

From "Decentralized" to "Unified": SUPCON Uses SeaTunnel to Build an Efficient Data Collection Frame
\
\
1. Dilemma: Siloed Collection Architecture and High Operation & Maintenance Costs
As an industrial AI platform company deeply empowering the process industry, SUPCON's global business has been continuously developing. Currently, it has nearly 40 global subsidiaries and serves more than 35,000 global customers. The continuous expansion of business has put forward higher requirements for data work: data not only needs to be "calculated quickly" but also "landed accurately". To this end, we have built a stream-batch separated big data platform to cope with complex scenarios. However, the complexity of the platform itself has conversely increased the difficulty of data collection, development, and operation & maintenance, especially in the source link of data collection, where we are facing severe challenges:
(1) Complex Architecture with Silos: In the past, we long relied on solutions composed of multiple tools (such as using Sqoop for batch data synchronization to HDFS, and Maxwell/StreamSets to process database incremental logs and write them to Kafka/Kudu). This "patchwork" architecture led to fragmented technology stacks and high maintenance costs.
(2) O&M Black Hole, Constantly Firefighting: Multiple technical routes mean double the pressure of operation and maintenance monitoring. The lack of a unified monitoring and alerting mechanism means that any abnormality (such as synchronization delays, resource exhaustion) requires a lot of manpower for troubleshooting and "firefighting", making it difficult to ensure stability.
(3) Segmented Capabilities, Difficult to Expand: When facing new data sources (such as domestic databases and SAP HANA), we need to find adaptation solutions in different tools or develop plug-ins independently, which makes it impossible to quickly respond to business needs.
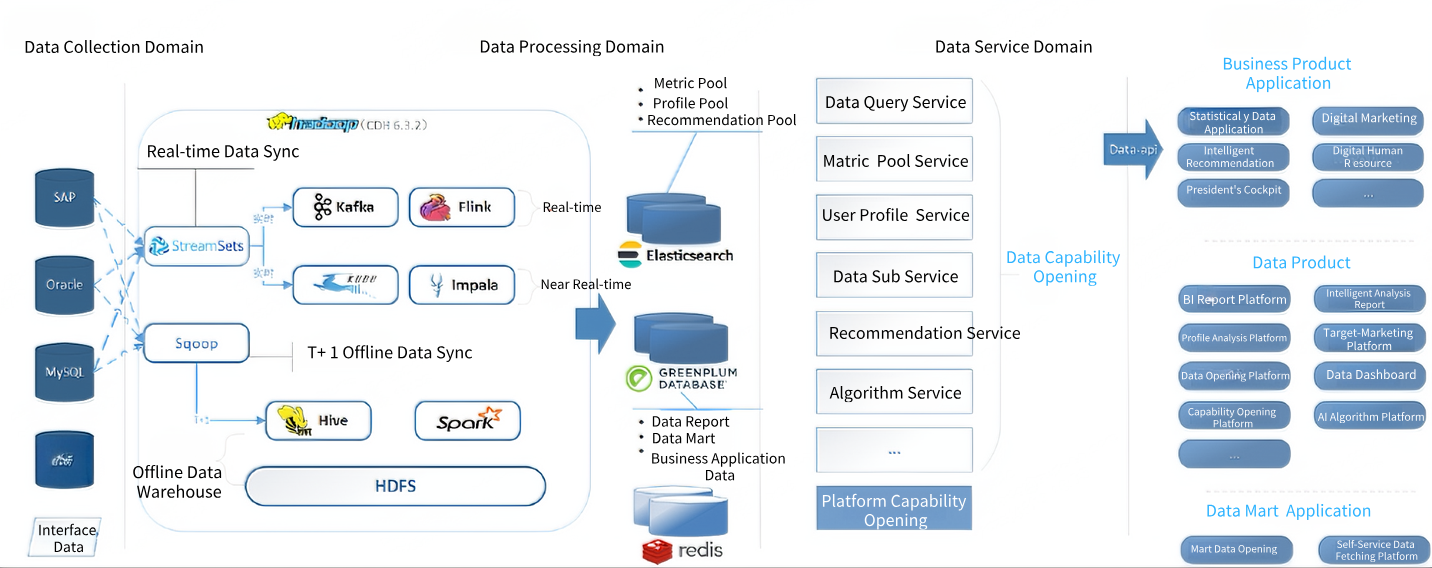
\ The above figure clearly shows the previously decentralized collection ecosystem. We realized that this "disorganized" model has become the most vulnerable link in data processing. It not only fails to match the company's future development speed but also poses potential threats to data quality and timeliness. Building a unified, stable, and efficient data collection framework has become crucial and urgent.
