

Model Promotion: Using EMA to Balance Learning and Forgetting in IIL
Table of Links
Abstract and 1 Introduction
-
Related works
-
Problem setting
-
Methodology
4.1. Decision boundary-aware distillation
4.2. Knowledge consolidation
-
Experimental results and 5.1. Experiment Setup
5.2. Comparison with SOTA methods
5.3. Ablation study
-
Conclusion and future work and References
\
Supplementary Material
- Details of the theoretical analysis on KCEMA mechanism in IIL
- Algorithm overview
- Dataset details
- Implementation details
- Visualization of dusted input images
- More experimental results
4.2. Knowledge consolidation
Different from existing IIL methods that only focus on the student model, we propose to consolidate knowledge from student to teacher for better balance between learning and forgetting. The consolidation is not implemented through learning but through model exponential moving average (EMA). Model EMA was initially introduced by Tarvainen et al. [28] to enhance the generalizability of models. In the vanilla model EMA, the model is trained from scratch, and EMA is applied after every iteration. The underlying mechanism of model EMA is not thoroughly explained before. In this work, we leverage model EMA for knowledge consolidation (KC) in the context of IIL task and explain the mechanism theoretically. According to our theoretical analysis, we propose a new KC-EMA for knowledge consolidation. Mathematically, the model EMA can be formulated as
\ 
\ Hence, the teacher model can achieve a minima training loss on both the old task and the new task, which indicates improved generalization on both the old data and new observations. This has been verified by our experiments in Sec. 5. However, since α < 1, it is noteworthy that the gradient of the teacher model, whether on the old task or the new task, is larger than the initial gradient on the old task or the final gradient of the student model on the new task. That is, the obtained teacher model sacrifices some unilateral performance on either the old data or the new data in order to achieve better generalization on both. From this perspective, the mechanism of vanilla EMA could also be partially explained. In vanilla EMA, where the model starts from scratch and only the new task is considered, we only need to focus on the second term in Equation 13. Since the teacher model has larger gradient on the training data than the student model, it is less possible to overfit to the training data. As a result, the teacher model has better generalization as Tarvainen et al. [28] observed.
\ 
\ 
\
:::info Authors:
(1) Qiang Nie, Hong Kong University of Science and Technology (Guangzhou);
(2) Weifu Fu, Tencent Youtu Lab;
(3) Yuhuan Lin, Tencent Youtu Lab;
(4) Jialin Li, Tencent Youtu Lab;
(5) Yifeng Zhou, Tencent Youtu Lab;
(6) Yong Liu, Tencent Youtu Lab;
(7) Qiang Nie, Hong Kong University of Science and Technology (Guangzhou);
(8) Chengjie Wang, Tencent Youtu Lab.
:::
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license.
:::
\


You May Also Like
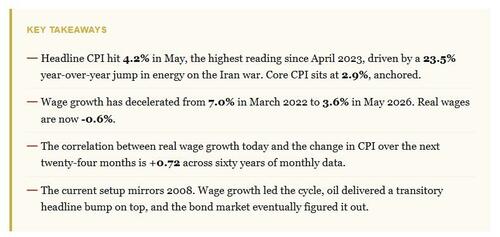
Wage Growth As A Leading Inflation Indicator

Retail Veteran Mitch Gould’s Distribution Platform Addresses Growing Complexity in U.S. Sports Nutrition Market

USA vs Belgium Odds: World Cup 2026 Win Probability and MEXC Prediction Market Guide



