeiten, die mehrstufiges Training und zusätzliches Verlustfunktionsengineering erfordern, verwenden wir einen einzigen Rendering-Verlust für die Instanzlabel-Überwachung, was es dem Trainingsprozess ermöglicht, deutlich schneller zu konvergieren. Die Gesamtlaufzeit von 3DIML, einschließlich InstanceMap, beträgt 10-20 Minuten, im Gegensatz zu 3-6 Stunden für frühere Ansätze.
\ Zusätzlich entwickeln wir InstaLoc, eine schnelle Lokalisierungspipeline, die eine neue Ansicht aufnimmt und alle in diesem Bild segmentierten Instanzen (mit einem schnellen Instanzsegmentierungsmodell [8]) lokalisiert, indem sie das Labelfeld sparsam abfragt und die Labelvorhersagen mit extrahierten Bildbereichen fusioniert. Schließlich ist 3DIML äußerst modular, und wir können Komponenten unserer Methode leicht durch leistungsfähigere austauschen, sobald diese verfügbar werden.
\ Zusammenfassend sind unsere Beiträge:
\ • Ein effizienter Ansatz zum Lernen neuronaler Felder, der eine 3D-Szene in ihre Bestandteile zerlegt
\ • Ein schneller Instanzlokalisierungsalgorithmus, der spärliche Abfragen an das trainierte Labelfeld mit leistungsfähigen Bildinstanzsegmentierungsmodellen fusioniert, um 3D-konsistente Instanzsegmentierungsmasken zu generieren
\ • Eine praktische Laufzeitverbesserung von insgesamt 14-24× gegenüber früheren Ansätzen, getestet auf einer einzelnen GPU (NVIDIA RTX 3090)
II. HINTERGRUND
2D-Segmentierung: Die Verbreitung der Vision-Transformer-Architektur und der zunehmende Umfang von Bilddatensätzen haben zu einer Reihe von State-of-the-Art-Bildsegmentierungsmodellen geführt. Panoptic und Contrastive Lifting übertragen beide panoptische Segmentierungsmasken, die von Mask2Former [1] erzeugt wurden, in 3D, indem sie ein neuronales Feld lernen. Für die Open-Set-Segmentierung erreicht Segment Anything (SAM) [2] eine beispiellose Leistung durch Training auf einer Milliarde Masken über 11 Millionen Bilder. HQ-SAM [9] verbessert SAM für feinkörnige Masken. FastSAM [8] destilliert SAM in eine CNN-Architektur und erreicht eine ähnliche Leistung, ist jedoch um Größenordnungen schneller. In dieser Arbeit verwenden wir GroundedSAM [10], [11], das SAM verfeinert, um Segmentierungsmasken auf Objektebene anstatt auf Teilebene zu erzeugen.
\ Neuronale Felder für 3D-Instanzsegmentierung: NeRFs sind implizite Szenenrepräsentationen, die komplexe Geometrie, Semantik und andere Modalitäten genau kodieren sowie blickpunktinkonsistente Überwachung auflösen können [12]. Panoptic Lifting [5] konstruiert Semantik- und Instanzzweige auf einer effizienten Variante von NeRF, TensoRF [13], und verwendet eine ungarische Matching-Verlustfunktion, um gelernte Instanzmasken Surrogat-Objekt-IDs zuzuweisen, gegeben Referenz-blickpunktinkonsistente Masken. Dies skaliert schlecht mit zunehmender Anzahl von Objekten (aufgrund der kubischen Komplexität des ungarischen Matchings). Contrastive Lifting [6] adressiert dies, indem es stattdessen kontrastives Lernen auf Szenenmerkmalen einsetzt, wobei positive und negative Beziehungen dadurch bestimmt werden, ob sie auf dieselbe Maske projizieren oder nicht. Darüber hinaus erfordert Contrastive Lifting einen langsam-schnellen, cluster-basierten Verlust für stabiles Training, was zu einer schnelleren Leistung als Panoptic Lifting führt, aber mehrere Trainingsstufen erfordert, was zu einer langsamen Konvergenz führt. Parallel zu uns lernt Instance-NeRF [14] direkt ein Labelfeld, basiert seine Maskenassoziation jedoch auf der Verwendung von NeRF-RPN [15], um Objekte in einem NeRF zu erkennen. Unser Ansatz hingegen ermöglicht die Skalierung auf sehr hohe Bildauflösungen, während nur eine kleine Anzahl (40-60) von neuronalen Feldabfragen erforderlich ist, um Segmentierungsmasken zu rendern.
\ Structure from Motion: Während der Maskenassoziation in InstanceMap lassen wir uns von skalierbaren 3D-Rekonstruktionspipelines wie hLoc [16] inspirieren, einschließlich der Verwendung visueller Deskriptoren zum Matching von Bildblickpunkten zuerst, und wenden dann Keypoint-Matching als Vorstufe für die Maskenassoziation an. Wir verwenden LoFTR [17] für die Keypoint-Extraktion und das Matching.
\
:::info Dieses Paper ist auf arxiv verfügbar unter der CC by 4.0 Deed (Attribution 4.0 International) Lizenz.
:::
\
Das könnte Ihnen auch gefallen

Internationale Krisendiplomatie: Ukraine-Beratungen beginnen schon am Sonntag in Berlin

Ripple erhält Zugang zum US-Bankensystem und befeuert XRPs langfristiges Ziel in Richtung 27 $