\
2. Breaking the Dilemma: Thoughts on a Unified Collection Framework and Technology Selection
After in-depth analysis and thinking, we have clarified the five core selection criteria for new technologies:
(1) Comprehensive Connectivity: It should fully cover all current and future data source types of the company (from MySQL, Oracle, HANA to Kafka, StarRocks, etc.) and support both offline and real-time collection modes, fundamentally solving the problem of unified technology stacks.
(2) Cluster Stability and High Availability: The framework itself must be a highly available distributed cluster with strong fault tolerance. Even if a single node fails, the entire service should not be interrupted and can recover automatically, ensuring the continuous operation of the data collection pipeline.
(3) Reliable Data Consistency Guarantee: At the task execution level, it must provide Exactly-Once or At-Least-Once processing semantics to ensure that tasks can automatically recover from breakpoints after abnormal interruptions, eliminating data duplication or loss, which is the cornerstone of data quality.
(4) Strong Throughput Performance: It must be able to easily cope with our daily TB-level data increment challenges. Its architecture should support horizontal expansion, and synchronization performance can be linearly improved by adding nodes to meet the data growth needs brought by the rapid development of business.
(5) Observable O&M Experience: It must provide a complete monitoring and alerting mechanism, which can track key indicators such as abnormalities, delays, and throughput during data synchronization in real time, and notify operation and maintenance personnel in a timely manner, transforming passive "firefighting" into active "early warning".
Based on these five criteria, we conducted in-depth research and comparative testing on mainstream solutions in the industry. Finally, Apache SeaTunnel performed excellently in all dimensions and became our optimal solution to break the dilemma.
| Our Core Requirements | Apache SeaTunnel's Solutions | |----|----| | Comprehensive Connectivity | It has an extremely rich Connector ecosystem, officially supporting the reading and writing of hundreds of source/destination databases, fully covering all our data types. A single framework can unify offline and real-time collection. | | Cluster Stability and High Availability | The separated architecture of SeaTunnel Engine ensures that even if a single Master or Worker node is abnormal, it will not affect the continuity of collection tasks. | | Reliable Data Consistency Guarantee | It provides a powerful fault tolerance mechanism, supports Exactly-Once semantics, and can realize automatic breakpoint resumption after task abnormalities through the Checkpoint mechanism, ensuring no data loss or duplication. | | Strong Throughput Performance | It has excellent distributed data processing capabilities. Parallelism can be adjusted through simple configuration, easily realizing horizontal expansion. | | Observable O&M Experience | It provides rich monitoring indicators and can be seamlessly integrated with mainstream monitoring and alerting systems such as Prometheus, Grafana, and AlertManager, allowing us to have a clear understanding of the data collection process. |
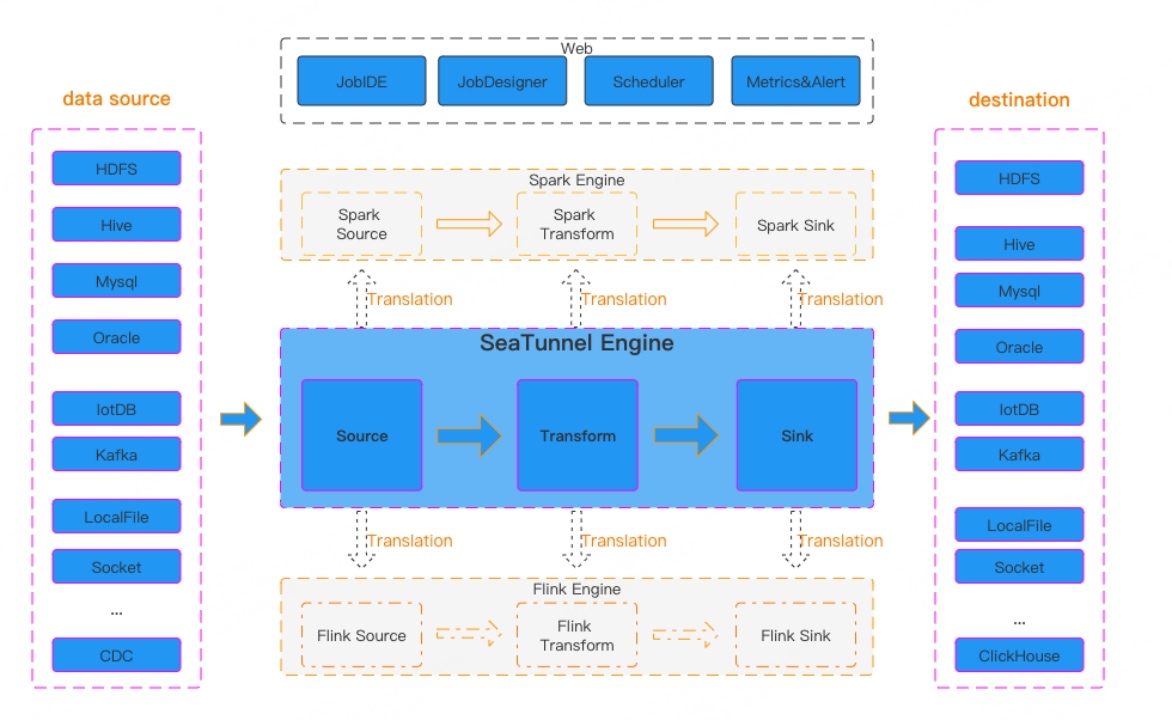
\
3. Practice: Specific Implementation Plans and Details
Our practice with Apache SeaTunnel is also the growth path of the project. In the early stage, we built based on Apache SeaTunnel v2.3.5. At that time, to meet some specific needs (such as handling case sensitivity issues of different database table names or field names), we carried out some secondary development work.
