

Battre le fine-tuning complet avec seulement 0,2 % des paramètres
Table des liens
Résumé et 1. Introduction
-
Contexte
2.1 Mélange d'experts
2.2 Adaptateurs
-
Mélange d'adaptations
3.1 Politique de routage
3.2 Régularisation de cohérence
3.3 Fusion de modules d'adaptation et 3.4 Partage de modules d'adaptation
3.5 Connexion aux réseaux neuronaux bayésiens et à l'ensemble de modèles
-
Expériences
4.1 Configuration expérimentale
4.2 Résultats clés
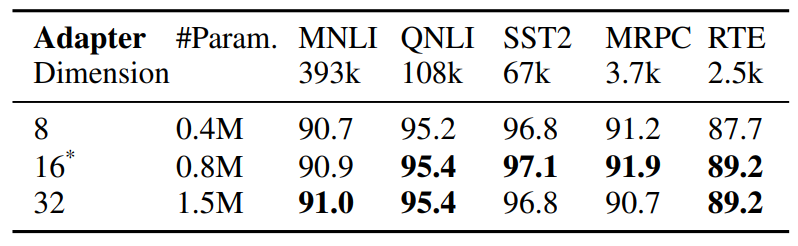
4.3 Étude d'ablation
-
Travaux connexes
-
Conclusions
-
Limitations
-
Remerciements et références
Annexe
A. Ensembles de données NLU à quelques exemples B. Étude d'ablation C. Résultats détaillés sur les tâches NLU D. Hyper-paramètre
5 Travaux connexes
Réglage fin efficace en paramètres des PLM. Les travaux récents sur le réglage fin efficace en paramètres (PEFT) peuvent être grossièrement classés en deux
\ 
\ catégories : (1) réglage d'un sous-ensemble de paramètres existants, y compris le réglage fin de la tête (Lee et al., 2019), réglage des termes de biais (Zaken et al., 2021), (2) réglage de paramètres nouvellement introduits, y compris les adaptateurs (Houlsby et al., 2019; Pfeiffer et al., 2020), prompt-tuning (Lester et al., 2021), prefixtuning (Li et Liang, 2021) et adaptation de rang faible (Hu et al., 2021). Contrairement aux travaux antérieurs opérant sur un seul module d'adaptation, AdaMix introduit un mélange de modules d'adaptation avec un routage stochastique pendant l'entraînement et une fusion de modules d'adaptation pendant l'inférence pour maintenir le même coût de calcul qu'avec un seul module. De plus, AdaMix peut être utilisé sur n'importe quelle méthode PEFT pour améliorer davantage ses performances.
\ Mélange d'experts (MoE). Shazeer et al., 2017 ont introduit le modèle MoE avec un seul réseau de passerelle avec routage Top-k et équilibrage de charge entre experts. Fedus et al., 2021 proposent des schémas d'initialisation et d'entraînement pour le routage Top-1. Zuo et al., 2021 proposent une régularisation de cohérence pour le routage aléatoire ; Yang et al., 2021 proposent un routage k Top-1 avec des prototypes d'experts, et Roller et al., 2021 ; Lewis et al., 2021 abordent d'autres problèmes d'équilibrage de charge. Tous les travaux ci-dessus étudient le MoE sparse avec pré-entraînement du modèle entier à partir de zéro. En revanche, nous étudions l'adaptation efficace en paramètres des modèles de langage pré-entraînés en réglant uniquement un très petit nombre de paramètres d'adaptateurs épars.
\ Moyenne des poids de modèle. Des explorations récentes (Szegedy et al., 2016 ; Matena et Raffel, 2021 ; Wortsman et al., 2022 ; Izmailov et al., 2018) étudient l'agrégation de modèles en moyennant tous les poids du modèle. (Matena et Raffel, 2021) proposent de fusionner des modèles de langage pré-entraînés qui sont affinés sur diverses tâches de classification de texte. (Wortsman et al., 2022) explore la moyenne des poids de modèle à partir de diverses exécutions indépendantes sur la même tâche avec différentes configurations d'hyper-paramètres. Contrairement aux travaux ci-dessus sur le réglage fin du modèle complet, nous nous concentrons sur le réglage fin efficace en paramètres. Nous explorons la moyenne des poids pour fusionner les poids des modules d'adaptation composés de petits paramètres réglables qui sont mis à jour pendant le réglage du modèle tout en gardant les grands paramètres du modèle fixes.
6 Conclusions
Nous développons un nouveau cadre AdaMix pour le réglage fin efficace en paramètres (PEFT) des grands modèles de langage pré-entraînés (PLM). AdaMix exploite un mélange de modules d'adaptation pour améliorer les performances des tâches en aval sans augmenter le coût de calcul (par exemple, FLOPs, paramètres) de la méthode d'adaptation sous-jacente. Nous démontrons qu'AdaMix fonctionne avec et améliore différentes méthodes PEFT comme les adaptateurs et les décompositions de rang faible à travers les tâches NLU et NLG.
\ En réglant seulement 0,1 − 0,2% des paramètres PLM, AdaMix surpasse le réglage fin du modèle complet qui met à jour tous les paramètres du modèle ainsi que d'autres méthodes PEFT de pointe.
7 Limitations
