

Best Crypto Presales: Expert Top Picks For The Next Bull Run

This December brings fresh momentum to the presale market. Confidence is climbing, charts look stronger, and early-stage tokens keep rising as demand grows.
Retail traders are active again, and a clear “Santa rally” is pushing the best crypto presales forward as we head toward what many analysts see as the next big bull run in early 2025. The crypto market continues to reward people who position early.
Several live presales offer strong stories and real use cases, ranging from Bitcoin Layer 2 growth to meme-powered communities, and they are drawing heavy investor interest. This article highlights the top five projects with the biggest potential for major returns.
Source – Borch Crypto YouTube Channel
Bitcoin Hyper (HYPER)
Bitcoin Hyper brings Solana-level speed and low fees to Bitcoin while keeping users on the Bitcoin base layer. The project treats BTC as productive capital instead of letting it sit idle. It aims to power payments, DeFi, and gaming through a Bitcoin-secured Layer 2.
With SVM support, Bitcoin Hyper delivers very fast transactions and quick smart-contract execution. Its goal is to match or even beat Solana’s performance.

Users get almost instant wrapped-BTC payments, cheap swaps, and smooth NFT or gaming actions that feel similar to regular Web2 apps. The project also focuses on real-world use cases such as lending, staking, fast BTC payments, and NFT or gaming apps built with Rust tools.
The presale has raised around $29.5 million and is close to hitting $30 million. Influencers like Alessandro De Crypto expect a possible 100x after launch because of $HYPER’s utility and strong community.
$HYPER now trades at $0.013425, and even a small share of the Bitcoin Layer 2 market could push the price 5x or 10x after launch.
Presale momentum continues to grow. Smart money also enters the project, with several high-net-worth wallets adding close to 400,000 tokens in November. With a 39% live APY, $HYPER builds both a yield story and a growth story.
Investors can still join the presale on the Bitcoin Hyper website and buy tokens with SOL, ETH, USDT, USDC, BNB, or a credit card.
Bitcoin Hyper also suggests using Best Wallet for a smoother process. Many investors view it as one of the top crypto wallets today. $HYPER already appears in its Upcoming Tokens section, which makes it easy to buy, track, and claim once the token goes live.
Visit Bitcoin Hyper
Watch the video above to view the full list of best crypto presales.
Pepenode (PEPENODE)
The Pepenode team built the first “Mine-to-Earn” meme coin, using a virtual mining system and a Web3 game instead of physical mining rigs.
Players join through Miner Nodes and upgrades, so they avoid the cost of GPUs, electricity and hardware. This setup turns mining into an easy and accessible experience, even for beginners.
$PEPENODE removes the need to manage wattage or cooling. It gives users a simple game-style dashboard and clear node reward levels. As players buy and upgrade their nodes, they increase their earning power over time.
The presale also shows growing momentum, with around $2.3 million already raised. The project’s valuation still sits far below PEPE, the top frog-themed meme coin with a $1.8 billion market cap. This gives traders a clear upside target ahead of $PEPENODE’s TGE and game launch.
These points explain why some analysts call $PEPENODE the best crypto presale on the market right now.
Early incentives add even more interest. $PEPENODE trades at $0.0011968 and the presale will stay open for only 24 more days. Staking rewards reach as high as 553%, and users have already locked about 1.4 billion tokens in the staking pool.
The meme coin market is still recovering from late 2025 weakness, but traders have not left. They have become more selective, choosing projects that give holders something to do and remove barriers for non-technical users.
Pepenode fits that trend well. It brings a Mine-to-Earn system into a simple and fun game, gives strong benefits to early buyers and creates a clear path for long-term involvement.
With its current momentum and fundraising progress, many traders see a real chance for $PEPENODE to become the next 100x meme coin.
Visit Pepenode
Maxi Doge (MAXI)
Investors who want the next big move are not waiting for Dogecoin to repeat its old glory. They are shifting into high-beta meme coins that actually move.
This same pattern showed up in 2024. The top performers were not the famous names. They were unknown tokens like Fartcoin, Moo Deng and Dogwifhat. These coins exploded from nothing to huge gains because traders wanted assets with real upside energy.
That behavior will continue. When the market feels liquidity returning, traders do not run to the safe choices. They jump into the coins that look ready to make wild moves.
Maxi Doge stands out in that environment. Its branding, mascot, tone and loud personality all aim to grab attention in a way DOGE can no longer do, even with boosts from Elon Musk. Dogecoin has grown into a billion-dollar legacy coin. Maxi Doge still sits at an early stage with plenty of room to multiply.
The team also works hard to stay visible, and investors are responding. The presale has already pulled in $4.3 million before the token even hits an exchange. $MAXI now costs $0.000273 during this stage of the presale, and the price will move higher in the next tier.
The only way to buy $MAXI right now is through the ongoing presale. This gives early buyers a chance to load up before major exchange listings, especially as $MAXI becomes one of the best crypto presales for traders looking for early momentum.
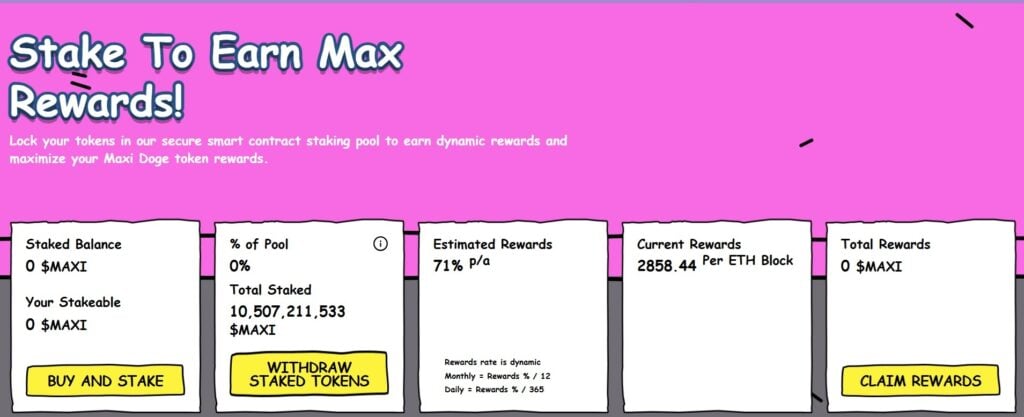
After buying $MAXI, you can stake it through the project’s protocol and earn a dynamic 71% APY.
Visit Maxi Doge
This article has been provided by one of our commercial partners and does not reflect Cryptonomist’s opinion. Please be aware our commercial partners may use affiliate programs to generate revenues through the links on this article.
You May Also Like

Uphold’s Massive 1.59 Billion XRP Holdings Shocks Community, CEO Reveals The Real Owners

Ethereum unveils roadmap focusing on scaling, interoperability, and security at Japan Dev Conference


