

Make Your Data Pipelines 5X Faster with Adaptive Batching
Do you have massive LLM calls in your data transformation flow?
CocoIndex might be able to help. It’s powered by an ultra-performant Rust engine and now supports adaptive batching out of box. This has improved Throughput by ~5× (≈80% faster runtime) for AI native workflows. And best of all, you don’t need to change any code because batching happens automatically, adapting to your traffic and keeping GPUs fully utilized.
Here’s what we learned while building adaptive batching support into Cocoindex.
But first, let’s answer some questions that might be on your mixnd.
Why does batching speed up processing?
-
Fixed overhead per call: This consists of all the preparatory and administrative work required before the actual computation can begin. Examples include GPU kernel launch setup, Python-to-C/C++ transitions, scheduling of tasks, memory allocation and management, and bookkeeping performed by the framework. These overhead tasks are largely independent of the input size but must be paid in full for each call.
\
-
Data-dependent work: This portion of the computation scales directly with the size and complexity of the input. It includes floating-point operations (FLOPs) performed by the model, data movement across memory hierarchies, token processing, and other input-specific operations. Unlike the fixed overhead, this cost increases proportionally with the volume of data being processed.
When items are processed individually, the fixed overhead is incurred repeatedly for each item, which can quickly dominate total runtime, especially when the per-item computation is relatively small. By contrast, processing multiple items together in batches significantly reduces the per-item impact of this overhead. Batching allows the fixed costs to be amortized across many items, while also enabling hardware and software optimizations that improve the efficiency of the data-dependent work. These optimizations include more effective utilization of GPU pipelines, better cache utilization, and fewer kernel launches, all of which contribute to higher throughput and lower overall latency.
\
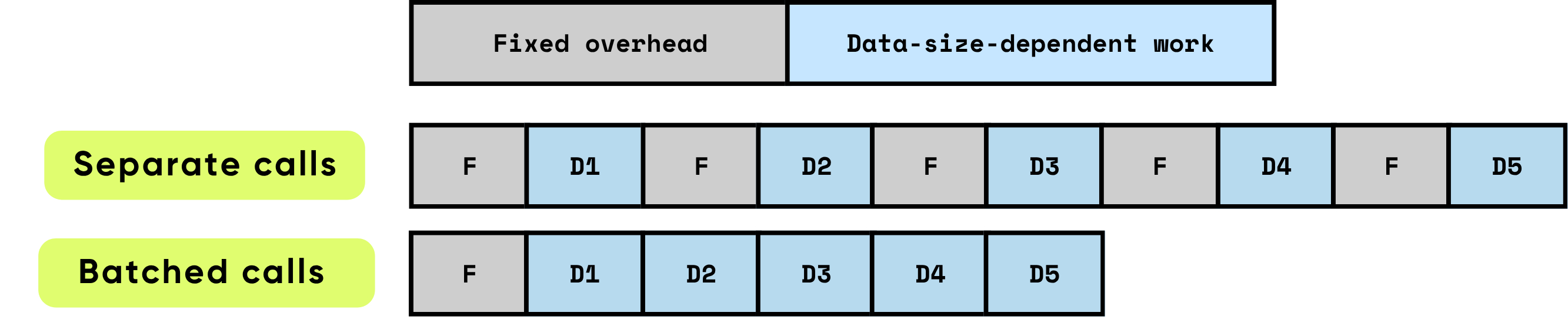
\ Batching significantly improves performance by optimizing both computational efficiency and resource utilization. It provides multiple, compounding benefits:
\
-
Amortizing one-time overhead: Each function or API call carries a fixed overhead — GPU kernel launches, Python-to-C/C++ transitions, task scheduling, memory management, and framework bookkeeping. By processing items in batches, this overhead is spread across many inputs, dramatically reducing the per-item cost and eliminating repeated setup work.
\
-
Maximizing GPU efficiency: Larger batches allow the GPU to execute operations as dense, highly parallel matrix multiplications, commonly implemented as General Matrix–Matrix Multiplication (GEMM). This mapping ensures the hardware runs at higher utilization, fully leveraging parallel compute units, minimizing idle cycles, and achieving peak throughput. Small, unbatched operations leave much of the GPU underutilized, wasting expensive computational capacity.
