

Transformerbasierte Anomalieerkennung mit Log-Sequenz-Einbettungen

Inhaltsverzeichnis
Abstrakt
1 Einleitung
2 Hintergrund und verwandte Arbeiten
2.1 Verschiedene Formulierungen der log-basierten Anomalieerkennung
2.2 Überwacht vs. unüberwacht
2.3 Informationen in Log-Daten
2.4 Fix-Window-Gruppierung
2.5 Verwandte Arbeiten
3 Ein konfigurierbarer Transformer-basierter Ansatz zur Anomalieerkennung
3.1 Problemformulierung
3.2 Log-Parsing und Log-Einbettung
3.3 Positions- & Zeitkodierung
3.4 Modellstruktur
3.5 Überwachte binäre Klassifikation
4 Experimenteller Aufbau
4.1 Datensätze
4.2 Bewertungsmetriken
4.3 Generierung von Log-Sequenzen unterschiedlicher Länge
4.4 Implementierungsdetails und experimentelle Umgebung
5 Experimentelle Ergebnisse
5.1 RQ1: Wie schneidet unser vorgeschlagenes Anomalieerkennungsmodell im Vergleich zu den Baselines ab?
5.2 RQ2: Wie stark beeinflussen sequentielle und zeitliche Informationen innerhalb von Log-Sequenzen die Anomalieerkennung?
5.3 RQ3: Wie stark tragen die verschiedenen Informationstypen einzeln zur Anomalieerkennung bei?
6 Diskussion
7 Bedrohungen der Validität
8 Schlussfolgerungen und Referenzen
\
3 Ein konfigurierbarer Transformer-basierter Ansatz zur Anomalieerkennung
In dieser Studie stellen wir eine neuartige Transformer-basierte Methode zur Anomalieerkennung vor. Das Modell verwendet Log-Sequenzen als Eingaben, um Anomalien zu erkennen. Das Modell nutzt ein vortrainiertes BERT-Modell, um Log-Vorlagen einzubetten, was die Darstellung semantischer Informationen innerhalb von Log-Nachrichten ermöglicht. Diese Einbettungen werden zusammen mit Positions- oder Zeitkodierung anschließend in das Transformer-Modell eingegeben. Die kombinierten Informationen werden bei der nachfolgenden Generierung von Log-Sequenz-Darstellungen verwendet, was den Anomalieerkennungsprozess erleichtert. Wir gestalten unser Modell flexibel: Die Eingabemerkmale sind konfigurierbar, sodass wir Experimente mit verschiedenen Merkmalskombinationen der Log-Daten durchführen können. Darüber hinaus ist das Modell so konzipiert und trainiert, dass es mit Eingabe-Log-Sequenzen unterschiedlicher Länge umgehen kann. In diesem Abschnitt stellen wir unsere Problemformulierung und das detaillierte Design unserer Methode vor.
\ 3.1 Problemformulierung
Wir folgen den früheren Arbeiten [1], um die Aufgabe als binäre Klassifikationsaufgabe zu formulieren, bei der wir unser vorgeschlagenes Modell trainieren, um Log-Sequenzen auf überwachte Weise in Anomalien und normale Sequenzen zu klassifizieren. Für die Proben, die beim Training und bei der Bewertung des Modells verwendet werden, nutzen wir einen flexiblen Gruppierungsansatz, um Log-Sequenzen unterschiedlicher Länge zu generieren. Die Details werden in Abschnitt 4 vorgestellt
\ 3.2 Log-Parsing und Log-Einbettung
