

Open-Set Semantische Extractie: Grounded-SAM, CLIP, en DINOv2 Pipeline
Tabel van Links
Abstract en 1 Inleiding
-
Gerelateerde Werken
2.1. Visie-en-Taal Navigatie
2.2. Semantisch Scènebegrip en Instantiesegmentatie
2.3. 3D Scènereconstruktie
-
Methodologie
3.1. Gegevensverzameling
3.2. Open-set Semantische Informatie uit Afbeeldingen
3.3. Het Creëren van de Open-set 3D Representatie
3.4. Taalgestuurde Navigatie
-
Experimenten
4.1. Kwantitatieve Evaluatie
4.2. Kwalitatieve Resultaten
-
Conclusie en Toekomstig Werk, Openbaarmakingsverklaring, en Referenties
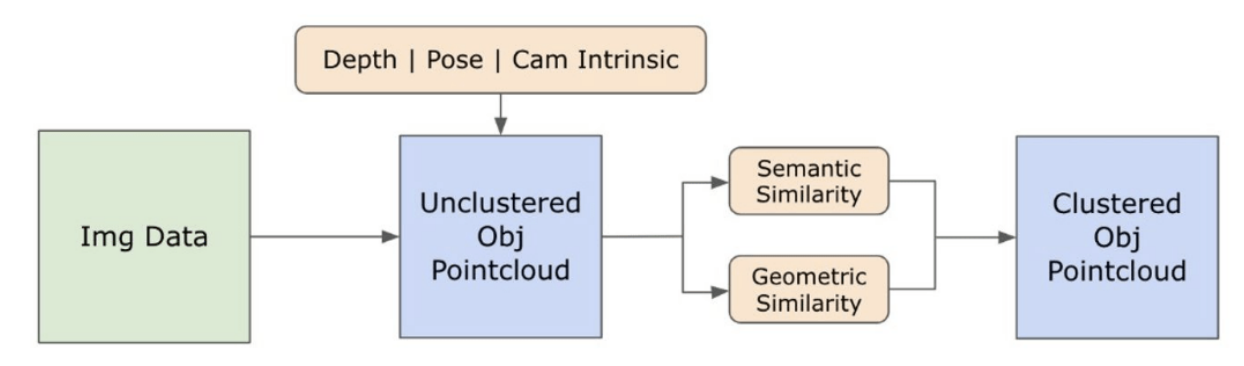
3.2. Open-set Semantische Informatie uit Afbeeldingen
\ 3.2.1. Open-set Semantische en Instantiemaskers Detectie
\ Het onlangs uitgebrachte Segment Anything model (SAM) [21] heeft aanzienlijke populariteit verworven onder onderzoekers en industriële gebruikers vanwege zijn geavanceerde segmentatiemogelijkheden. SAM heeft echter de neiging om een buitensporig aantal segmentatiemaskers voor hetzelfde object te produceren. We gebruiken het Grounded-SAM [32] model voor onze methodologie om dit probleem aan te pakken. Dit proces omvat het genereren van een reeks maskers in drie fasen, zoals weergegeven in Figuur 2. Eerst wordt een set tekstlabels gemaakt met behulp van het Recognizing Anything model (RAM) [33]. Vervolgens worden begrenzingsvakken die overeenkomen met deze labels gemaakt met behulp van het Grounding DINO model [25]. De afbeelding en de begrenzingsvakken worden vervolgens ingevoerd in SAM om klasse-agnostische segmentatiemaskers te genereren voor de objecten die in de afbeelding te zien zijn. We geven hieronder een gedetailleerde uitleg van deze aanpak, die het probleem van oversegmentatie effectief vermindert door semantische inzichten van RAM en Grounding-DINO te integreren.
