

Solus Partners Releases Report On Web3 Neobanks, Mapping Infrastructure, Licensing, And Regulatory Risks

Research and advisory firm Solus Partners has released a new report titled “The Compliance Infrastructure Stack,”offering a detailed analysis of how Web3 neobanks construct regulatory moats and manage infrastructure dependencies.
The report emphasizes that the defensibility of a Web3 neobank is determined not by its user interface or token incentives, but by how many layers of its infrastructure stack it owns versus rents, and whether it holds the licenses required to operate those layers independently.
The study highlights the rise of stablecoin-native neobanks, which allow users to hold dollar-pegged assets, spend via Visa or Mastercard, earn yield, and move funds across borders at near-zero cost. While the market remains in its early stages—with Web3 neobanks representing less than 0.2% of the $143–195 billion global neobank opportunity—the infrastructure decisions made today will determine which platforms survive regulatory scrutiny. Unlike most existing coverage that focuses on product features or user growth, this report takes a bottom-up approach, reverse-engineering the infrastructure stacks of several platforms to answer critical questions, such as Who owns their infrastructure versus renting it? Where are the hidden single points of failure? Which platforms hold the necessary licenses to operate independently under tightening regulations?
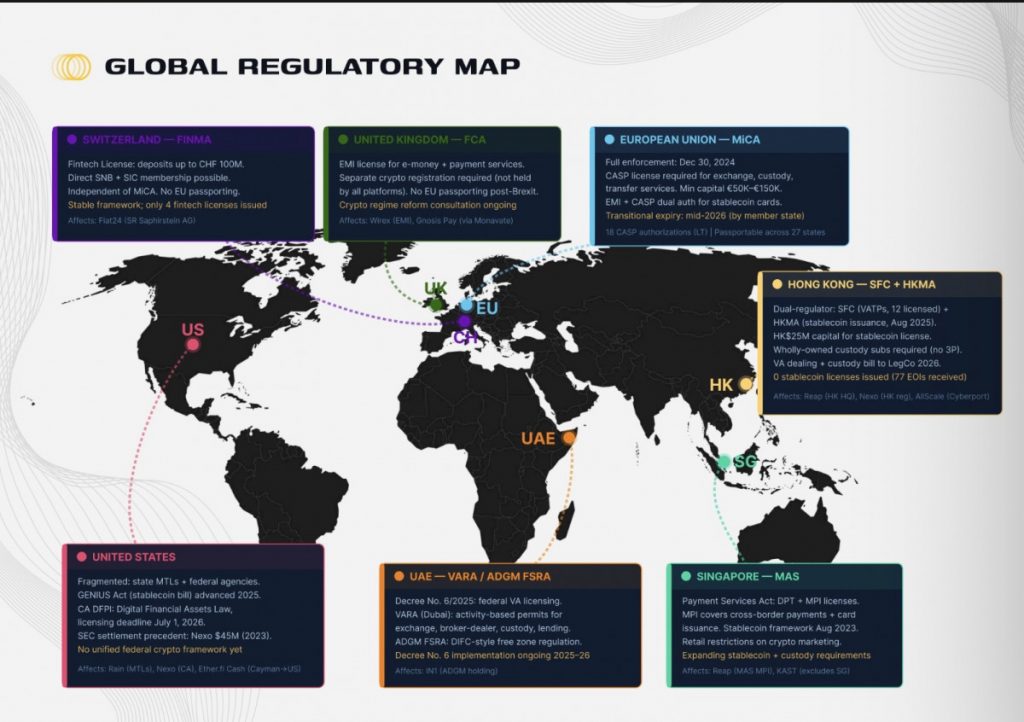
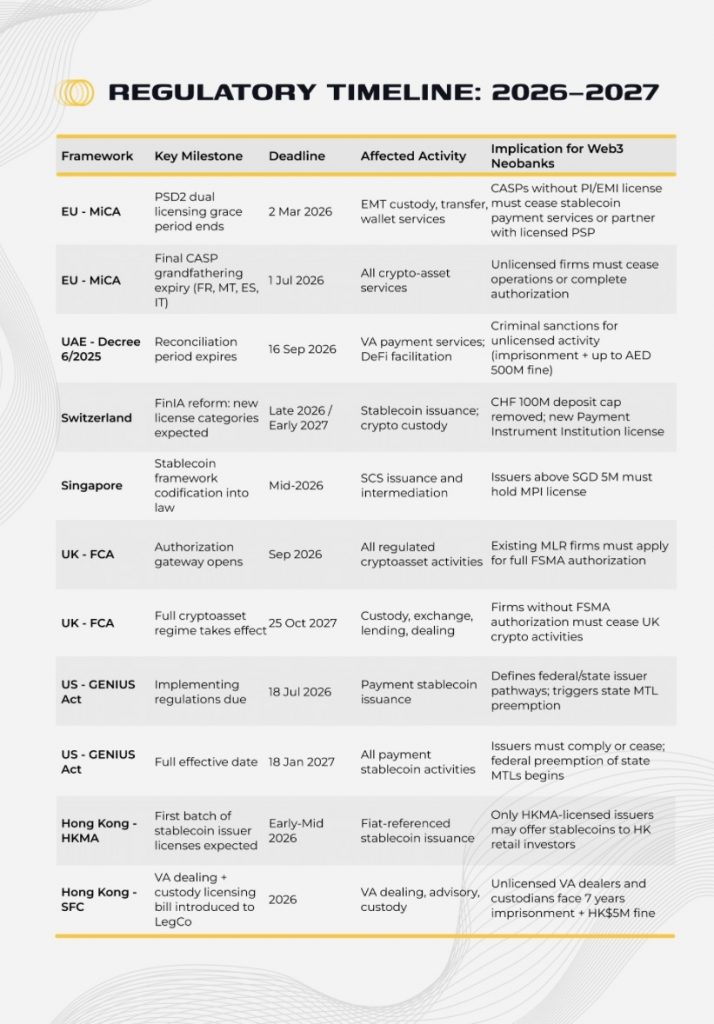
The answers are increasingly relevant as the Web3 neobank sector enters a regulatory phase transition. The full enforcement of MiCA in December 2024 will require CASP authorization for any platform offering crypto exchange, custody, or transfer services in the EU, with transitional periods expiring between mid-2025 and mid-2027. Platforms that fail to obtain authorization risk either ceasing EU operations or facing penalties of up to 12.5% of annual turnover.
Market Overview And Platform Taxonomy
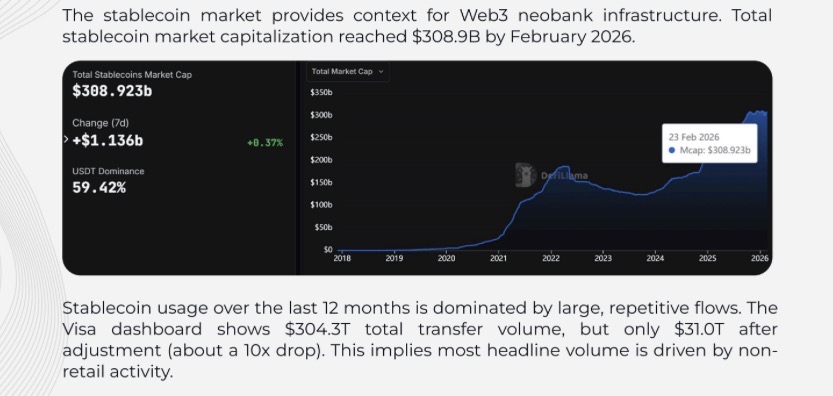
