

Détection d'anomalies basée sur les transformers utilisant des embeddings de séquences de logs
Table des liens
Abstrait
1 Introduction
2 Contexte et travaux connexes
2.1 Différentes formulations de la tâche de détection d'anomalies basée sur les logs
2.2 Supervisé contre non supervisé
2.3 Informations dans les données de logs
2.4 Regroupement à fenêtre fixe
2.5 Travaux connexes
3 Une approche configurable de détection d'anomalies basée sur les transformers
3.1 Formulation du problème
3.2 Analyse et intégration des logs
3.3 Encodage positionnel et temporel
3.4 Structure du modèle
3.5 Classification binaire supervisée
4 Configuration expérimentale
4.1 Ensembles de données
4.2 Métriques d'évaluation
4.3 Génération de séquences de logs de longueurs variables
4.4 Détails d'implémentation et environnement expérimental
5 Résultats expérimentaux
5.1 RQ1: Comment notre modèle de détection d'anomalies proposé se comporte-t-il par rapport aux références?
5.2 RQ2: Dans quelle mesure les informations séquentielles et temporelles au sein des séquences de logs affectent-elles la détection d'anomalies?
5.3 RQ3: Dans quelle mesure les différents types d'informations contribuent-ils individuellement à la détection d'anomalies?
6 Discussion
7 Menaces à la validité
8 Conclusions et références
\
3 Une approche configurable de détection d'anomalies basée sur les transformers
Dans cette étude, nous présentons une nouvelle méthode basée sur les transformers pour la détection d'anomalies. Le modèle prend des séquences de logs comme entrées pour détecter les anomalies. Le modèle utilise un modèle BERT préentraîné pour intégrer les modèles de logs, permettant la représentation d'informations sémantiques dans les messages de logs. Ces intégrations, combinées à un encodage positionnel ou temporel, sont ensuite introduites dans le modèle transformer. Les informations combinées sont utilisées dans la génération ultérieure de représentations au niveau des séquences de logs, facilitant le processus de détection d'anomalies. Nous concevons notre modèle pour qu'il soit flexible: les caractéristiques d'entrée sont configurables afin que nous puissions utiliser ou mener des expériences avec différentes combinaisons de caractéristiques des données de logs. De plus, le modèle est conçu et formé pour gérer des séquences de logs d'entrée de longueurs variables. Dans cette section, nous présentons notre formulation du problème et la conception détaillée de notre méthode.
\ 3.1 Formulation du problème
Nous suivons les travaux précédents [1] pour formuler la tâche comme une tâche de classification binaire, dans laquelle nous entraînons notre modèle proposé à classer les séquences de logs en anomalies et normales de manière supervisée. Pour les échantillons utilisés dans l'entraînement et l'évaluation du modèle, nous utilisons une approche de regroupement flexible pour générer des séquences de logs de longueurs variables. Les détails sont présentés dans la Section 4
\ 3.2 Analyse et intégration des logs
Dans notre travail, nous transformons les événements de logs en vecteurs numériques en encodant les modèles de logs avec un modèle de langage préentraîné. Pour obtenir les modèles de logs, nous adoptons l'analyseur Drain [24], qui est largement utilisé et offre de bonnes performances d'analyse sur la plupart des ensembles de données publics [4]. Nous utilisons un modèle sentence-bert préentraîné [25] (c'est-à-dire, all-MiniLML6-v2 [26]) pour intégrer les modèles de logs générés par le processus d'analyse des logs. Le modèle préentraîné est formé avec un objectif d'apprentissage contrastif et atteint des performances de pointe sur diverses tâches de NLP. Nous utilisons ce modèle préentraîné pour créer une représentation qui capture les informations sémantiques des messages de logs et illustre la similarité entre les modèles de logs pour le modèle de détection d'anomalies en aval. La dimension de sortie du modèle est de 384.
\ 3.3 Encodage positionnel et temporel
Le modèle transformer original [27] adopte un encodage positionnel pour permettre au modèle d'utiliser l'ordre de la séquence d'entrée. Comme le modèle ne contient ni récurrence ni convolution, les modèles seront agnostiques à la séquence de logs sans l'encodage positionnel. Bien que certaines études suggèrent que les modèles transformer sans encodage positionnel explicite restent compétitifs avec les modèles standard lors du traitement de données séquentielles [28, 29], il est important de noter que toute permutation de la séquence d'entrée produira le même état interne du modèle. Comme les informations séquentielles ou temporelles peuvent être des indicateurs importants d'anomalies dans les séquences de logs, les travaux précédents basés sur les modèles transformer utilisent l'encodage positionnel standard pour injecter l'ordre des événements de logs ou des modèles dans la séquence [11, 12, 21], visant à détecter les anomalies associées à un ordre d'exécution incorrect. Cependant, nous avons remarqué que dans une implémentation de réplication couramment utilisée d'une méthode basée sur transformer [5], l'encodage positionnel était, en fait, omis. À notre connaissance, aucun travail existant n'a encodé les informations temporelles basées sur les horodatages des logs pour leur méthode de détection d'anomalies. L'efficacité de l'utilisation d'informations séquentielles ou temporelles dans la tâche de détection d'anomalies n'est pas claire.