\ Het RAM model [33] verwerkt de invoer RGB-afbeelding om semantische labeling te produceren van het object dat in de afbeelding is gedetecteerd. Het is een robuust basismodel voor beeldtagging, met opmerkelijke zero-shot capaciteit om verschillende algemene categorieën nauwkeurig te identificeren. De output van dit model koppelt elke invoer afbeelding aan een set labels die de objectcategorieën in de afbeelding beschrijven. Het proces begint met het openen van de invoer afbeelding en het converteren naar de RGB-kleurruimte, vervolgens wordt deze aangepast aan de invoervereisten van het model, en uiteindelijk getransformeerd in een tensor, waardoor het compatibel wordt met de analyse door het model. Hierna genereert het RAM-model labels of tags die de verschillende objecten of kenmerken in de afbeelding beschrijven. Er wordt een filtratieproces toegepast om de gegenereerde labels te verfijnen, waarbij ongewenste klassen uit deze labels worden verwijderd. Specifiek worden irrelevante tags zoals "muur", "vloer", "plafond" en "kantoor" verwijderd, samen met andere vooraf gedefinieerde klassen die onnodig worden geacht voor de context van de studie. Bovendien maakt deze fase het mogelijk om de labelset aan te vullen met eventuele vereiste klassen die aanvankelijk niet door het RAM-model zijn gedetecteerd. Ten slotte wordt alle relevante informatie geaggregeerd in een gestructureerd formaat. Specifiek wordt elke afbeelding gecatalogiseerd binnen het img_dict woordenboek, dat het pad van de afbeelding registreert samen met de set gegenereerde labels, waardoor een toegankelijke gegevensopslagplaats voor verdere analyse wordt gegarandeerd.
\ Na het taggen van de invoer afbeelding met gegenereerde labels, gaat de workflow verder door het Grounding DINO model [25] aan te roepen. Dit model is gespecialiseerd in het gronden van tekstuele zinnen naar specifieke regio's binnen een afbeelding, waarbij doelwitten effectief worden afgebakend met begrenzingsvakken. Dit proces identificeert en lokaliseert objecten ruimtelijk binnen de afbeelding, waardoor de basis wordt gelegd voor meer gedetailleerde analyses. Na het identificeren en lokaliseren van objecten via begrenzingsvakken wordt het Segment Anything Model (SAM) [21] ingezet. De primaire functie van het SAM-model is het genereren van segmentatiemaskers voor de objecten binnen deze begrenzingsvakken. Hierdoor isoleert SAM individuele objecten, waardoor een meer gedetailleerde en objectspecifieke analyse mogelijk wordt door de objecten effectief te scheiden van hun achtergrond en van elkaar binnen de afbeelding.
\ Op dit punt zijn instanties van objecten geïdentificeerd, gelokaliseerd en geïsoleerd. Elk object wordt geïdentificeerd met verschillende details, waaronder de coördinaten van het begrenzingsvak, een beschrijvende term voor het object, de waarschijnlijkheid of betrouwbaarheidsscore van het bestaan van het object uitgedrukt in logits, en het segmentatiemasker. Bovendien wordt elk object geassocieerd met CLIP en DINOv2 embedding kenmerken, waarvan de details in de volgende subsectie worden uitgewerkt.
\ 3.2.2. De Semantische Embedding Extractie
\ Om ons begrip van de semantische aspecten van objectinstanties die zijn gesegmenteerd en gemaskeerd binnen onze afbeeldingen te verbeteren, gebruiken we twee modellen, CLIP [9] en DINOv2 [10], om de kenmerkrepresentaties af te leiden van de uitgesneden afbeeldingen van elk object. Een model dat uitsluitend met CLIP is getraind, bereikt een robuust semantisch begrip van afbeeldingen, maar kan geen diepte en ingewikkelde details binnen die afbeeldingen onderscheiden. Aan de andere kant toont DINOv2 superieure prestaties in dieptewaarneming en blinkt uit in het identificeren van genuanceerde pixel-level relaties tussen afbeeldingen. Als een zelf-gesuperviseerde Vision Transformer kan DINOv2 genuanceerde kenmerkdetails extraheren zonder afhankelijk te zijn van geannoteerde gegevens, waardoor het bijzonder effectief is in het identificeren van ruimtelijke relaties en hiërarchieën binnen afbeeldingen. Terwijl het CLIP-model bijvoorbeeld moeite zou kunnen hebben om onderscheid te maken tussen twee stoelen van verschillende kleuren, zoals rood en groen, maken de mogelijkheden van DINOv2 het mogelijk om dergelijke onderscheidingen duidelijk te maken. Concluderend vangen deze modellen zowel de semantische als visuele kenmerken van de objecten, die later worden gebruikt voor vergelijkingen van gelijkenis in de 3D-ruimte.