However, with the rapid development of the SeaTunnel community, the functions and converters of the new version have become increasingly complete. When we successfully upgraded the cluster to Apache SeaTunnel v2.3.11, we were pleasantly surprised to find that the needs that previously required customized development are now natively supported in the new version.
At present, all our data synchronization tasks are implemented based on the official version, achieving zero modification, which greatly reduces our long-term maintenance costs and allows us to seamlessly enjoy the latest functions and performance improvements brought by the community.
The following are our core implementation plans based on version v2.3.11, which have been verified by TB-level data volume in the production environment and laid a solid foundation for the excellent performance of 0 failures since the cluster was built.
\
(1) Cluster Planning
To ensure the high availability of the cluster, it is recommended to prioritize the deployment of a separate mode cluster. The following are the resources we use.
| Node | CPU | Memory | Disk | JVM Heap | |----|----|----|----|----| | Master-01 | 8C | 32G | 200G | 30G | | Master-02 | 8C | 32G | 200G | 30G | | Worker-01 | 16C | 64G | 500G | 62G | | Worker-02 | 16C | 64G | 500G | 62G | | Worker-03 | 16C | 64G | 500G | 62G |
\
(2) Key Cluster Configuration Files
-
seatunnel.yaml This configuration file is mainly used to define the execution behavior, fault tolerance mechanism, and operation and maintenance monitoring settings of jobs. It optimizes performance by enabling class loading caching and dynamic resource allocation, and ensures job fault tolerance and data consistency by configuring S3-based Checkpoints. In addition, it can enable indicator collection, log management, and settings, thereby providing comprehensive support for the stable operation, monitoring, and daily management of jobs.
\
seatunnel: engine: # Class loader cache mode: After enabling, it can significantly improve performance when jobs are frequently started and stopped, reducing class loading overhead. It is recommended to enable it in the production environment. classloader-cache-mode: true # Expiration time of historical job data (unit: minutes): 3 days. Historical information of completed jobs exceeding this time will be automatically cleaned up. history-job-expire-minutes: 4320 # Number of data backups backup-count: 1 # Queue type: Blocking queue queue-type: blockingqueue # Execution information printing interval (seconds): Print job execution information in the log every 60 seconds. print-execution-info-interval: 60 # Job metric information printing interval (seconds): Print detailed metric information in the log every 60 seconds. print-job-metrics-info-interval: 60 slot-service: # Dynamic Slot management: After enabling, the engine will dynamically allocate computing slots based on node resource conditions, improving resource utilization. dynamic-slot: true # Checkpoint configuration. checkpoint: interval: 60000 # Time interval between two Checkpoints, in milliseconds (ms). Here it is 1 minute. timeout: 600000 # Timeout for Checkpoint execution, in milliseconds (ms). Here it is 10 minutes. storage: type: hdfs # The storage type is declared as HDFS here, and the actual storage is in the S3 below. max-retained: 3 # Maximum number of Checkpoint histories to retain. Old Checkpoints will be automatically deleted to save space. plugin-config: storage.type: s3 # The actual configured storage type is S3 (or object storage compatible with S3 protocol such as MinIO) fs.s3a.access.key: xxxxxxx # Access Key of S3-compatible storage fs.s3a.secret.key: xxxxxxx # Secret Key of S3-compatible storage fs.s3a.endpoint: http://xxxxxxxx:8060 # Service endpoint (Endpoint) address of S3-compatible storage s3.bucket: s3a://seatunel-pro-bucket # Name of the bucket used to store Checkpoint data fs.s3a.aws.credentials.provider: org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider # Authentication credential provider # Observability configuration telemetry: metric: enabled: true # Enable metric collection logs: # Enable scheduled log deletion: Enable the automatic cleaning function of log files to prevent logs from filling up the disk. scheduled-deletion-enable: true # Web UI and REST API configuration http: enable-http: true # Enable Web UI and HTTP REST API services port: 8080 # Port number bound by the Web service enable-dynamic-port: false # Disable dynamic ports. Whether to enable other ports if 8080 is occupied. # The following is the Web UI basic authentication configuration enable-basic-auth: true # Enable basic identity authentication basic-auth-username: admin # Login username basic-auth-password: xxxxxxx # Login password \
-
jvmmasteroptions This JVM parameter configuration file is mainly used to ensure the stability and performance of the SeaTunnel engine during large-scale data processing. It provides basic memory guarantee by setting the heap memory and metaspace capacity, and conducts a series of optimizations specifically for the G1 garbage collector to effectively manage memory garbage, control garbage collection pause time, and improve operating efficiency.