The report begins with an analysis of market sizing, platform taxonomy, and the stablecoin infrastructure landscape.The global neobank market reached an estimated $143–195 billion in 2024 and is projected to grow to $210–261 billion in 2025, with long-term forecasts indicating a 40–49% CAGR through the early 2030s. Approximately 350 million consumers worldwide are projected to use neobank services by 2025, with Europe accounting for 37–41% of revenue. Latin America’s neobank user base doubled from 85 million in 2022 to 170 million by 2024, driven primarily by Nubank, while U.S. digital-only bank users reached 39 million, a 22% year-over-year increase.
 Screenshot
Screenshot
While no major research firm tracks Web3 neobanks as a standalone market, CoinGecko’s neobank token category tracked 21 projects with a combined market capitalization of $2.7 billion in early 2026.
The platform taxonomy categorizes neobanks into Web2, hybrid, and Web3-native models, highlighting their approach to account management, custody, and blockchain integration. Notable projects include Chime, Monzo, N26, Revolut, Nubank, Cash App, Gnosis Pay, Fiat24, and Holyheld. The report further examines key market dynamics shaping Web3 neobanks through 2025 and 2026, covering stablecoin settlement, crypto card volumes, and institutional bank entry.
Regulatory Landscape
The report provides a forward-looking regulatory analysis for the upcoming year, highlighting how MiCA enforcement and related measures will impact Web3 neobank operations. Regulatory readiness, license acquisition, and compliance strategies are examined for each platform, showing which companies are positioned to survive and thrive as rules tighten.
 Screenshot
Screenshot
Six-Layer Infrastructure Anatomy
A major contribution of the report is its six-layer infrastructure framework, which analyzes vendor landscapes, pricing, and build-vs-buy decisions at each layer. Every Web3 neobank assembles a stack comprising:
- Card Issuance – Crypto-native principals like Rain and Reap hold direct Visa or Mastercard memberships, while traditional BIN sponsors such as Monavate, Unlimit, and Marqeta intermediate between card networks and fintech programs. Costs vary widely, with in-house builds taking 12–24 months and $2–10M+, while buying takes 3–6 months for $100–500K.
- KYC/AML – Identity verification, transaction monitoring, and FATF Travel Rule compliance are managed through vendors such as Sumsub, Jumio, Onfido, Chainalysis, TRM Labs, and Notabene. Costs range from $1–2.50 per verification, with annual analytics subscriptions exceeding $50K. Most platforms purchase these services rather than building in-house.
