

Transitive Dependency Version Resolution in Rust and Java: Comparing the Two
You learn by comparing to what you already know. I was recently bitten by assuming Rust worked as Java regarding transitive dependency version resolution. In this post, I want to compare the two.
Dependencies, Transitivity, and Version Resolution
Before diving into the specifics of each stack, let's describe the domain and the problems that come with it.
\ When developing any project above Hello World level, chances are you'll face problems that others have faced before. If the problem is widespread, the probability is high that somebody was kind and civic-minded enough to have packaged the code that solves it, for others to re-use. Now, you can use the package and focus on solving your core problem. It's how industry builds most projects today, even if it brings other problems: you sit on the shoulders of giants.
\ Languages come with build tools that can add such packages to your project. Most of them refer to packages you add to your project as dependencies. In turn, projects' dependencies can have their own dependencies: the latter are called transitive dependencies.
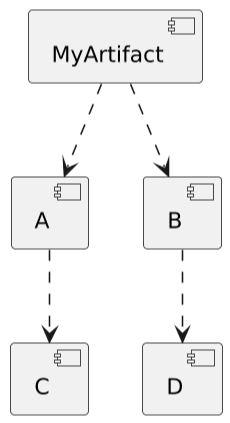
In the above diagram, C and D are transitive dependencies.
\ Transitive dependencies have issues on their own. The biggest one is when a transitive dependency is required from different paths, but in different versions. In the diagram below, A and B both depend on C, but on different versions of it.
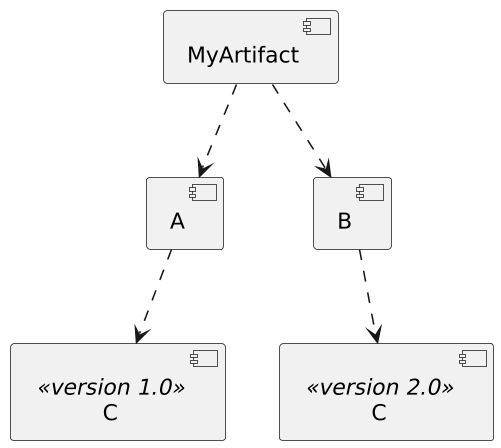
Which version of C should the build tool include in your project? Java and Rust have different answers. Let's describe them in turn.
Java Transitive Dependency Version Resolution
Reminder: Java code compiles to bytecode, which is then interpreted at runtime (and sometimes compiled to native code, but this is outside of our current problem space). I'll first describe runtime dependency resolution and build-time dependency resolution.
\ At runtime, the Java Virtual Machine offers the concept of a classpath. When having to load a class, the runtime searches through the configured classpath in order. Imagine the following class:
public static Main { public static void main(String[] args) { Class.forName("ch.frankel.Dep"); } } \ Let's compile it and execute it:
java -cp ./foo.jar:./bar.jar Main \ The above will first look in the foo.jar for the ch.frankel.Dep class. If found, it stops there and loads the class, regardless of whether it might also be present in the bar.jar; if not, it looks further in the bar.jar class. If still not found, it fails with a ClassNotFoundException.
\ Java's runtime dependency resolution mechanism is ordered and has a per-class granularity. It applies whether you run a Java class and define the classpath on the command line as above, or whether you run a JAR that defines the classpath in its manifest.
\ Let's change the above code to the following:
public static Main { public static void main(String[] args) { var dep = new ch.frankel.Dep(); } } \ Because the new code references Dep directly, new code requires class resolution at compile-time. Classpath resolution works in the same way:
javac -cp ./foo.jar:./bar.jar Main \ The compiler looks for Dep in foo.jar, then in bar.jar if not found. The above is what you learn at the beginning of your Java learning journey.
\ Afterwards, your unit of work is the Java Archive, known as the JAR, instead of the class. A JAR is a glorified ZIP archive, with an internal manifest that specifies its version.
\ Now, imagine that you're a user of foo.jar. Developers of foo.jar set a specific classpath when compiling, possibly including other JARs. You'll need this information to run your own command. How does a library developer pass this knowledge to downstream users?