In unserer Arbeit transformieren wir Log-Ereignisse in numerische Vektoren, indem wir Log-Vorlagen mit einem vortrainierten Sprachmodell kodieren. Um die Log-Vorlagen zu erhalten, verwenden wir den Drain-Parser [24], der weit verbreitet ist und eine gute Parsing-Leistung bei den meisten öffentlichen Datensätzen [4] aufweist. Wir verwenden ein vortrainiertes Sentence-BERT-Modell [25] (d.h. all-MiniLML6-v2 [26]), um die vom Log-Parsing-Prozess generierten Log-Vorlagen einzubetten. Das vortrainierte Modell wird mit einem kontrastiven Lernziel trainiert und erzielt State-of-the-Art-Leistung bei verschiedenen NLP-Aufgaben. Wir nutzen dieses vortrainierte Modell, um eine Darstellung zu erstellen, die semantische Informationen von Log-Nachrichten erfasst und die Ähnlichkeit zwischen Log-Vorlagen für das nachgelagerte Anomalieerkennungsmodell veranschaulicht. Die Ausgabedimension des Modells beträgt 384.
\ 3.3 Positions- & Zeitkodierung
Das ursprüngliche Transformer-Modell [27] verwendet eine Positionskodierung, um dem Modell die Nutzung der Reihenfolge der Eingabesequenz zu ermöglichen. Da das Modell weder Rekurrenz noch Faltung enthält, wären die Modelle ohne die Positionskodierung gegenüber der Log-Sequenz agnostisch. Während einige Studien darauf hindeuten, dass Transformer-Modelle ohne explizite Positionskodierung beim Umgang mit sequentiellen Daten mit Standardmodellen konkurrenzfähig bleiben [28, 29], ist es wichtig zu beachten, dass jede Permutation der Eingabesequenz den gleichen internen Zustand des Modells erzeugt. Da sequentielle oder zeitliche Informationen wichtige Indikatoren für Anomalien innerhalb von Log-Sequenzen sein können, nutzen frühere Arbeiten, die auf Transformer-Modellen basieren, die Standard-Positionskodierung, um die Reihenfolge von Log-Ereignissen oder -Vorlagen in der Sequenz einzufügen [11, 12, 21], mit dem Ziel, Anomalien im Zusammenhang mit falscher Ausführungsreihenfolge zu erkennen. Wir haben jedoch festgestellt, dass in einer häufig verwendeten Replikationsimplementierung einer Transformer-basierten Methode [5] die Positionskodierung tatsächlich weggelassen wurde. Nach unserem besten Wissen hat keine bestehende Arbeit die zeitlichen Informationen basierend auf den Zeitstempeln von Logs für ihre Anomalieerkennungsmethode kodiert. Die Wirksamkeit der Nutzung sequentieller oder zeitlicher Informationen bei der Anomalieerkennungsaufgabe ist unklar.
\ In unserer vorgeschlagenen Methode versuchen wir, sequentielle und zeitliche Kodierung in das Transformer-Modell zu integrieren und die Bedeutung sequentieller und zeitlicher Informationen für die Anomalieerkennung zu untersuchen. Insbesondere hat unsere vorgeschlagene Methode verschiedene Varianten, die die folgenden sequentiellen oder zeitlichen Kodierungstechniken nutzen. Die Kodierung wird dann zur Log-Darstellung hinzugefügt, die als Eingabe für die Transformer-Struktur dient.
\ 
3.3.1 Relative Zeitablauf-Kodierung (RTEE)
Wir schlagen diese zeitliche Kodierungsmethode, RTEE, vor, die einfach den Positionsindex in der Positionskodierung durch den Zeitpunkt jedes Log-Ereignisses ersetzt. Wir berechnen zunächst den Zeitablauf gemäß den Zeitstempeln der Log-Ereignisse in der Log-Sequenz. Anstatt den Log-Ereignissequenzindex als Position für sinusförmige und kosinusförmige Gleichungen zu verwenden, verwenden wir den relativen Zeitablauf zum ersten Log-Ereignis in der Log-Sequenz, um den Positionsindex zu ersetzen. Tabelle 1 zeigt ein Beispiel für Zeitintervalle in einer Log-Sequenz. In dem Beispiel haben wir eine Log-Sequenz mit 7 Ereignissen und einer Zeitspanne von 7 Sekunden. Die verstrichene Zeit vom ersten Ereignis zu jedem Ereignis in der Sequenz wird verwendet, um die Zeitkodierung für die entsprechenden Ereignisse zu berechnen. Ähnlich wie bei der Positionskodierung wird die Kodierung mit den oben genannten Gleichungen 1 berechnet, und die Kodierung wird während des Trainingsprozesses nicht aktualisiert.