\
# JVM heap memory -Xms30g -Xmx30g # Memory overflow diagnosis: Automatically generate a Heap Dump file when OOM occurs, and save it to the specified path for subsequent analysis. -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/seatunnel/dump/zeta-server # Metaspace: Limit the maximum capacity to 5GB to prevent metadata from expanding infinitely and occupying too much local memory. -XX:MaxMetaspaceSize=5g # G1 garbage collector related configuration -XX:+UseG1GC # Enable G1 garbage collector -XX:+PrintGCDetails # Print detailed GC information in the log -Xloggc:/path/to/gc.log # Output GC logs to the specified file -XX:+PrintGCDateStamps # Print timestamps in GC logs -XX:MaxGCPauseMillis=5000 # The target maximum GC pause time is 5000 milliseconds (5 seconds) -XX:InitiatingHeapOccupancyPercent=50 # Start concurrent GC cycle when heap memory usage reaches 50% -XX:+UseStringDeduplication # Enable string deduplication to save memory space -XX:GCTimeRatio=4 # Set the target ratio of GC time to application time -XX:G1ReservePercent=15 # Reserve 15% of heap memory -XX:ConcGCThreads=6 # Set the number of threads used in the concurrent GC phase to 6 -XX:G1HeapRegionSize=32m # Set the G1 region size to 32MB \
-
hazelcast-master.yaml (iMap stored in self-built object storage) This configuration file defines the underlying distributed architecture and collaboration mechanism of the SeaTunnel engine cluster. It is mainly used to establish and manage network communication between cluster nodes. The configuration also includes a high-precision failure detection heartbeat mechanism to ensure that node failure problems can be quickly detected and handled, ensuring the high availability of the cluster. At the same time, it enables distributed data persistence based on S3-compatible storage, reliably saving key state information to object storage.
\
hazelcast: cluster-name: seatunnel # Cluster name, which must be consistent across all nodes network: rest-api: enabled: true # Enable REST API endpoint-groups: CLUSTER_WRITE: enabled: true enabled: true join: tcp-ip: enabled: true # Use TCP/IP discovery mechanism member-list: # Cluster node list - 10.xx.xx.xxx:5801 - 10.xx.xx.xxx:5801 - 10.xx.xx.xxx:5802 - 10.xx.xx.xxx:5802 - 10.xx.xx.xxx:5802 port: auto-increment: false # Disable port auto-increment port: 5801 # Fixed port 5801 properties: hazelcast.invocation.max.retry.count: 20 # Maximum number of invocation retries hazelcast.tcp.join.port.try.count: 30 # Number of TCP connection port attempts hazelcast.logging.type: log4j2 # Use log4j2 logging framework hazelcast.operation.generic.thread.count: 50 # Number of generic operation threads hazelcast.heartbeat.failuredetector.type: phi-accrual # Use Phi-accrual failure detector hazelcast.heartbeat.interval.seconds: 2 # Heartbeat interval (seconds) hazelcast.max.no.heartbeat.seconds: 180 # No heartbeat timeout (seconds) hazelcast.heartbeat.phiaccrual.failuredetector.threshold: 10 # Failure detection threshold hazelcast.heartbeat.phiaccrual.failuredetector.sample.size: 200 # Detection sample size hazelcast.heartbeat.phiaccrual.failuredetector.min.std.dev.millis: 100 # Minimum standard deviation (milliseconds) hazelcast.operation.call.timeout.millis: 150000 # Operation call timeout (milliseconds) map: engine*: map-store: enabled: true # Enable Map storage persistence initial-mode: EAGER # Load all data immediately at startup factory-class-name: org.apache.seatunnel.engine.server.persistence.FileMapStoreFactory # Persistence factory class properties: type: hdfs # Storage type namespace: /seatunnel/imap # Namespace path clusterName: seatunnel-cluster # Cluster name storage.type: s3 # Actually use S3-compatible storage fs.s3a.access.key: xxxxxxxxxxxxxxxx # S3 access key fs.s3a.secret.key: xxxxxxxxxxxxxxxx # S3 secret key fs.s3a.endpoint: http://xxxxxxx:8060 # S3 endpoint address s3.bucket: s3a://seatunel-pro-bucket # S3 storage bucket name fs.s3a.aws.credentials.provider: org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider # Authentication provider \
(3) Collection Task Examples
① MySQL-CDC to StarRocks
To collect MySQL-CDC data, it is necessary to ensure that the source database has enabled Binlog with the format of ROW, the user has relevant permissions, and the corresponding MySQL Jar package is placed in the ${SEATUNNEL_HOME}/lib directory. For details, please refer to the official website: https://seatunnel.apache.org/docs/2.3.11/connector-v2/source/MySQL-CDC.
