

Ablation: The Role of Fused Labels and Teacher EMA in Instance-Incremental Learning
Table of Links
Abstract and 1 Introduction
-
Related works
-
Problem setting
-
Methodology
4.1. Decision boundary-aware distillation
4.2. Knowledge consolidation
-
Experimental results and 5.1. Experiment Setup
5.2. Comparison with SOTA methods
5.3. Ablation study
-
Conclusion and future work and References
\
Supplementary Material
- Details of the theoretical analysis on KCEMA mechanism in IIL
- Algorithm overview
- Dataset details
- Implementation details
- Visualization of dusted input images
- More experimental results
5.3. Ablation study
All ablation studies are implemented on Cifar-100 dataset.
\ 
\ 
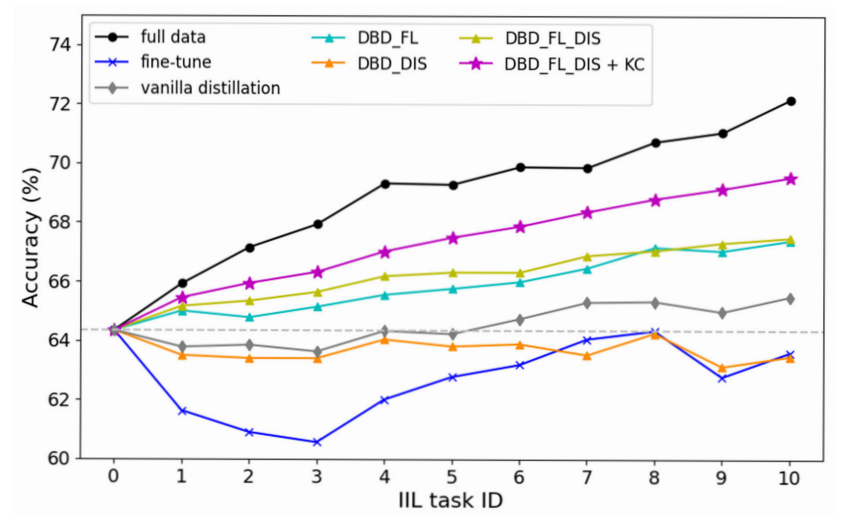
\ Effect of each component. The proposed method mainly consists of three components: DBD with fused label (FL), DBD with dusting the input space (DIS), and knowledge consolidation (KC). The ablation study on these three components is shown in Fig. 5. It can be seen that DBD with all components has the largest performance promotion in all phases. Although DBD with only DIS fails to enhance the model (which can be understood), it still shows great potential in resisting CF contrasted to fine-tuning with early stopping. The bad performance of fine-tuning also verifies our analysis that learning with one-hot label causes the decision boundary shifting to other than broadening to the new data. Different from previous distillation base on one-hot label, fused label well balances the need for retaining old knowledge and learning from new observation. Combining the boundary-aware distillation with knowledge consolidation, the model can better tame the knowledge learning and retaining problem with only new data. Consolidating the knowledge to teacher model during learning not only releases the student model in learning new knowledge, but also an effective way to avoid overfitting to new data.