\ 
\ Een reeks voorverwerkingsstappen wordt geïmplementeerd voor het verwerken van afbeeldingen met het DINOv2-model. Deze omvatten het aanpassen van de grootte, centraal uitsnijden, het converteren van de afbeelding naar een tensor, en het normaliseren van de uitgesneden afbeeldingen die zijn afgebakend door de begrenzingsvakken. De verwerkte afbeelding wordt vervolgens ingevoerd in het DINOv2-model samen met labels die zijn geïdentificeerd door het RAM-model om de DINOv2 embedding kenmerken te genereren. Bij het werken met het CLIP-model omvat de voorverwerkingsstap het transformeren van de uitgesneden afbeelding naar een tensorformaat dat compatibel is met CLIP, gevolgd door de berekening van embedding kenmerken. Deze embeddings zijn cruciaal omdat ze de visuele en semantische attributen van de objecten bevatten, die essentieel zijn voor een uitgebreid begrip van de objecten in de scène. Deze embeddings ondergaan normalisatie op basis van hun L2-norm, die de kenmerkenvector aanpast naar een gestandaardiseerde eenheidslengte. Deze normalisatiestap maakt consistente en eerlijke vergelijkingen tussen verschillende afbeeldingen mogelijk.
\ In de implementatiefase van deze fase itereren we over elke afbeelding binnen onze gegevens en voeren we de volgende procedures uit:
\ (1) De afbeelding wordt uitgesneden naar het interessegebied met behulp van de coördinaten van het begrenzingsvak die door het Grounding DINO-model zijn verstrekt, waardoor het object wordt geïsoleerd voor gedetailleerde analyse.
\ (2) Genereer DINOv2 en CLIP embeddings voor de uitgesneden afbeelding.
\ (3) Ten slotte worden de embeddings terugopgeslagen samen met de maskers uit de vorige sectie.
\ Met deze stappen voltooid, beschikken we nu over gedetailleerde kenmerkrepresentaties voor elk object, waardoor onze dataset wordt verrijkt voor verdere analyse en toepassing.
\
:::info Auteurs:
(1) Laksh Nanwani, International Institute of Information Technology, Hyderabad, India; deze auteur heeft in gelijke mate bijgedragen aan dit werk;
(2) Kumaraditya Gupta, International Institute of Information Technology, Hyderabad, India;
(3) Aditya Mathur, International Institute of Information Technology, Hyderabad, India; deze auteur heeft in gelijke mate bijgedragen aan dit werk;
(4) Swayam Agrawal, International Institute of Information Technology, Hyderabad, India;
(5) A.H. Abdul Hafez, Hasan Kalyoncu University, Sahinbey, Gaziantep, Turkije;
(6) K. Madhava Krishna, International Institute of Information Technology, Hyderabad, India.
:::
:::info Dit artikel is beschikbaar op arxiv onder de CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International) licentie.
:::
\
Misschien vind je dit ook leuk

HOLY Mining: Een nieuw tijdperk van wereldwijde Bitcoin cloud computing power inluiden

Carvana (CVNA) Aandeel: Jim Cramer Houdt Vast aan Bullish Voorspelling voor Gebruikte Auto Retailer