\ Dans notre méthode proposée, nous tentons d'incorporer l'encodage séquentiel et temporel dans le modèle transformer et d'explorer l'importance des informations séquentielles et temporelles pour la détection d'anomalies. Plus précisément, notre méthode proposée a différentes variantes utilisant les techniques d'encodage séquentiel ou temporel suivantes. L'encodage est ensuite ajouté à la représentation du log, qui sert d'entrée à la structure du transformer.
\ 
3.3.1 Encodage du temps écoulé relatif (RTEE)
Nous proposons cette méthode d'encodage temporel, RTEE, qui substitue simplement l'indice de position dans l'encodage positionnel par le timing de chaque événement de log. Nous calculons d'abord le temps écoulé selon les horodatages des événements de logs dans la séquence de logs. Au lieu d'utiliser l'indice de séquence d'événements de logs comme position pour les équations sinusoïdales et cosinusoïdales, nous utilisons le temps écoulé relatif au premier événement de log dans la séquence de logs pour substituer l'indice de position. Le Tableau 1 montre un exemple d'intervalles de temps dans une séquence de logs. Dans l'exemple, nous avons une séquence de logs contenant 7 événements avec une durée de 7 secondes. Le temps écoulé depuis le premier événement jusqu'à chaque événement de la séquence est utilisé pour calculer l'encodage temporel pour les événements correspondants. Similaire à l'encodage positionnel, l'encodage est calculé avec les équations 1 mentionnées ci-dessus, et l'encodage ne sera pas mis à jour pendant le processus d'entraînement.
\ 
3.4 Structure du modèle
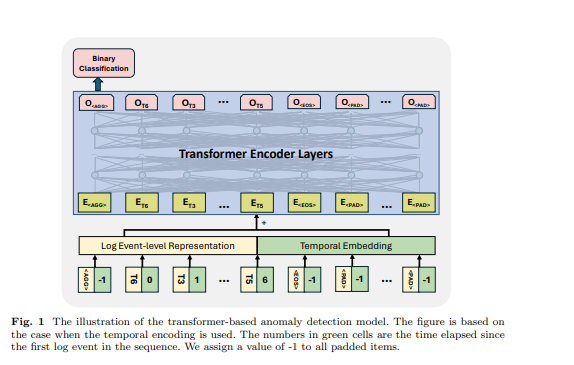
Le transformer est une architecture de réseau neuronal qui s'appuie sur le mécanisme d'auto-attention pour capturer la relation entre les éléments d'entrée dans une séquence. Les modèles et frameworks basés sur les transformers ont été utilisés dans la tâche de détection d'anomalies par de nombreux travaux précédents [6, 11, 12, 21]. Inspirés par les travaux précédents, nous utilisons un modèle basé sur l'encodeur transformer pour la détection d'anomalies. Nous concevons notre approche pour accepter des séquences de logs de longueurs variables et générer des représentations au niveau de la séquence. Pour y parvenir, nous avons employé certains tokens spécifiques dans la séquence de logs d'entrée pour que le modèle génère une représentation de séquence et identifie les tokens rembourrés et la fin de la séquence de logs, s'inspirant de la conception du modèle BERT [31]. Dans la séquence de logs d'entrée, nous avons utilisé les tokens suivants: est placé au début de chaque séquence pour permettre au modèle de générer des informations agrégées pour toute la séquence, est ajouté à la fin de la séquence pour signifier son achèvement, est utilisé pour marquer les tokens masqués sous le paradigme d'entraînement auto-supervisé, et est utilisé pour les tokens rembourrés. Les intégrations pour ces tokens spéciaux sont générées aléatoirement en fonction de la dimension de la représentation de log utilisée. Un exemple est montré dans la Figure 1, le temps écoulé pour , et est fixé à -1. La représentation au niveau de l'événement de log et l'intégration positionnelle ou temporelle sont additionnées comme caractéristique d'entrée de la structure du transformer.
\ 3.5 Classification binaire supervisée Sous cet objectif d'entraînement, nous utilisons la sortie du premier token du modèle transformer tout en ignorant les sorties des autres tokens. Cette sortie du premier token est conçue pour agréger les informations de toute la séquence de logs d'entrée, similaire au token du modèle BERT, qui fournit une représentation agrégée de la séquence de tokens. Par conséquent, nous considérons la sortie de ce token comme une représentation au niveau de la séquence. Nous entraînons le modèle avec un objectif de classification binaire (c'est-à-dire, la perte d'entropie croisée binaire) avec cette représentation.
\ 
:::info Auteurs:
- Xingfang Wu
- Heng Li
- Foutse Khomh
:::
:::info Cet article est disponible sur arxiv sous la licence CC by 4.0 Deed (Attribution 4.0 International).
:::
\


Vous aimerez peut-être aussi

Pas une faille : les contrôles à l'exportation de l'IA de Singapour permettent à la Chine d'accéder légalement à l'IA américaine

Futures perpétuels Bitcoin : Ratios Long/Short sur les principales bourses

Écosystème LAB Token : Plateforme de trading multi-chaînes et guide des récompenses


Actualités tendance
PlusActualités en direct 24h/24 et 7j/7
Plus