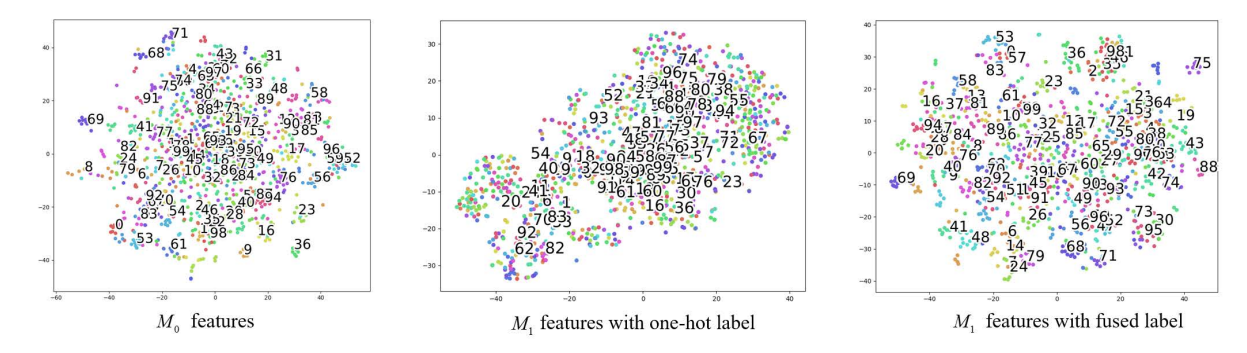
\ Impact of fused labels. In Sec. 4.1, the different learning demands for new outer samples and new inner samples in DBD are analyzed. We propose to use fused label for unifying knowledge retaining and learning on new data. Features learned in the first incremental phase with fused label and one-hot label are contrasted in Fig. 6. Learning with fused label not only retains most of the feature’s distribution but also has better separability (more dispersed) compared to the base model M0. While learning with one-hot label
\ ![Table 2. Results of incremental sub-population learning on Entity-30 benchmark. Unseen, All and Fi denote the average test accuracy on unseen subclasses in incremental data, on all seen (base data) and unseen subclasses, and the average forgetting rate over all test data. More details of the metrics can be found in ISL [13].](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-dg2329l.png)
\ 
\ changes the feature distribution into a elongated shape.
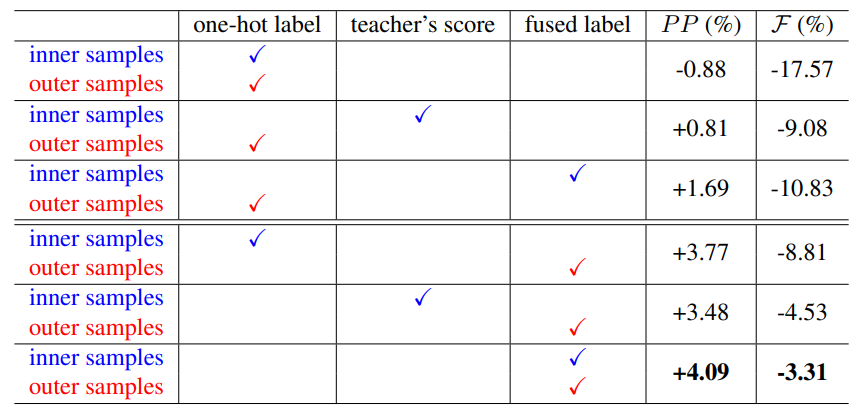
\ Tab. 3 shows the performance of student model when applying different learning target to the new inner samples and new outer samples, which reveals the influence of different labels in boundary distillation. As can be seen, utilizing one-hot label for learning new samples degrades the model with a large forgetting rate. Training the inner samples with teacher score and outer samples with one-hot labels is similar with existing rehearsal-based methods which distills knowledge using the teacher’s prediction on exemplars and learns from new data with annotated labels. Such a kind of manner reduces forgetting rate but benefits less in learning new. When applying fused labels to outer samples, the student model can well aware the existing DB and has much better performance. Notably, using the fused label for all new samples achieves the best performance. FL benefits retaining the old knowledge as well as enlarging the DB.
\ Impact of DIS. To locate and distill the learned decision boundary, we dust the input space with strong Gaussian noises as perturbations. The Gaussian noises are different from the one used in data augmentation because of its high deviation. In data augmentation, the image after strong augmentation should not change its label. However, there is no such limit in DIS. We hope to relocate inputs to
\ 
\ the peripheral area among classes other than keeping them in the same category as they are. In our experiments, the Gaussian noises in pixel intensity obey N(0, 10). Sensitivity to the noise intensity and related DIS loss are shown in Tab. 4. It can be seen that when noise intensity is small as used in data augmentation, the promotion is little considering the result of base model is 64.34%. Best result is attained when the deviation of noise δ = 10. When the noise intensity is too large, it might push all input images as outer samples and do no help in locating the decision boundary. Moreover, it will significantly alter the parameters of batch normalization layers in the network, which deteriorates the model. Visualization of the dusted input image can be found in our supplementary material. Different to noise intensity, the model is less sensitive to the DIS loss factor λ.
