

Why Your Phone's AI is Slow: A Story of Sparse Neurons and Finicky Flash Storage
Table of Links
Abstract and 1. Introduction
- Background and Motivation
- PowerInfer-2 Overview
- Neuron-Aware Runtime Inference
- Execution Plan Generation
- Implementation
- Evaluation
- Related Work
- Conclusion and References
2 Background and Motivation
2.1 LLM Inference and Metrics
LLM inference consists of two stages: the prefill and the decoding stage. During the prefill stage, the user’s prompt is processed by the LLM in a single iteration, generating the first token. The decoding stage, on the other hand, involves the LLM generating tokens sequentially, one at a time, in an autoregressive manner. The token produced during the prefill stage serves as the input for generating the second token. This second token then acts as the input for the LLM, facilitating the generation of the third word. This sequence continues until the output sequence is complete or an end-of-sequence (EOS) token is reached.
\ The two stages exhibit distinct computational patterns, necessitating the optimization of two key metrics: the time to first token (TTFT) during the prefill stage and the time between tokens (TBT) during the decoding stage. The prefill stage handles all prompt tokens within a single iteration, imposing a considerable computational burden; in contrast, the decoding stage processes only one token per iteration, resulting in comparatively lower computational demands. Consequently, an LLM inference system must leverage computing strategies designed for these stages specifically to optimize performance metrics efficiently.
\
2.2 Predictable Sparse Activations
Mainstream LLMs, such as GPT-4 and Llama-2, employ a decoder-only transformer architecture. This architecture consists of multiple transformer layers, with each layer containing an attention block and a Feed-Forward Network (FFN) block. The attention block establishes relationships between tokens in the sequence, while the FFN block interprets and processes these relationships as structured by the attention block. Recent LLMs usually adopt Group Query Attention [27], which reduces the number of weights in the attention block, making the feed-forward network (FFN) block occupy nearly 80% of the total weights. The activation function in the FFN block, such as ReLU-family functions [3, 28, 40], leads to a significant occurrence of sparse activations [19, 39]: most neurons (represented as rows or columns in the FFN weight matrix) are
\ 
\ inactivated because their computations have minimal impact on the final output.
\ Fortunately, the activation of neurons in the FFN can be predicted before computing each FFN block, that have been explored by prior works [21,29,30,40]. For instance, PowerInfer [30] and DejaVu [21] utilizes small MLP networks before each FFN block to predict their dynamic neuron activations. With these accurate predictors, they can significantly reduce the number of neuron computations within the FFN, thereby accelerating the inference process.
\
2.3 Smartphone Storage Analysis
A smartphone usually lacks sufficient DRAM memory to hold an entire LLM. Consequently, a portion of the model’s weights may be stored in external storage, such as the universal flash storage (UFS) 4.0 in Snapdragon 8gen3. In this section, we analyze the performance characteristics of smartphone UFS, which guide the I/O design of PowerInfer-2.
\ 2.3.1 Read Throughput and Block Size
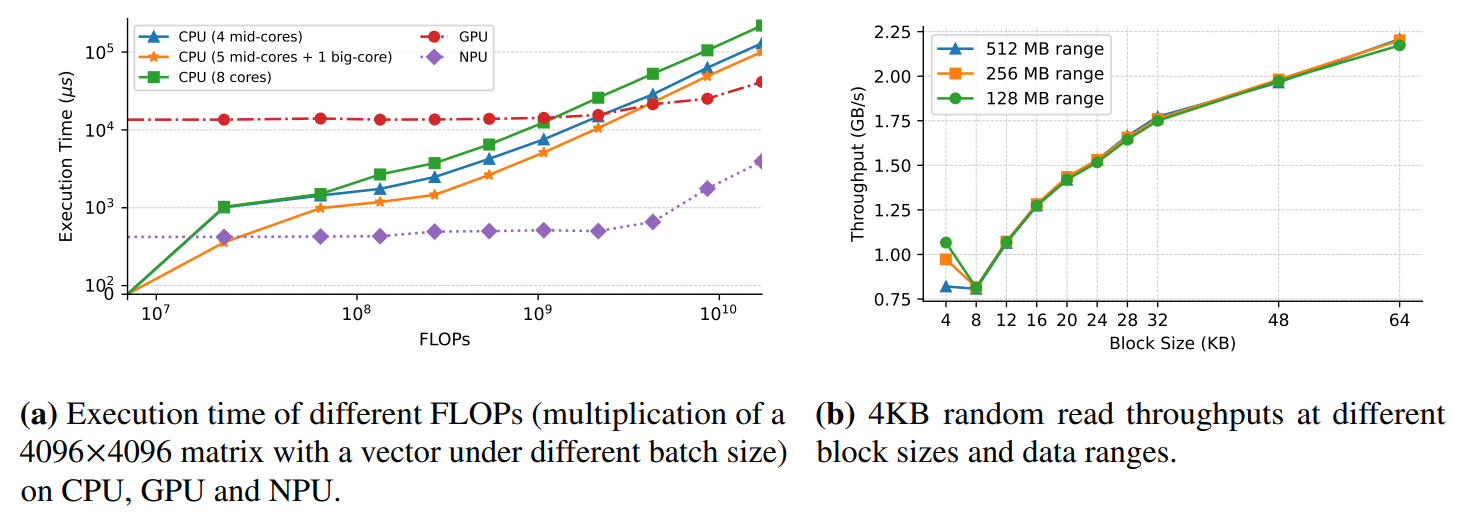
