

Offene semantische Extraktion: Grounded-SAM, CLIP und DINOv2 Pipeline
Inhaltsverzeichnis
Abstrakt und 1 Einleitung
-
Verwandte Arbeiten
2.1. Vision-und-Sprache-Navigation
2.2. Semantisches Szenenverständnis und Instanzsegmentierung
2.3. 3D-Szenenrekonstruktion
-
Methodik
3.1. Datensammlung
3.2. Open-Set semantische Informationen aus Bildern
3.3. Erstellung der Open-Set 3D-Repräsentation
3.4. Sprachgeführte Navigation
-
Experimente
4.1. Quantitative Auswertung
4.2. Qualitative Ergebnisse
-
Fazit und zukünftige Arbeit, Offenlegungserklärung und Referenzen
3.2. Open-Set semantische Informationen aus Bildern
\ 3.2.1. Open-Set semantische und Instanzmasken-Erkennung
\ Das kürzlich veröffentlichte Segment Anything Model (SAM) [21] hat aufgrund seiner hochmodernen Segmentierungsfähigkeiten erhebliche Popularität unter Forschern und Industriepraktikern gewonnen. Allerdings neigt SAM dazu, eine übermäßige Anzahl von Segmentierungsmasken für dasselbe Objekt zu erzeugen. Wir verwenden das Grounded-SAM [32] Modell für unsere Methodik, um dieses Problem zu lösen. Dieser Prozess beinhaltet die Generierung einer Reihe von Masken in drei Phasen, wie in Abbildung 2 dargestellt. Zunächst wird eine Reihe von Textlabels mit dem Recognizing Anything Model (RAM) [33] erstellt. Anschließend werden Begrenzungsrahmen entsprechend dieser Labels mit dem Grounding DINO Modell [25] erstellt. Das Bild und die Begrenzungsrahmen werden dann in SAM eingegeben, um klassenunabhängige Segmentierungsmasken für die im Bild sichtbaren Objekte zu generieren. Wir bieten eine detaillierte Erklärung dieses Ansatzes unten, der das Problem der Übersegmentierung effektiv mildert, indem semantische Erkenntnisse aus RAM und Grounding-DINO einbezogen werden.
\ Das RAM-Modell [33] verarbeitet das RGB-Eingabebild, um eine semantische Kennzeichnung des im Bild erkannten Objekts zu erzeugen. Es ist ein robustes Grundlagenmodell für Bild-Tagging, das bemerkenswerte Zero-Shot-Fähigkeiten bei der genauen Identifizierung verschiedener gängiger Kategorien zeigt. Die Ausgabe dieses Modells verbindet jedes Eingabebild mit einer Reihe von Labels, die die Objektkategorien im Bild beschreiben. Der Prozess beginnt mit dem Zugriff auf das Eingabebild und der Umwandlung in den RGB-Farbraum, dann wird es an die Eingabeanforderungen des Modells angepasst und schließlich in einen Tensor umgewandelt, wodurch es mit der Analyse durch das Modell kompatibel wird. Danach generiert das RAM-Modell Labels oder Tags, die die verschiedenen Objekte oder Merkmale im Bild beschreiben. Ein Filtrationsprozess wird angewendet, um die generierten Labels zu verfeinern, was die Entfernung unerwünschter Klassen aus diesen Labels beinhaltet. Insbesondere werden irrelevante Tags wie "Wand", "Boden", "Decke" und "Büro" verworfen, zusammen mit anderen vordefinierten Klassen, die für den Kontext der Studie als unnötig erachtet werden. Zusätzlich ermöglicht diese Phase die Erweiterung des Label-Sets mit erforderlichen Klassen, die vom RAM-Modell zunächst nicht erkannt wurden. Schließlich werden alle relevanten Informationen in einem strukturierten Format zusammengefasst. Insbesondere wird jedes Bild im img_dict-Wörterbuch katalogisiert, das den Pfad des Bildes zusammen mit dem Satz generierter Labels aufzeichnet und so ein zugängliches Datenrepository für nachfolgende Analysen sicherstellt.