\
-
Reducing data transfer overhead: Batching minimizes the frequency of memory transfers between CPU (host) and GPU (device). Fewer Host-to-Device (H2D) and Device-to-Host (D2H) operations mean less time spent moving data and more time devoted to actual computation. This is critical for high-throughput systems, where memory bandwidth often becomes the limiting factor rather than raw compute power.
In combination, these effects lead to orders-of-magnitude improvements in throughput. Batching transforms many small, inefficient computations into large, highly optimized operations that fully exploit modern hardware capabilities. For AI workloads — including large language models, computer vision, and real-time data processing — batching is not just an optimization; it is essential for achieving scalable, production-grade performance.
\
What batching looks like for normal Python code
Non-batching code – simple but less efficient
The most natural way to organize a pipeline is to process data piece by piece. For example, a two-layer loop like this:
for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: vector = model.encode([chunk.text]) # one item at a time index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
This is easy to read and reason about: each chunk flows straight through multiple steps.
Batching manually – more efficient but complicated
You can speed it up by batching, but even the simplest “just batch everything once” version makes the code significantly more complicated:
\
# 1) Collect payloads and remember where each came from batch_texts = [] metadata = [] # (file_id, chunk_id) for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: batch_texts.append(chunk.text) metadata.append((file.name, chunk.offset)) # 2) One batched call (library will still mini-batch internally) vectors = model.encode(batch_texts) # 3) Zip results back to their sources for (file_name, chunk_offset), vector in zip(metadata, vectors): index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
Moreover, batching everything at once is usually not ideal because the next steps can only start after this step is done for all data.
CocoIndex’s Batching Support
CocoIndex bridges the gap and allows you to get the best of both worlds – keep the simplicity of your code by following the natural flow, while getting the efficiency from batching provided by CocoIndex runtime.
We already enabled batching support for the following built-in functions:
- EmbedText
- SentenceTransformerEmbed
- ColPaliEmbedImage
- ColPaliEmbedQuery
It doesn’t change the API. Your existing code will just work without any change – still following the natural flow, while enjoying the efficiency of batching.
For custom functions, enabling batching is as simple as:
- Set
batching=Truein the custom function decorator. - Change the arguments and return type to
list.
For example, if you want to create a custom function that calls an API to build thumbnails for images.
@cocoindex.op.function(batching=True) def make_image_thumbnail(self, args: list[bytes]) -> list[bytes]: ...
:::tip See the batching documentation for more details.
:::
How CocoIndex Batches
Common approaches
Batching works by collecting incoming requests into a queue and deciding the right moment to flush them as a single batch. That timing is crucial — get it right, and you balance throughput, latency, and resource usage all at once.
Two widely used batching policies dominate the landscape:
- Time-based batching (flush every W milliseconds): In this approach, the system flushes all requests that arrived within a fixed window of W milliseconds.
-
Advantages: The maximum wait time for any request is predictable, and implementation is straightforward. It ensures that even during low traffic, requests will not remain in the queue indefinitely.
-
Drawbacks: During periods of sparse traffic, idle requests accumulate slowly, adding latency for early arrivals. Additionally, the optimal window W often varies with workload characteristics, requiring careful tuning to strike the right balance between latency and throughput.
\
- Size-based batching (flush when K items are queued): Here, a batch is triggered once the queue reaches a pre-defined number of items, K.
- Advantages: The batch size is predictable, which simplifies memory management and system design. It is easy to reason about the resources each batch will consume.
- Drawbacks: When traffic is light, requests may remain in the queue for an extended period, increasing latency for the first-arriving items. Like time-based batching, the optimal K depends on workload patterns, requiring empirical tuning.
Many high-performance systems adopt a hybrid approach: they flush a batch when either the time window W expires or the queue reaches size K — whichever comes first. This strategy captures the benefits of both methods, improving responsiveness during sparse traffic while maintaining efficient batch sizes during peak load.
Despite this, batching always involves tunable parameters and trade-offs. Traffic patterns, workload characteristics, and system constraints all influence the ideal settings. Achieving optimal performance often requires monitoring, profiling, and dynamically adjusting these parameters to align with real-time conditions.