The following is a sample configuration for our MySQL-CDC collection.
env { parallelism = 1 # Parallelism is set to 1; only 1 is allowed for streaming collection job.mode = "STREAMING" # Streaming job mode job.name = cdh2sr # Job name identifier job.retry.times = 3 # Number of retries if the job fails job.retry.interval.seconds=180 # Retry interval (in seconds) } source { MySQL-CDC { base-url = "jdbc:mysql://xxxxxxx:3306/databasename" # MySQL connection address username = "xxxxxxr" # Database username password = "xxxxxx" # Database password table-names = ["databasename.table1","databasename_pro.table2"] # List of tables to sync (format: database.table name) startup.mode = "latest" # Start syncing from the latest position exactly_once = true # Enable Exactly-Once semantics debezium { include.schema.changes = "false" # Exclude schema changes snapshot.mode = when_needed # Take snapshots on demand } } } transform { TableRename { plugin_input = "cdc" # Input plugin identifier plugin_output = "rs" # Output plugin identifier convert_case = "LOWER" # Convert table names to lowercase prefix = "ods_cdh_databasename_" # Add prefix to table names } } sink { StarRocks { plugin_input = "rs" # Input plugin identifier (consistent with transform output) nodeUrls = ["xxxxxxx:8030","xxxxxxx:8030","xxxxxxx:8030"] # StarRocks FE node addresses base-url = "jdbc:mysql://xxxxxxx:3307" # StarRocks MySQL protocol address username = "xxxx" # StarRocks username password ="xxxxxxx" # StarRocks password database = "ods" # Target database enable_upsert_delete = true # Enable update/delete functionality max_retries = 3 # Number of retries if write fails http_socket_timeout_ms = 360000 # HTTP timeout (in milliseconds) retry_backoff_multiplier_ms = 2000 # Retry backoff multiplier max_retry_backoff_ms = 20000 # Maximum retry backoff time batch_max_rows = 2048 # Maximum number of rows per batch batch_max_bytes = 50000000 # Maximum bytes per batch } } \ ② Oracle-CDC to StarRocks
To collect Oracle-CDC data, ensure the source database has Logminer enabled, the user has relevant permissions, and place the corresponding OJDBC.Jar and Orai18n.jar packages in the ${SEATUNNEL_HOME}/lib directory. For details, refer to the official website: https://seatunnel.apache.org/docs/2.3.11/connector-v2/source/Oracle-CDC.
Notably, regarding latency issues encountered during Oracle-CDC collection, we recommend first asking the DBA to check how frequently Logminer logs are switched. The official recommendation is to keep it around 10 times per hour—too frequent switching may cause prolonged latency. If the frequency is too high, increase the size of individual log files. Second, consider splitting tables with extremely high QPS into new SeaTunnel tasks.
-- Query log switch frequency SELECT GROUP#, THREAD#, BYTES/1024/1024 || 'MB' "SIZE", ARCHIVED, STATUS FROM V$LOG; SELECT TO_CHAR(first_time, 'YYYY-MM-DD HH24') AS hour, COUNT(*) AS switch_count FROM v$log_history WHERE first_time >= TRUNC(SYSDATE) - 1 -- Data from the past day GROUP BY TO_CHAR(first_time, 'YYYY-MM-DD HH24') ORDER BY hour; -- Query log file size SELECT F.MEMBER, L.GROUP#, L.THREAD#, L.SEQUENCE#, L.BYTES/1024/1024 AS SIZE_MB, L.ARCHIVED, L.STATUS, L.FIRST_CHANGE#, L.NEXT_CHANGE# FROM V$LOG L, V$LOGFILE F WHERE F.GROUP# = L.GROUP# ORDER BY L.GROUP#; \ The following is a sample configuration for our Oracle-CDC collection.
