

Metaplanet to Issue Class B Shares via Third-Party Allotment
Tokyo-listed Metaplanet Inc. has approved the issuance of newly created Class B shares through a third-party allotment, marking a major step in the company’s long-term capital strategy following its transition into a global Bitcoin treasury enterprise.
The issuance, scheduled for December 29, will provide the company with up to ¥21.2 billion (approx. $142 million) in new funds to accelerate its investment and Bitcoin acquisition programs.
The announcement was made following a board meeting on November 20, where directors also approved related amendments to capital and capital reserve allocations.
The company intends to expand its Bitcoin holdings and corporate value through a structured issuance designed to attract long-term institutional participation.
Issuance Details and Structure
The planned offering will consist of 23.61 million Class B shares at an issue price of ¥900 per share, for total proceeds of ¥21.249 billion. The shares will be allocated to designated investors under a third-party allotment framework.
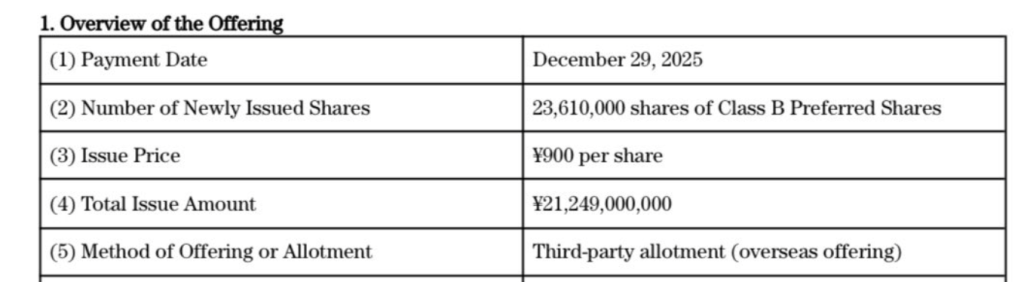
The company stressed that all payments must be completed by December 29, 2025, with shares issued through overseas settlement mechanisms.
The Class B structure—introduced to support Metaplanet’s transition into a Bitcoin-focused corporate strategy—provides differentiated rights that maintain alignment between long-term investors and the company’s Bitcoin-treasury objectives.
The issuance follows the expiration or cancellation of previously planned stock acquisition rights, including the 2025 EVO FUND-linked warrants, clearing the path for this new capital-raising initiative.
Strategic Rationale: Strengthening the Bitcoin Treasury Model
Since 2024, Metaplanet has redefined itself as a “Bitcoin treasury enterprise,” committing its corporate reserves to long-term Bitcoin accumulation. The company launched its “21 Million Plan” and subsequent “555 Million Plan,” reflecting its ambition to scale BTC holdings as a core asset.
Market volatility and external pressures, including shifts in global Bitcoin miner-linked equities, prompted the company to re-evaluate its capital structure. With the company’s MNAV (market value of Bitcoin-adjusted net asset value) fluctuating below parity at times, management determined that strengthening capital reserves was essential to protect shareholder value.
Metaplanet concluded that issuing preferred-like Class B shares—rather than relying on traditional debt or further dilution through common shares—was the most effective way to secure strategic funding, deepen the market’s understanding of its valuation model, and improve long-term price discovery.
Use of Proceeds and Future Outlook
Funds raised will be allocated toward the expansion of Bitcoin holdings, corporate investments, and broader Bitcoin infrastructure initiatives aligned with the company’s treasury strategy.
The issuance also prepares Metaplanet for a future public offering of Class B shares, with management noting that additional listing preparations will follow once market conditions are appropriate.
Metaplanet said the new capital will enable sustainable execution of its Bitcoin acquisition strategy, enhance financial stability, and position the company for long-term growth in Japan and global markets.


You May Also Like

Here’s why bitcoin’s drop below $68,000 raises the risk of a crash under $60,000
Bitcoin (BTC) Steady at $65K as BlackRock Reveals $9 Trillion Capital Shift Coming

Placeholder Partner Chris Burniske Begins Buying, Calls October a ‘Critical Turning Point’ for Crypto