\ Nach dem Tagging des Eingabebildes mit generierten Labels schreitet der Workflow fort, indem das Grounding DINO Modell [25] aufgerufen wird. Dieses Modell ist darauf spezialisiert, Textphrasen mit spezifischen Regionen innerhalb eines Bildes zu verbinden und Zielobjekte effektiv mit Begrenzungsrahmen abzugrenzen. Dieser Prozess identifiziert und lokalisiert Objekte räumlich innerhalb des Bildes und legt damit den Grundstein für detailliertere Analysen. Nach der Identifizierung und Lokalisierung von Objekten über Begrenzungsrahmen wird das Segment Anything Model (SAM) [21] eingesetzt. Die Hauptfunktion des SAM-Modells besteht darin, Segmentierungsmasken für die Objekte innerhalb dieser Begrenzungsrahmen zu generieren. Dadurch isoliert SAM einzelne Objekte und ermöglicht eine detailliertere und objektspezifische Analyse, indem es die Objekte effektiv von ihrem Hintergrund und voneinander innerhalb des Bildes trennt.
\ An diesem Punkt wurden Instanzen von Objekten identifiziert, lokalisiert und isoliert. Jedes Objekt wird mit verschiedenen Details identifiziert, einschließlich der Koordinaten des Begrenzungsrahmens, eines beschreibenden Begriffs für das Objekt, der Wahrscheinlichkeit oder des Konfidenzwerts für die Existenz des Objekts, ausgedrückt in Logits, und der Segmentierungsmaske. Darüber hinaus ist jedes Objekt mit CLIP- und DINOv2-Embedding-Merkmalen verbunden, deren Details im folgenden Unterabschnitt erläutert werden.
\ 3.2.2. Die semantische Embedding-Extraktion
\ Um unser Verständnis der semantischen Aspekte von Objektinstanzen zu verbessern, die in unseren Bildern segmentiert und maskiert wurden, verwenden wir zwei Modelle, CLIP [9] und DINOv2 [10], um die Merkmalsdarstellungen aus den zugeschnittenen Bildern jedes Objekts abzuleiten. Ein ausschließlich mit CLIP trainiertes Modell erreicht ein robustes semantisches Verständnis von Bildern, kann jedoch keine Tiefe und komplexe Details innerhalb dieser Bilder erkennen. Andererseits zeigt DINOv2 überlegene Leistung bei der Tiefenwahrnehmung und zeichnet sich bei der Identifizierung nuancierter Pixel-Level-Beziehungen über Bilder hinweg aus. Als selbstüberwachter Vision Transformer kann DINOv2 nuancierte Merkmalsdetails extrahieren, ohne sich auf annotierte Daten zu verlassen, was es besonders effektiv bei der Identifizierung räumlicher Beziehungen und Hierarchien innerhalb von Bildern macht. Während das CLIP-Modell beispielsweise Schwierigkeiten haben könnte, zwischen zwei Stühlen unterschiedlicher Farben, wie rot und grün, zu unterscheiden, ermöglichen die Fähigkeiten von DINOv2 solche Unterscheidungen klar zu treffen. Zusammenfassend erfassen diese Modelle sowohl die semantischen als auch die visuellen Merkmale der Objekte, die später für Ähnlichkeitsvergleiche im 3D-Raum verwendet werden.