env { parallelism = 1 # Parallelism is 1; only 1 is allowed for streaming collection job.mode = "STREAMING" # Streaming job mode job.name = bpm2sr # Job name identifier job.retry.times = 3 # Number of retries if the job fails job.retry.interval.seconds=180 # Retry interval (in seconds) } source { Oracle-CDC { plugin_output = "cdc" # Output plugin identifier base-url = "jdbc:oracle:thin:@xxxxxx:1521:DB" # Oracle connection address username = "xxxxxx" # Database username password = "xxxxxx" # Database password table-names = ["DB.SC.TABLE1","DB.SC.TABLE2"] # Tables to sync (format: database.schema.table name) startup.mode = "latest" # Start syncing from the latest position database-names = ["DB"] # Database name schema-names = ["SC"] # Schema name skip_analyze = true # Skip table analysis use_select_count = true # Use statistics exactly_once = true # Enable Exactly-Once semantics connection.pool.size = 20 # Connection pool size debezium { log.mining.strategy = "online_catalog" # Log mining strategy log.mining.continuous.mine = true # Continuously mine logs lob.enabled = false # Disable LOB support internal.log.mining.dml.parser ="legacy" # Use legacy DML parser } } } transform { TableRename { plugin_input = "cdc" # Input plugin identifier plugin_output = "rs" # Output plugin identifier convert_case = "LOWER" # Convert table names to lowercase prefix = "ods_crm_db_" # Add prefix to table names } } sink { StarRocks { plugin_input = "rs" # Input plugin identifier nodeUrls = ["xxxxxxx:8030","xxxxxxx:8030","xxxxxxx:8030"] # StarRocks FE nodes base-url = "jdbc:mysql://xxxxxxx:3307" # JDBC connection address username = "xxxx" # Username password ="xxxxxxx" # Password database = "ods" # Target database enable_upsert_delete = true # Enable update/delete max_retries = 3 # Maximum number of retries http_socket_timeout_ms = 360000 # HTTP timeout retry_backoff_multiplier_ms = 2000 # Retry backoff multiplier max_retry_backoff_ms = 20000 # Maximum retry backoff time batch_max_rows = 2048 # Maximum rows per batch batch_max_bytes = 50000000 # Maximum bytes per batch } } \
(4) Observable Monitoring
Thanks to the powerful monitoring metrics provided by the new version of SeaTunnel and the comprehensive monitoring system we built, we can fully grasp the status of the data collection platform from both the cluster-wide and task-level perspectives. Our monitoring system mainly includes the following two dimensions:
① Cluster Monitoring
-
Node status: Real-time monitoring of the number of cluster nodes and their survival status to ensure no abnormal offline of Worker nodes and guarantee cluster processing capabilities.
-
Cluster throughput: Monitor the overall SourceReceivedQPS and SinkWriteQPS of the cluster to grasp the global data inflow and outflow rates, and evaluate cluster load.
-
Resource status: Monitor the CPU and memory of cluster nodes to provide a basis for resource expansion or optimization.
-
Network health: Ensure good cluster network conditions by monitoring internal heartbeat and communication latency.
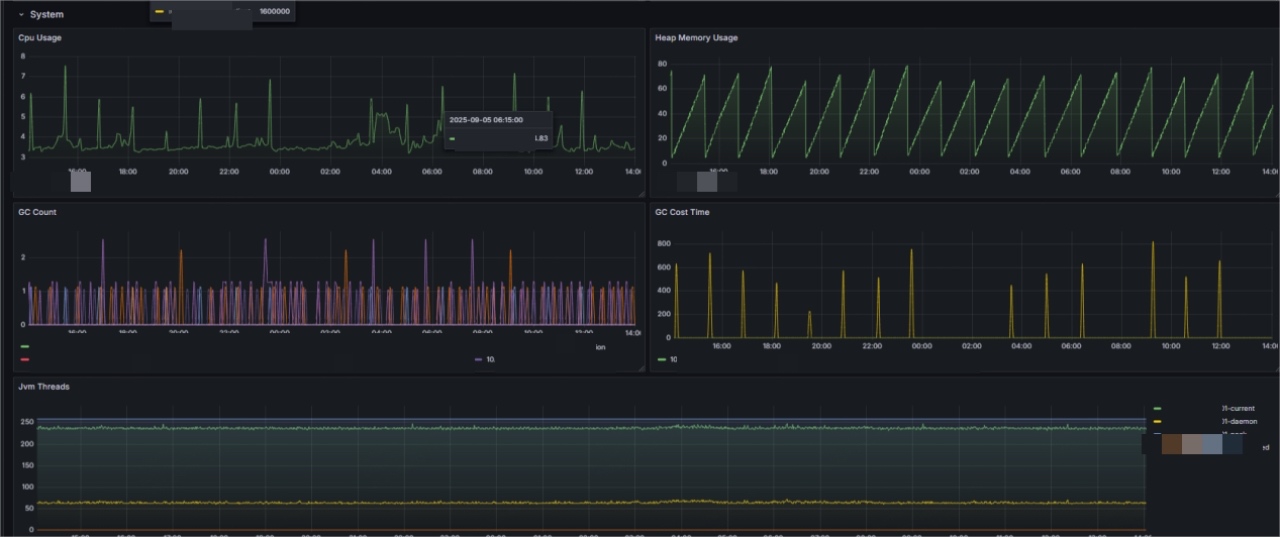
\ ② Task Monitoring
-
Task operation status: Real-time checking of the running status (Running/Failed/Finished) of all tasks is the most basic requirement of monitoring.