First, we evaluated the random and sequential read throughputs of UFS 4.0[1]. A notable feature is that the read bandwidth of UFS varies with the read block size. Generally, whether for sequential or random reads, the larger the block, the greater the read bandwidth. For example, when the block size is set to 512KB, both sequential and random read bandwidths reach their maximum at 4 GB/s and 3.5 GB/s, respectively. When the block size is reduced to 4KB, the bandwidth is at its minimum, with random read bandwidth at 450 MB/s.
\ 2.3.2 Random Read and Data Range
UFS random reads exhibit an interesting phenomenon where the performance of random reads is influenced by the scope of the random read range. Specifically, a smaller random read range results in higher bandwidth. In UFS 4.0, as shown in Fig.1b, if the 4KB random read range is set to 128MB, 256MB, and 512MB, the bandwidth for the 128MB range is the highest, reaching 1 GB/s, while the 512MB range has the lowest bandwidth, falling below 850 MB/s. Notably, this phenomenon is not as apparent with other block sizes. Therefore, the bandwidth of 4KB random reads within a 128MB range exceeds that of 8KB and 12KB block sizes.
\ 2.3.3 Read Throughput and CPU Core
A third observation is that the read bandwidth is influenced by the CPU issuing the read command. A higher frequency of the CPU core correlates with increased read bandwidth. As shown in Table 1, when using a big-core with a frequency of 3.3GHz for random reads, the bandwidth for 4KB reads reaches 1 GB/s. Conversely, when a little-core with a frequency of 2.2GHz is used for the same random reads, the bandwidth is only about 760 MB/s. This correlation arises because the CPU core initiating the read needs to run the UFS driver thus a higher frequency enables faster processing of UFS-related I/O operations, including interrupts and queue management.
\ 2.3.4 Read Throughput and Core Number
The last observation is that unlike NVMe, the UFS storage in mobile devices has only one command queue, inherently lacking internal concurrency capabilities. Therefore, initiating I/O commands using multiple cores does not result in higher I/O bandwidth compared to using a single core. As shown in Table 1, using multiple cores for 4KB random reads even deteriorates the I/O performance by up to 40% as a result of contention in the UFS command queue.
\ Summary: When some model weights need to be stored on a mobile device’s storage medium, an efficient LLM system must fully consider the performance characteristics of the storage medium to maximize I/O bandwidth and minimize the performance overhead associated with I/O operations.
\
:::info Authors:
(1) Zhenliang Xue, Co-first author from Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(2) Yixin Song, Co-first author from Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(3) Zeyu Mi, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University ([email protected]);
(4) Le Chen, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(5) Yubin Xia, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(6) Haibo Chen, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University.
:::
:::info This paper is available on arxiv under CC BY 4.0 license.
:::
[1] Since LLM inference involves only weight reading, we did not consider the performance of write operations


추천 콘텐츠
Bitcoin (BTC) Hovers Above $77K Amid Iran Diplomacy and Rising Treasury Yields

Beyond Cleaning: What Else You Must Check Before Moving Out