\ The community came up with a few ideas to answer this question: The first response that stuck was Maven. Maven has the concept of Project Object Model, where you set your project's metadata, as well as dependencies. Maven can easily resolve transitive dependencies because they also publish their POM, with their own dependencies. Hence, Maven can trace each dependency's dependencies down to the leaf dependencies.
\ Now, back to the problem statement: how does Maven resolve version conflicts? Which dependency version will Maven resolve for C, 1.0 or 2.0?
\ The documentation is clear: the nearest.
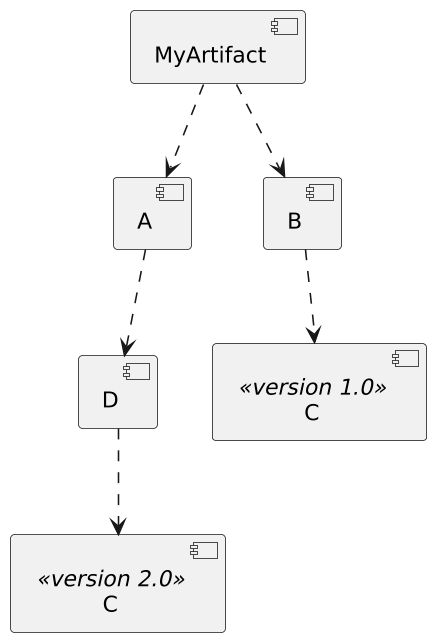
In the above diagram, the path to v1 has a distance of two, one to B, then one to C; meanwhile, the path to v2 has a distance of three, one to A, then one to D, then finally one to C. Thus, the shortest path points to v1.
\ However, in the initial diagram, both C versions are at the same distance from the root artifact. The documentation provides no answer. If you're interested in it, it depends on the order of declaration of A and B in the POM! In summary, Maven returns a single version of a duplicated dependency to include it on the compile classpath.
\ If A can work with C v2.0 or B with C 1.0, great! If not, you'll probably need to upgrade your version of A or downgrade your version of B, so that the resolved C version works with both. It's a manual process that is painful–ask me how I know. Worse, you might find out there's no C version that works with both A and B. Time to replace A or B.
Rust Transitive Dependency Version Resolution
Rust differs from Java in several aspects, but I think the following are the most relevant for the sake of our discussion:
- Rust has the same dependency tree at compile-time and at runtime
- It provides a build tool out of the box, Cargo
- Dependencies are resolved from source
\ Let's examine them one by one.
\ Java compiles to bytecode, then you run the latter. You need to set the classpath both at compilation time and at runtime. Compiling with a specific classpath and running with a different one can lead to errors. For example, imagine you compile with a class you depend on, but the class is absent at runtime. Or alternatively, it's present, but in an incompatible version.
\ Contrary to this modular approach, Rust compiles to a unique native package the crate's code and every dependency. Moreover, Rust provides its own build too, thus avoiding having to remember the quirks of different tools. I mentioned Maven, but other build tools likely have different rules to resolve the version in the use case above.
\ Finally, Java resolves dependencies from binaries: JARs. On the contrary, Rust resolves dependencies from sources. At build time, Cargo resolves the entire dependency tree, downloads all required sources, and compiles them in the correct order.
\ With this in mind, how does Rust resolve the version of the C dependency in the initial problem? The answer may seem strange if you come from a Java background, but Rust includes both. Indeed, in the above diagram, Rust will compile A with C v1.0 and compile B with C v2.0. Problem solved.
Conclusion
JVM languages, and Java in particular, offer both a compile-time classpath and a runtime classpath. It allows modularity and reusability, but opens the door to issues regarding classpath resolution. On the other hand, Rust builds your crate into a single self-contained binary, whether a library or an executable.
\ To go further:
- Maven - Introduction to the Dependency Mechanism
- Effective Rust - Item 25: Manage your dependency graph
Originally published at A Java Geek on September 14th, 2025
You May Also Like

Wilma now a low-pressure area, to drench Palawan, Western Visayas

Best Crypto to Buy as Saylor & Crypto Execs Meet in US Treasury Council