La méthode AdaMix proposée est quelque peu intensive en calcul car elle implique le réglage fin de modèles de langage à grande échelle. Le coût d'entraînement de l'AdaMix proposé est plus élevé que les méthodes PEFT standard puisque la procédure d'entraînement implique plusieurs copies d'adaptateurs. Selon nos observations empiriques, le nombre d'itérations d'entraînement pour AdaMix est généralement entre 1∼2 fois l'entraînement pour les méthodes PEFT standard. Cela impose un impact négatif sur l'empreinte carbone de l'entraînement des modèles décrits.
\ AdaMix est orthogonal à la plupart des études existantes sur le réglage fin efficace en paramètres (PEFT) et est capable d'améliorer potentiellement les performances de n'importe quelle méthode PEFT. Dans ce travail, nous explorons deux méthodes PEFT représentatives comme l'adaptateur et LoRA, mais nous n'avons pas expérimenté avec d'autres combinaisons comme le prompt-tuning et le prefix-tuning. Nous laissons ces études pour des travaux futurs.
8 Remerciements
Les auteurs tiennent à remercier les arbitres anonymes pour leurs précieux commentaires et suggestions utiles et souhaitent remercier Guoqing Zheng et Ruya Kang pour leurs commentaires perspicaces sur le projet. Ce travail est soutenu en partie par la Fondation nationale des sciences des États-Unis sous les subventions NSFIIS 1747614 et NSF-IIS-2141037. Toutes les opinions, constatations et conclusions ou recommandations exprimées dans ce document sont celles de l'auteur ou des auteurs et ne reflètent pas nécessairement les vues de la Fondation nationale des sciences.
Références
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. 2021. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7319– 7328, Online. Association for Computational Linguistics.
\ Roy Bar Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. 2006. The second PASCAL recognising textual entailment challenge.
\ Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. 2009. The fifth PASCAL recognizing textual entailment challenge. In TAC.
\ Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel HerbertVoss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
\ Ido Dagan, Oren Glickman, and Bernardo Magnini. 2005. The PASCAL recognising textual entailment challenge. In the First International Conference on Machine Learning Challenges: Evaluating Predictive Uncertainty Visual Object Classification, and Recognizing Textual Entailment.
\ Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Volume 1 (Long and Short Papers), pages 4171–4186.
\ William Fedus, Barret Zoph, and Noam Shazeer. 2021. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv preprint arXiv:2101.03961.
\ Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. 2020. Linear mode connectivity and the lottery ticket hypothesis. In International Conference on Machine Learning, pages 3259–3269. PMLR.
\ Yarin Gal and Zoubin Ghahramani. 2015. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. CoRR, abs/1506.02142.
\ Yarin Gal, Riashat Islam, and Zoubin Ghahramani. 2017. Deep Bayesian active learning with image data. In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1183–1192. PMLR.
\ Tianyu Gao, Adam Fisch, and Danqi Chen. 2021. Making pre-trained language models better few-shot learners. In Association for Computational Linguistics (ACL).
\ Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. 2017. The webnlg challenge: Generating text from rdf data. In Proceedings of the 10th International Conference on Natural Language Generation, pages 124–133.
\ Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and Bill Dolan. 2007. The third PASCAL recognizing textual entailment challenge. In the ACLPASCAL Workshop on Textual Entailment and Paraphrasing.
\ Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR.
\ Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
\ Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. 2018. Averaging weights leads to wider optima and better generalization. arXiv preprint arXiv:1803.05407.
\ Jaejun Lee, Raphael Tang, and Jimmy Lin. 2019. What would elsa do? freezing layers during transformer fine-tuning. arXiv preprint arXiv:1911.03090.
\ Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2020. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668.
\ Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. CoRR, abs/2104.08691.
\ Mike Lewis, Shruti Bhosale, Tim Dettmers, Naman Goyal, and Luke Zettlemoyer. 2021. Base layers: Simplifying training of large, sparse models. In ICML.
\ Xiang Lisa Li and Percy Liang. 2021. Pref
Vous aimerez peut-être aussi

NEAR se prépare-t-il pour un Breakout discret vers 2026 ?

Joshua Wallace affronte les défis de la criminalité moderne avec un leadership fondé sur des valeurs
