

Superando o Fine-Tuning Completo com Apenas 0,2% dos Parâmetros
Tabela de Links
Resumo e 1. Introdução
-
Contexto
2.1 Mistura de Especialistas
2.2 Adaptadores
-
Mistura de Adaptações
3.1 Política de Roteamento
3.2 Regularização de consistência
3.3 Fusão de módulos de adaptação e 3.4 Partilha de módulos de adaptação
3.5 Conexão com Redes Neurais Bayesianas e Ensemble de Modelos
-
Experiências
4.1 Configuração Experimental
4.2 Resultados Principais
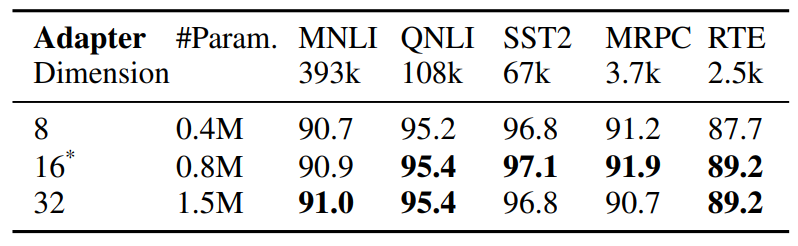
4.3 Estudo de Ablação
-
Trabalhos Relacionados
-
Conclusões
-
Limitações
-
Agradecimentos e Referências
Apêndice
A. Conjuntos de Dados NLU de Poucos Exemplos B. Estudo de Ablação C. Resultados Detalhados em Tarefas NLU D. Hiperparâmetros
5 Trabalhos Relacionados
Ajuste fino eficiente em parâmetros de PLMs. Trabalhos recentes sobre ajuste fino eficiente em parâmetros (PEFT) podem ser categorizados aproximadamente em duas
\ 
\ categorias: (1) ajuste de um subconjunto de parâmetros existentes, incluindo ajuste fino de cabeçalho (Lee et al., 2019), ajuste de termos de viés (Zaken et al., 2021), (2) ajuste de parâmetros recém-introduzidos, incluindo adaptadores (Houlsby et al., 2019; Pfeiffer et al., 2020), ajuste de prompt (Lester et al., 2021), ajuste de prefixo (Li e Liang, 2021) e adaptação de baixa classificação (Hu et al., 2021). Ao contrário de trabalhos anteriores que operam num único módulo de adaptação, o AdaMix introduz uma mistura de módulos de adaptação com roteamento estocástico durante o treino e fusão de módulos de adaptação durante a inferência para manter o mesmo custo computacional que com um único módulo. Além disso, o AdaMix pode ser usado em cima de qualquer método PEFT para aumentar ainda mais o seu desempenho.
\ Mistura de Especialistas (MoE). Shazeer et al., 2017 introduziram o modelo MoE com uma única rede de gateway com roteamento Top-k e balanceamento de carga entre especialistas. Fedus et al., 2021 propõem esquemas de inicialização e treino para roteamento Top-1. Zuo et al., 2021 propõem regularização de consistência para roteamento aleatório; Yang et al., 2021 propõem roteamento k Top-1 com protótipos de especialistas, e Roller et al., 2021; Lewis et al., 2021 abordam outras questões de balanceamento de carga. Todos os trabalhos acima estudam MoE esparso com pré-treino do modelo inteiro do zero. Em contraste, estudamos a adaptação eficiente em parâmetros de modelos de linguagem pré-treinados, ajustando apenas um número muito pequeno de parâmetros de adaptador esparsos.
\ Média de pesos de modelo. Explorações recentes (Szegedy et al., 2016; Matena e Raffel, 2021; Wortsman et al., 2022; Izmailov et al., 2018) estudam a agregação de modelos calculando a média de todos os pesos do modelo. (Matena e Raffel, 2021) propõem fundir modelos de linguagem pré-treinados que são ajustados em várias tarefas de classificação de texto. (Wortsman et al., 2022) explora a média de pesos de modelo de várias execuções independentes na mesma tarefa com diferentes configurações de hiperparâmetros. Em contraste com os trabalhos acima sobre ajuste fino de modelo completo, focamos no ajuste fino eficiente em parâmetros. Exploramos a média de pesos para fundir pesos de módulos de adaptação compostos por pequenos parâmetros ajustáveis que são atualizados durante o ajuste do modelo, mantendo fixos os grandes parâmetros do modelo.
6 Conclusões
Desenvolvemos uma nova estrutura AdaMix para ajuste fino eficiente em parâmetros (PEFT) de grandes modelos de linguagem pré-treinados (PLM). O AdaMix aproveita uma mistura de módulos de adaptação para melhorar o desempenho de tarefas downstream sem aumentar o custo computacional (por exemplo, FLOPs, parâmetros) do método de adaptação subjacente. Demonstramos que o AdaMix funciona e melhora diferentes métodos PEFT como adaptadores e decomposições de baixa classificação em tarefas NLU e NLG.
\ Ajustando apenas 0,1 − 0,2% dos parâmetros PLM, o AdaMix supera o ajuste fino de modelo completo que atualiza todos os parâmetros do modelo, bem como outros métodos PEFT de última geração.
7 Limitações
O método AdaMix proposto é um tanto intensivo em computação, pois envolve o ajuste fino de modelos de linguagem em grande escala. O custo de treino do AdaMix proposto é maior do que os métodos PEFT padrão, uma vez que o procedimento de treino envolve múltiplas cópias de adaptadores. Com base na nossa observação empírica, o número de iterações de treino para o AdaMix geralmente está entre 1∼2 vezes o treino para métodos PEFT padrão. Isso impõe um impacto negativo na pegada de carbono do treino dos modelos descritos.
