

Enhancing Long-Tailed Segmentation with Gradient Cache and BSGAL
Table of Links
Abstract and 1 Introduction
-
Related work
2.1. Generative Data Augmentation
2.2. Active Learning and Data Analysis
-
Preliminary
-
Our method
4.1. Estimation of Contribution in the Ideal Scenario
4.2. Batched Streaming Generative Active Learning
-
Experiments and 5.1. Offline Setting
5.2. Online Setting
-
Conclusion, Broader Impact, and References
\
A. Implementation Details
B. More ablations
C. Discussion
D. Visualization
Abstract
Recently, large-scale language-image generative models have gained widespread attention and many works have utilized generated data from these models to further enhance the performance of perception tasks. However, not all generated data can positively impact downstream models, and these methods do not thoroughly explore how to better select and utilize generated data. On the other hand, there is still a lack of research oriented towards active learning on generated data. In this paper, we explore how to perform active learning specifically for generated data in the long-tailed instance segmentation task. Subsequently, we propose BSGAL, a new algorithm that online estimates the contribution of the generated data based on gradient cache. BSGAL can handle unlimited generated data and complex downstream segmentation tasks effectively. Experiments show that BSGAL outperforms the baseline approach and effectually improves the performance of long-tailed segmentation. Our code can be found at https://github.com/aim-uofa/DiverGen.
1. Introduction
Data is one of the driving forces behind the development of artificial intelligence. In the past, securing high-quality data was a time-consuming and laborious task. Yet, a large amount of high-quality data is crucial for a model to achieve breakthrough performance. Therefore, many active learning methods have emerged to explore the most informative samples from massive unlabeled data to achieve better model performance with minimal annotation costs. Currently, the rapid development of generative models has made it possible to obtain massive amounts of high-quality data, including long-tailed data, at a relatively low cost. In the field of visual perception, there have been many works utilizing generated data to improve perception tasks, including classification (Azizi et al., 2023), detection (Chen et al., 2023), and segmentation (Wu et al., 2023b). However, they often directly use generated samples as mixed training data (Yang et al., 2023) or as data augmentation (Zhao et al., 2023) without exploring how to better filter and utilize the data for downstream models.
\ On the other hand, existing data mining and filtering methods, such as active learning, have only been validated on real data and are not suitable for generated data, as there are differences between generated data and real data regarding characteristics and usage scenarios. The differences are mainly as follows: 1) Existing data analysis methods are aimed at a limited data pool, while the scale of generated data is almost infinite. 2) Active learning is often carried out under a specified annotation budget. Thanks to the development of conditional generative models, the annotation cost of generated data can be almost negligible. However, this results in an unclear and uncertain quality of annotation in generated data compared to expert annotations. 3) There are differences in the distribution between real data and generated data, while the target data of previous methods do not have obvious distribution differences.
\ In response to the aforementioned challenges, we propose a novel problem called “Generative Active Learning for Long-tailed Instance Segmentation” (see Figure 1), which investigates how to utilize generated data effectively for downstream tasks. We focus on long-tailed instance segmentation for three main reasons. First, data collection for long-tailed categories is exceedingly arduous, and how to do classification well is currently a focus in the segmentation field (Kirillov et al., 2023; Li et al., 2023a; Yuan et al., 2024; Wei et al., 2024). Given that generated data has demonstrated the potential to alleviate this difficulty (Zhao et al., 2023; Xie et al., 2023; Fan et al., 2024), it is necessary to introduce generated data for long-tail segmentation tasks. Second, the quality requirements for generated data in longtailed instance segmentation tasks are very high, and not all generated data can have a promoting effect. Therefore, it is necessary to further explore how to screen generated data. Third, this task itself is very comprehensive and challenging, which has more guiding significance for migration to real-world scenarios.
\ 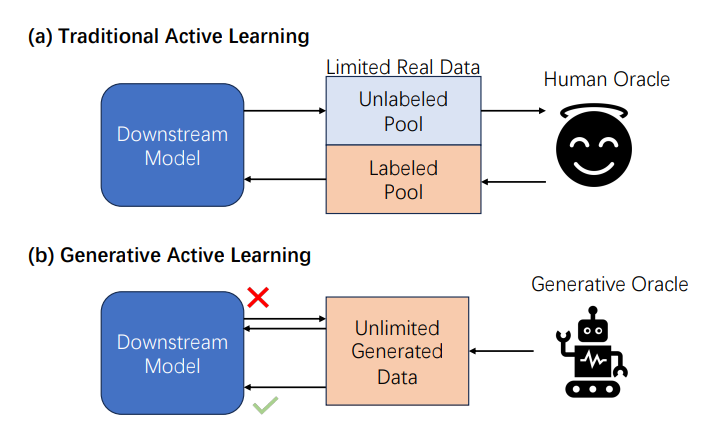
\ Here, our objective is to design a generative active learning pipeline targeted at long-tailed image segmentation tasks. Inspired by data-influence analysis methods (Ling, 1984; Koh and Liang, 2017), we first use the change of the loss value to provide an estimation of the contribution of a single generated instance in the ideal case, as discussed in Section 4.1. Employing the first-order Taylor expansion, we introduce an approximate contribution estimation function based on the gradient dot product, which avoids repeated calculations on the test set in the offline setting. Based on this technique, we conduct a toy experiment on CIFAR10 (Krizhevsky et al., 2009) in Section 5.1.1 along with a qualitative analysis of each sample on the LVIS dataset in Section 5.2.2, which preliminarily verify the feasibility of our approach. Subsequently, in Section 4.2 we explore how to apply this evaluation function to the actual segmentation training process. We propose the Batched Streaming Generative Active Learning algorithm (BSGAL), which allows for online acceptance or rejection of each batch of generated data. Additionally, based on the first-order gradient approximation, we maintain a gradient cache based on momentum updates to enable a more stable contribution estimation. Finally, experiments are carried out on the LVIS dataset, establishing that our method outperforms both unfiltered or CLIP-filtered counterparts under various backbones. Notably, in the long-tailed category, there is an over 10% improvement in APr (Gupta et al., 2019). In addition, We conduct a series of ablation experiments to delve into the particulars of our algorithmic design, including the choice of loss, the way of contribution estimation, and the sampling strategy of the test set. To summarize, our primary contributions are detailed below:
\ • We introduce a novel problem called “Generative Active Learning for Long-tailed Instance Segmentation”: how to design an effective method focused on the successful using generated data, aimed at enhancing the performance of downstream segmentation tasks. Existing data analysis methods are neither directly applicable to generated data nor have they been affirmed as efficient for such data.
\ • We propose a batched streaming generative active learning method (BSGAL) based on gradient cache to estimate generated data contribution. This pipeline can adapt to the actual batched segmentation training process, handle unlimited generative data online, and effectively enhance the performance of the model.
\ 
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license.
:::
\
:::info Authors:
(1) Muzhi Zhu, with equal contribution from Zhejiang University, China;
(2) Chengxiang Fan, with equal contribution from Zhejiang University, China;
(3) Hao Chen, Zhejiang University, China ([email protected]);
(4) Yang Liu, Zhejiang University, China;
(5) Weian Mao, Zhejiang University, China and The University of Adelaide, Australia;
(6) Xiaogang Xu, Zhejiang University, China;
(7) Chunhua Shen, Zhejiang University, China ([email protected]).
:::
\
You May Also Like

Shocking OpenVPP Partnership Claim Draws Urgent Scrutiny

Zano Surges 22% as Privacy Coins See Revival: Why ZANO is Trending Today