-
Data synchronization volume: Monitor the SourceReceivedCount and SinkWriteCount of each task to grasp the throughput of each data pipeline in real time.
-
Latency time: This is one of the most critical indicators for CDC tasks. Alerts are sent when continuous latency occurs at the collection end.
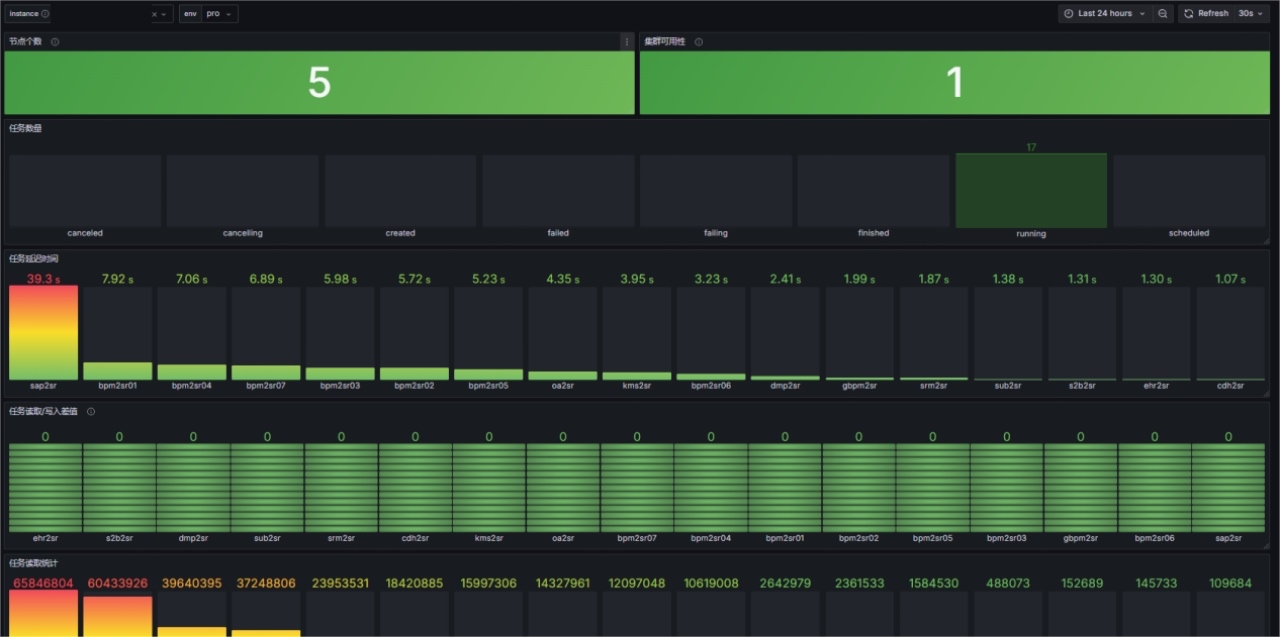
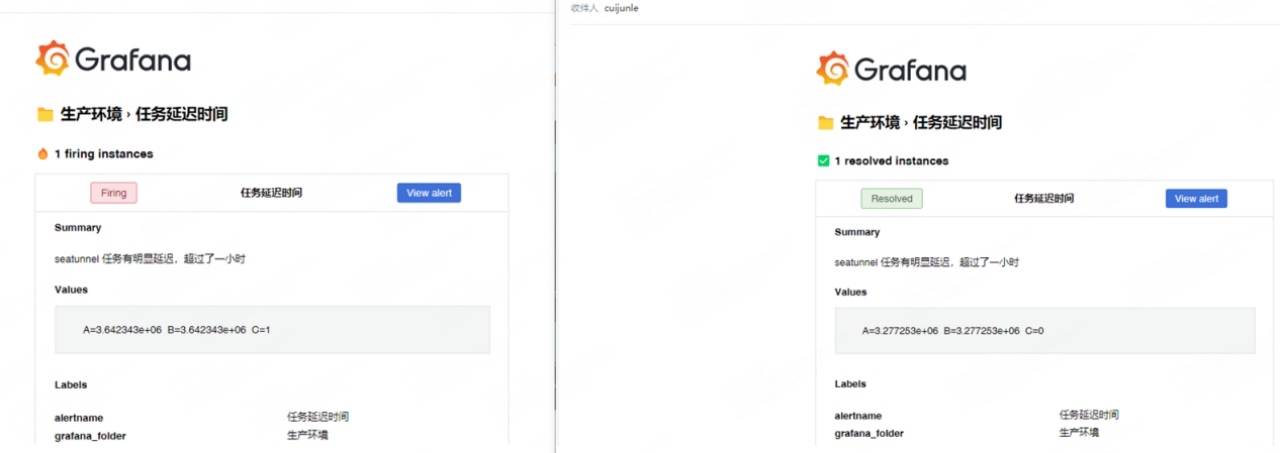
\
4. Results: Measurable Benefits
After a period of stable operation, the new-generation data collection framework built based on Apache SeaTunnel has brought us significant and quantifiable benefits, mainly reflected in the following aspects:
(1) Stability: From "Constant Firefighting" to "Peace of Mind"
-
Task failure rate reduced by over 99%: Under the old solution, 1-3 synchronization abnormalities needed to be handled per month. Since the new cluster was launched, core data synchronization tasks have maintained 0 failures, with no data service interruptions caused by the framework itself.
-
100% data consistency: Relying on Apache SeaTunnel's Exactly-Once semantics and powerful Checkpoint mechanism, end-to-end Exactly-Once processing is achieved, completely solving the problem of potential trace data duplication or loss and fundamentally ensuring data quality.
-
Significantly improved availability: The high-availability design of the cluster ensures 99.99% service availability. Any single-point failure can be automatically recovered within minutes, with no impact on business operations.
\
(2) Efficiency: Doubled Development and O&M Efficiency
-
50% improvement in development efficiency: From writing and maintaining multiple sets of scripts in the past to unified configuration-based development. The time to connect new data sources has been reduced from 1-2 person-days to within 1 minute, showing a significant efficiency improvement.
-
70% reduction in O&M costs: Now, the overall status can be monitored through the Grafana dashboard, with daily active O&M investment of less than 0.5 person-hours.