\ 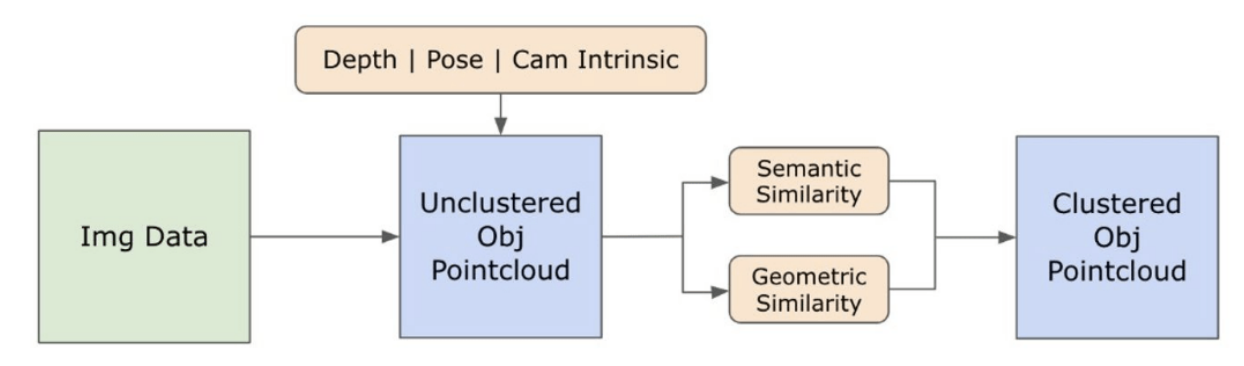
\ Eine Reihe von Vorverarbeitungsschritten wird für die Verarbeitung von Bildern mit dem DINOv2-Modell implementiert. Dazu gehören das Ändern der Größe, das Zuschneiden der Mitte, das Umwandeln des Bildes in einen Tensor und das Normalisieren der zugeschnittenen Bilder, die durch die Begrenzungsrahmen abgegrenzt sind. Das verarbeitete Bild wird dann zusammen mit den vom RAM-Modell identifizierten Labels in das DINOv2-Modell eingespeist, um die DINOv2-Embedding-Merkmale zu generieren. Bei der Arbeit mit dem CLIP-Modell hingegen beinhaltet der Vorverarbeitungsschritt die Umwandlung des zugeschnittenen Bildes in ein mit CLIP kompatibles Tensorformat, gefolgt von der Berechnung der Embedding-Merkmale. Diese Embeddings sind entscheidend, da sie die visuellen und semantischen Attribute der Objekte erfassen, die für ein umfassendes Verständnis der Objekte in der Szene entscheidend sind. Diese Embeddings werden basierend auf ihrer L2-Norm normalisiert, was den Merkmalsvektor auf eine standardisierte Einheitslänge anpasst. Dieser Normalisierungsschritt ermöglicht konsistente und faire Vergleiche zwischen verschiedenen Bildern.
\ In der Implementierungsphase dieser Stufe iterieren wir über jedes Bild innerhalb unserer Daten und führen die folgenden Verfahren aus:
\ (1) Das Bild wird auf den Interessenbereich zugeschnitten, wobei die vom Grounding DINO-Modell bereitgestellten Koordinaten des Begrenzungsrahmens verwendet werden, um das Objekt für eine detaillierte Analyse zu isolieren.
\ (2) Generieren von DINOv2- und CLIP-Embeddings für das zugeschnittene Bild.
\ (3) Schließlich werden die Embeddings zusammen mit den Masken aus dem vorherigen Abschnitt zurückgespeichert.
\ Mit diesen abgeschlossenen Schritten verfügen wir nun über detaillierte Merkmalsdarstellungen für jedes Objekt, die unseren Datensatz für weitere Analysen und Anwendungen bereichern.
\
:::info Autoren:
(1) Laksh Nanwani, International Institute of Information Technology, Hyderabad, Indien; dieser Autor hat gleichermaßen zu dieser Arbeit beigetragen;
(2) Kumaraditya Gupta, International Institute of Information Technology, Hyderabad, Indien;
(3) Aditya Mathur, International Institute of Information Technology, Hyderabad, Indien; dieser Autor hat gleichermaßen zu dieser Arbeit beigetragen;
(4) Swayam Agrawal, International Institute of Information Technology, Hyderabad, Indien;
(5) A.H. Abdul Hafez, Hasan Kalyoncu University, Sahinbey, Gaziantep, Türkei;
(6) K. Madhava Krishna, International Institute of Information Technology, Hyderabad, Indien.
:::
:::info Dieses Paper ist auf arxiv verfügbar unter der CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International) Lizenz.
:::
\
Das könnte Ihnen auch gefallen

"Wünsche Nicolas alles Gute": FC Bayern muss wochenlang auf Stürmer verzichten

Ein weiteres an der Nasdaq notiertes Unternehmen kündigt massiven Bitcoin (BTC)-Kauf an! Wird zum 14. größten Unternehmen! – Sie werden auch in Trump-verbundene Altcoin investieren!