CocoIndex’s approach
Framework level: adaptive, knob-free
CocoIndex implements a simple and natural batching mechanism that adapts automatically to the incoming request load. The process works as follows:
\
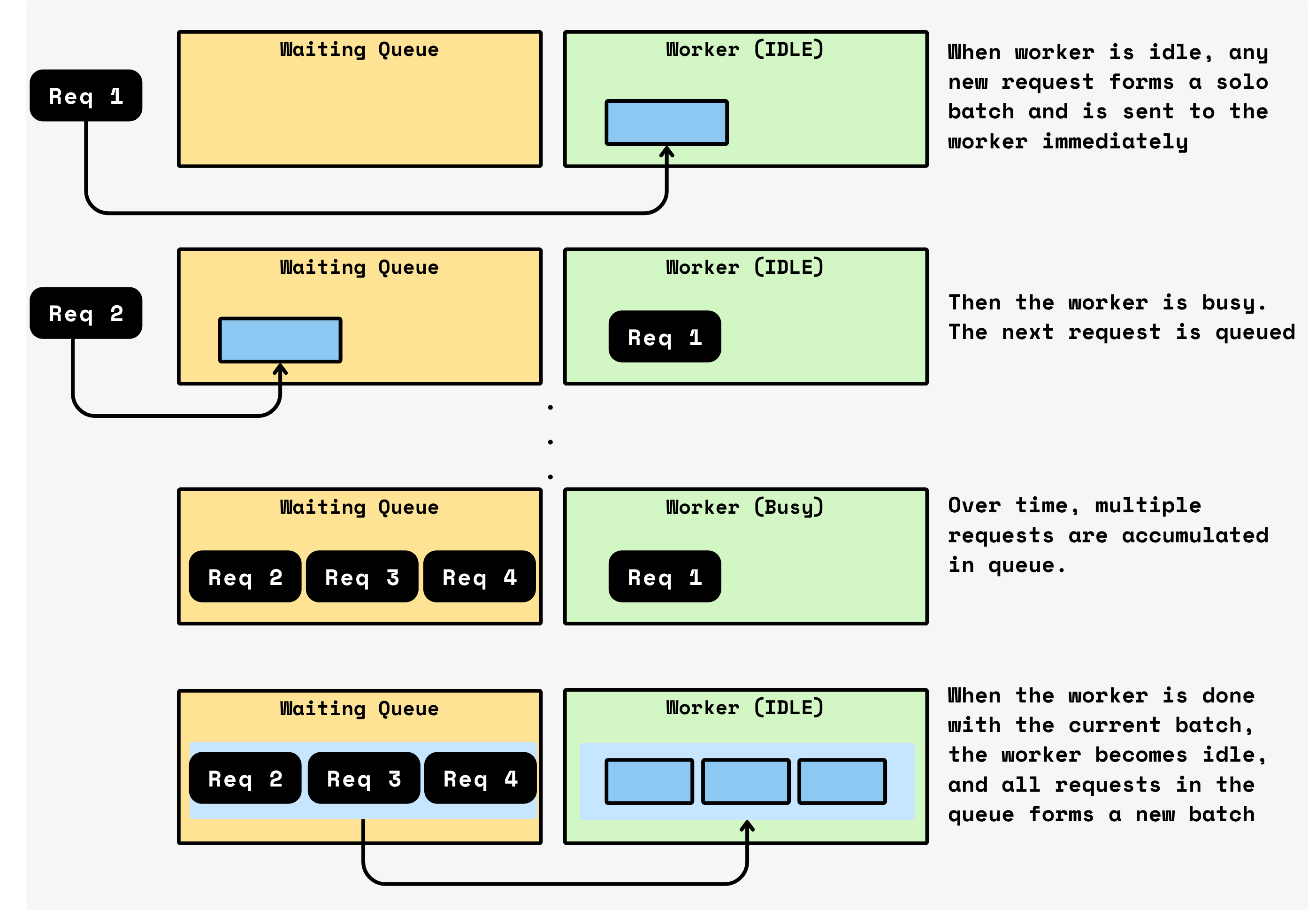
- Continuous queuing: While the current batch is being processed on the device (e.g., GPU), any new incoming requests are not immediately processed. Instead, they are queued. This allows the system to accumulate work without interrupting the ongoing computation.