-
Optimized data timeliness: End-to-end data latency has been optimized from minutes to seconds, providing a solid foundation for real-time data analysis and decision-making.
\
(3) Architecture: Resource Optimization and Unified Framework
-
Unified technology stack: Successfully integrated multiple technology stacks such as Sqoop and StreamSets into Apache SeaTunnel, greatly reducing technical complexity and long-term maintenance costs.
\
5. Outlook: Future Plans
-
(1) Full cloud native adoption: We will actively explore the native deployment and scheduling capabilities of Apache SeaTunnel on Kubernetes, leveraging its elastic scaling features to achieve on-demand allocation of computing resources, further optimizing costs and efficiency, and better embracing hybrid cloud and multi-cloud strategies.
-
(2) Intelligent O&M: Build AIOps capabilities based on the rich Metrics data collected, realizing intelligent prediction of task performance, automatic root cause analysis of faults, and intelligent parameter tuning.
\
6. Acknowledgements
Here, we sincerely thank the Apache SeaTunnel open-source community. At the same time, we also thank every member of the internal project team of the company—your hard work and courage to explore are the keys to the successful implementation of this architecture upgrade. Finally, we sincerely wish the Apache SeaTunnel project a better future and a more prosperous ecosystem!
SUPCON dumped siloed data tools for Apache SeaTunnel—now core sync tasks run 0-failure! 🚀 99% lower failures, 100% consistency, 70% less O&M cost. Big thanks to @ApacheSeaTunnel! #DataEngineering #OpenSource


You May Also Like

Satoshi-Era Whale Challenges Michael Saylor With Sudden Bitcoin Move, XRP Hits Record 2026 Bollinger Bands Squeeze, Binance Delists Batch of BTC and ETH Pairs: Morning Crypto Report
Wildcoins Review – Get UPTO 3.5 BTC for Free