\ Impact of knowledge consolidation. It has been proved theoretically that consolidating the knowledge to teacher model is capable to achieve a model with better generalization on both of the old task and the new task. Fig. 7 left shows the model performance with and without the KC. No matter applied on the vanilla distillation method or the proposed DBD, the knowledge consolidation demonstrates great potential in accumulating knowledge from the student model and promoting the model’s performance. However, not all model EMA strategy can works. As shown in Fig. 7 right, traditional EMA that implements after every iteration fails to accumulate knowledge, where the teacher always performs inferior to the student. Too frequent EMA will cause the teacher model soon collapsed to the student
\ 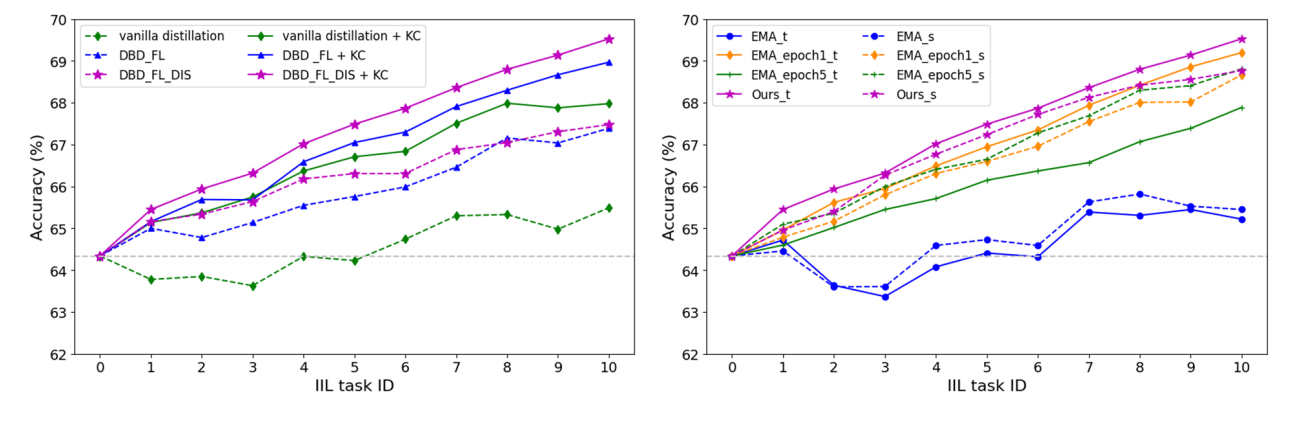
\ model, which causes forgetting problem and limits the following learning. Lowering the EMA frequency to every epoch (EMA epoch1) or every 5 epoch (EMA epoch5) performs better, which satisfies our theoretical analysis to keep total updating steps n properly small. Our KC-EMA which empirically performs EMA every 5 epoch with adaptive momentum attains the best result.
\
:::info Authors:
(1) Qiang Nie, Hong Kong University of Science and Technology (Guangzhou);
(2) Weifu Fu, Tencent Youtu Lab;
(3) Yuhuan Lin, Tencent Youtu Lab;
(4) Jialin Li, Tencent Youtu Lab;
(5) Yifeng Zhou, Tencent Youtu Lab;
(6) Yong Liu, Tencent Youtu Lab;
(7) Qiang Nie, Hong Kong University of Science and Technology (Guangzhou);
(8) Chengjie Wang, Tencent Youtu Lab.
:::
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license.
:::
\

You May Also Like

VivoPower To Load Up On XRP At 65% Discount: Here’s How

Today’s Wordle #1671 Hints And Answer For Thursday, January 15