- Custody – Crypto safekeeping varies between third-party custodial (Fireblocks, BitGo, Copper), MPC/TSS semi-custodial solutions (Dfns, Fordefi), and self-custodial wallets. Self-custody is the highest owned ratio among layers, with compliance influenced by MiCA Art. 75 and Recital 83.
- Fiat On/Off-Ramp – Platforms integrate with providers like Transak, MoonPay, Ramp Network, and Onramper, or operate in-house EMIs such as Fiat24 and Deblock. Transaction costs range from 0.25%–5%, with internalization requiring $350K–1M+ capital.
- Core Banking Ledger – Account state and transaction management may be handled via BaaS providers (Column-Unit, Treasury Prime) or on-chain solutions (GP, Fiat24). Costs include SaaS fees ($100K+/yr) or minimal gas fees ($0.001–0.01 per transaction).
- Blockchain Settlement / Chain Selection – Platforms choose L1 and L2 chains such as Gnosis Chain, Arbitrum, Base, and Solana, supporting multi-chain operations, account abstraction (ERC-4337), and gas abstraction. Transaction costs vary from $0.00025 on Solana to $0.02 on Base.
Platform Profiles And Cross-Platform Analysis
The report includes detailed profiles of 19 platforms, reverse-engineering their infrastructure stacks, licensing status, and regulatory runway under MiCA and related 2026–2027 rules. Companies analyzed include Gnosis Pay, Fiat24, Ether.Fi Cash, Kast, Wirex, Deblock, Tria, Tuyo, IN1, CYPHER, Avici, Allscale, Holyheld, Nexo, Minipay, Reap, Rain, Nordark, and Stakestone.
A cross-platform analysis examines license clustering, infrastructure concentration, and regulatory divergence, highlighting potential risks such as vendor dependency and gaps in CASP authorization. The report identifies strategic build-vs-buy inflection points that could determine the long-term survival of these neobanks.
The full report is available here. Contributors include Rektonomist, Frigg, Brey, Temmy, and Defizard.
The post Solus Partners Releases Report On Web3 Neobanks, Mapping Infrastructure, Licensing, And Regulatory Risks appeared first on Metaverse Post.


You May Also Like

turnaround drags, China sales slump

Elon Musk trial on track as Washington securities case probes Twitter stake disclosure