\ O AdaMix é ortogonal à maioria dos estudos existentes de ajuste fino eficiente em parâmetros (PEFT) e é capaz de potencialmente melhorar o desempenho de qualquer método PEFT. Neste trabalho, exploramos dois métodos PEFT representativos como adaptador e LoRA, mas não experimentamos com outras combinações como ajuste de prompt e ajuste de prefixo. Deixamos esses estudos para trabalhos futuros.
8 Agradecimentos
Os autores gostariam de agradecer aos árbitros anónimos pelos seus valiosos comentários e sugestões úteis e gostariam de agradecer a Guoqing Zheng e Ruya Kang pelos seus comentários perspicazes sobre o projeto. Este trabalho é apoiado em parte pela US National Science Foundation sob as bolsas NSFIIS 1747614 e NSF-IIS-2141037. Quaisquer opiniões, descobertas e conclusões ou recomendações expressas neste material são dos autores e não refletem necessariamente as opiniões da National Science Foundation.
Referências
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. 2021. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7319– 7328, Online. Association for Computational Linguistics.
\ Roy Bar Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. 2006. The second PASCAL recognising textual entailment challenge.
\ Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. 2009. The fifth PASCAL recognizing textual entailment challenge. In TAC.
\ Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel HerbertVoss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
\ Ido Dagan, Oren Glickman, and Bernardo Magnini. 2005. The PASCAL recognising textual entailment challenge. In the First International Conference on Machine Learning Challenges: Evaluating Predictive Uncertainty Visual Object Classification, and Recognizing Textual Entailment.
\ Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Volume 1 (Long and Short Papers), pages 4171–4186.
\ William Fedus, Barret Zoph, and Noam Shazeer. 2021. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv preprint arXiv:2101.03961.
\ Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. 2020. Linear mode connectivity and the lottery ticket hypothesis. In International Conference on Machine Learning, pages 3259–3269. PMLR.
\ Yarin Gal and Zoubin Ghahramani. 2015. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. CoRR, abs/1506.02142.
\ Yarin Gal, Riashat Islam, and Zoubin Ghahramani. 2017. Deep Bayesian active learning with image data. In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1183–1192. PMLR.
\ Tianyu Gao, Adam Fisch, and Danqi Chen. 2021. Making pre-trained language models better few-shot learners. In Association for Computational Linguistics (ACL).
\ Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. 2017. The webnlg challenge: Generating text from rdf data. In Proceedings of the 10th International Conference on Natural Language Generation, pages 124–133.
\ Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and Bill Dolan. 2007. The third PASCAL recognizing textual entailment challenge. In the ACLPASCAL Workshop on Textual Entailment and Paraphrasing.
\ Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR.
\ Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
\ Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. 2018. Averaging weights leads to wider optima and better generalization. arXiv preprint arXiv:1803.05407.
\ Jaejun Lee, Raphael Tang, and Jimmy Lin. 2019. What would elsa do? freezing layers during transformer fine-tuning. arXiv preprint arXiv:1911.03090.
\ Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2020. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668.
\ Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. CoRR, abs/2104.08691.
\ Mike Lewis, Shruti Bhosale, Tim Dettmers, Naman Goyal, and Luke Zettlemoyer. 2021. Base layers: Simplifying training of large, sparse models. In ICML.
\ Xiang Lisa Li and Percy Liang. 2021. Prefixtuning: Optimizing continuous prompts for generation. CoRR, abs/2101.00190.
\ Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimize
Você também pode gostar

Venda de café brasileiro para a China cresceu 30,4% em 2025

Segredos da documentação de leilões de imóveis que podem salvar seu investimento