- Automatic batch window: When the current batch completes, CocoIndex immediately takes all requests that have accumulated in the queue and treats them as the next batch. This set of requests forms the new batch window. The system then starts processing this batch right away.
- Adaptive batching: There are no timers, no fixed batch sizes, and no preconfigured thresholds. The size of each batch naturally adapts to the traffic that arrived during the previous batch’s service time. High traffic periods automatically produce larger batches, maximizing GPU utilization. Low traffic periods produce smaller batches, minimizing latency for early requests.
In essence, CocoIndex’s batching mechanism is self-tuning. It continuously processes requests in batches while allowing the batch size to reflect real-time demand, achieving high throughput without requiring manual tuning or complex heuristics.
\
\ Why is this good?
\
- Low latency when sparse: With few requests, batches are tiny (often size 1), so you’re effectively running at near single-call latency.
- High throughput when busy: When traffic spikes, more requests accumulate during the in-flight batch, so the next batch is larger — utilization rises automatically.
- No tuning: You don’t need to tune W or K. The system adapts to your traffic pattern by design.
Function-level batching: packing the batch intelligently
At the function level, CocoIndex empowers each function to handle the batch window — all queued requests at the moment the previous batch finishes — in the most efficient and safe way for its specific model or library. The framework delivers the batch promptly, but how it’s processed is up to the function, allowing for maximal flexibility and performance.
Take the SentenceTransformerEmbed function as an example. The underlying sentence-transformer library can accept batches of arbitrary length, but internally it splits them into micro-batches (default size: 32) to ensure each fits comfortably into device memory while keeping GPU kernels in their optimal “sweet spot.” CocoIndex leverages this default micro-batch size automatically.
Batching isn’t just about fitting data into memory — it’s also about minimizing wasted computation. Transformer runtimes typically pad every sequence in a batch to the length of the longest sequence, enabling the GPU to execute uniform, high-throughput kernels. However, this means short sequences pay the cost of the longest sequence in the batch. For example, mixing 64-token and 256-token items results in the 64-token items being processed ~4× more expensively than necessary. CocoIndex solves this by sorting requests by token count and forming micro-batches of roughly equal lengths, reducing padding overhead and keeping GPU utilization high.
Other functions can apply their own strategies: some may simply forward the full batch to the backend, while others may implement custom packing schemes like SIMD tiles or merge-writes. CocoIndex remains agnostic to the method — its responsibility is to deliver the batch window efficiently and without delay, giving each function full control over how to maximize throughput and minimize overhead.
This design balances simplicity, flexibility, and performance: the framework handles the orchestration of batching, while the functions themselves optimize for memory, compute, and kernel efficiency — ensuring high throughput across diverse workloads without forcing a one-size-fits-all solution.
Conclusion
Batching is one of the most effective strategies for accelerating computational workloads. By amortizing fixed overhead across multiple items, enabling larger, more efficient GPU operations, and minimizing data transfer, batching transforms what would be many small, inefficient computations into fewer, highly optimized operations.
CocoIndex makes batching effortless and automatic. Several built-in functions already leverage batching under the hood, and custom functions can adopt it with a simple batching=True decorator. This removes the complexity of manually managing queues, timers, or batch sizes, letting developers focus on their models and applications.
The performance benefits of batching are most pronounced when fixed overhead represents a significant portion of total computation, such as with smaller models or lightweight operations. Batching is also most effective when the underlying API or library fully supports batched operations, as partial support can limit gains — for example, some libraries like Ollama show only modest improvements under batching.
In short, batching is a high-leverage optimization: it maximizes throughput, reduces latency where it matters, and allows hardware to operate near its full potential — all while keeping the developer experience simple and predictable. CocoIndex abstracts the complexity, delivering the benefits of batching automatically across diverse workloads.
:::tip Support us by giving CocoIndex a ⭐ Star on GitHub and sharing with your community if you find it useful!
:::
\


You May Also Like

Tether CEO Ardoino warns AI infrastructure spending rests on four mismatches

Fed Governor Calls For Strong Stablecoin Oversight As CLARITY Act’s Final Text Gets Delayed

Micron Bets Big on AI With $9.3 Billion Memory Chip Expansion in Japan