\ 
3.4 Modellstruktur
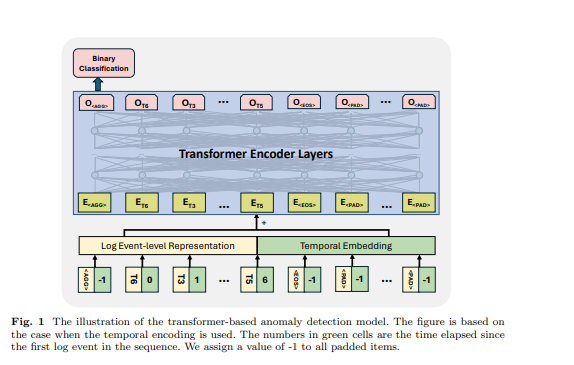
Der Transformer ist eine neuronale Netzwerkarchitektur, die auf dem Selbstaufmerksamkeitsmechanismus basiert, um die Beziehung zwischen Eingabeelementen in einer Sequenz zu erfassen. Die Transformer-basierten Modelle und Frameworks wurden in der Anomalieerkennungsaufgabe von vielen früheren Arbeiten verwendet [6, 11, 12, 21]. Inspiriert von den früheren Arbeiten verwenden wir ein Transformer-Encoder-basiertes Modell für die Anomalieerkennung. Wir gestalten unseren Ansatz so, dass er Log-Sequenzen unterschiedlicher Länge akzeptiert und Sequenz-Level-Darstellungen generiert. Um dies zu erreichen, haben wir einige spezifische Token in der Eingabe-Log-Sequenz verwendet, damit das Modell Sequenzdarstellungen generieren und die gepolsterten Token und das Ende der Log-Sequenz identifizieren kann, inspiriert vom Design des BERT-Modells [31]. In der Eingabe-Log-Sequenz haben wir die folgenden Token verwendet: wird am Anfang jeder Sequenz platziert, um dem Modell zu ermöglichen, aggregierte Informationen für die gesamte Sequenz zu generieren, wird am Ende der Sequenz hinzugefügt, um deren Abschluss zu signalisieren, wird verwendet, um die maskierten Token unter dem selbstüberwachten Trainingsparadigma zu markieren, und wird für gepolsterte Token verwendet. Die Einbettungen für diese speziellen Token werden zufällig basierend auf der Dimension der verwendeten Log-Darstellung generiert. Ein Beispiel ist in Abbildung 1 dargestellt, die verstrichene Zeit für , und ist auf -1 gesetzt. Die Log-Ereignis-Level-Darstellung und die Positions- oder Zeiteinbettung werden als Eingabemerkmal der Transformer-Struktur summiert.
\ 3.5 Überwachte binäre Klassifikation Bei diesem Trainingsziel nutzen wir die Ausgabe des ersten Tokens des Transformer-Modells, während wir die Ausgaben der anderen Token ignorieren. Diese Ausgabe des ersten Tokens ist so konzipiert, dass sie die Informationen der gesamten Eingabe-Log-Sequenz aggregiert, ähnlich dem Token des BERT-Modells, das eine aggregierte Darstellung der Token-Sequenz bietet. Daher betrachten wir die Ausgabe dieses Tokens als Sequenz-Level-Darstellung. Wir trainieren das Modell mit einem binären Klassifikationsziel (d.h. Binary Cross Entropy Loss) mit dieser Darstellung.
\ 
:::info Autoren:
- Xingfang Wu
- Heng Li
- Foutse Khomh
:::
:::info Dieses Paper ist auf arxiv verfügbar unter der CC by 4.0 Deed (Attribution 4.0 International) Lizenz.
:::
\


Das könnte Ihnen auch gefallen

Solana muss über dem entscheidenden $78-Niveau bleiben – Analyst erklärt warum
Dogecoin (DOGE) Kurs: Der Meme-Coin, der nicht stirbt — Aber ist er wirklich eine gute Investition?

Roman Storm wirft dem DOJ vor, Debanking als Waffe einzusetzen, um seine Rechtsverteidigung zu sabotieren



