

Resolvendo o maior obstáculo da segmentação 3D
:::info Autores:
(1) George Tang, Massachusetts Institute of Technology;
(2) Krishna Murthy Jatavallabhula, Massachusetts Institute of Technology;
(3) Antonio Torralba, Massachusetts Institute of Technology.
:::
Tabela de Links
Resumo e I. Introdução
II. Contexto
III. Método
IV. Experiências
V. Conclusão e Referências
\ 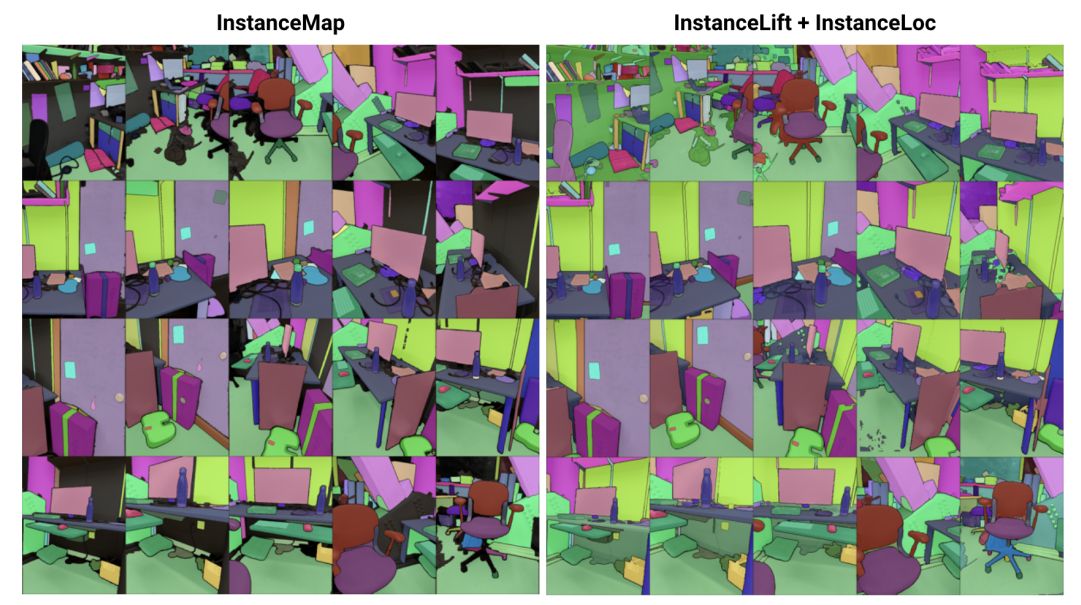
\ Resumo— Abordamos o problema de aprender uma representação implícita de cena para segmentação de instâncias 3D a partir de uma sequência de imagens RGB posicionadas. Para isso, introduzimos o 3DIML, uma estrutura inovadora que aprende eficientemente um campo de etiquetas que pode ser renderizado a partir de novos pontos de vista para produzir máscaras de segmentação de instâncias consistentes com a vista. O 3DIML melhora significativamente os tempos de treino e inferência dos métodos existentes baseados em representação implícita de cena. Ao contrário da arte anterior que otimiza um campo neural de forma auto-supervisionada, exigindo procedimentos de treino complicados e design de função de perda, o 3DIML utiliza um processo de duas fases. A primeira fase, InstanceMap, recebe como entrada máscaras de segmentação 2D da sequência de imagens geradas por um modelo de segmentação de instância frontend, e associa máscaras correspondentes entre imagens a etiquetas 3D. Estas máscaras de pseudoetiqueta quase consistentes com a vista são então usadas na segunda fase, InstanceLift, para supervisionar o treino de um campo de etiquetas neural, que interpola regiões perdidas pelo InstanceMap e resolve ambiguidades. Adicionalmente, introduzimos o InstanceLoc, que permite a localização em tempo quase real de máscaras de instância dado um campo de etiquetas treinado e um modelo de segmentação de imagem pronto, fundindo saídas de ambos. Avaliamos o 3DIML em sequências dos conjuntos de dados Replica e ScanNet e demonstramos a eficácia do 3DIML sob suposições leves para as sequências de imagens. Alcançamos uma grande aceleração prática em relação aos métodos existentes de representação implícita de cena com qualidade comparável, mostrando o seu potencial para facilitar uma compreensão de cena 3D mais rápida e eficaz.
I. INTRODUÇÃO
Agentes inteligentes requerem compreensão de cena ao nível do objeto para realizar eficazmente ações específicas ao contexto, como navegação e manipulação. Embora a segmentação de objetos a partir de imagens tenha visto um progresso notável com modelos escaláveis treinados em conjuntos de dados à escala da internet [1], [2], estender tais capacidades para o ambiente 3D continua a ser desafiante.
\ Neste trabalho, abordamos o problema de aprender uma representação de cena 3D a partir de imagens 2D posicionadas que fatoriza a cena subjacente no seu conjunto de objetos constituintes. As abordagens existentes para resolver este problema têm-se concentrado no treino de modelos de segmentação 3D agnósticos de classe [3], [4], exigindo grandes quantidades de dados 3D anotados e operando diretamente sobre representações explícitas de cena 3D (por exemplo, nuvens de pontos). Uma classe alternativa de abordagens [5], [6] propôs, em vez disso, elevar diretamente máscaras de segmentação de modelos de segmentação de instância prontos para representações 3D implícitas, como campos de radiância neural (NeRF) [7], permitindo-lhes renderizar máscaras de instância 3D consistentes a partir de novos pontos de vista.
\ No entanto, as abordagens baseadas em campos neurais têm permanecido notoriamente difíceis de otimizar, com [5] e [6] levando várias horas para otimizar imagens de resolução baixa a média (por exemplo, 300 × 640). Em particular, o Panoptic Lifting [5] escala cubicamente com o número de objetos na cena, impedindo que seja aplicado a cenas com centenas de objetos, enquanto o Contrastively Lifting [6] requer um procedimento de treino complicado e multi-estágio, dificultando a praticidade para uso em aplicações robóticas.
\ Para este fim, propomos o 3DIML, uma técnica eficiente para aprender segmentação de instâncias 3D consistente a partir de imagens RGB posicionadas. O 3DIML compreende duas fases: InstanceMap e InstanceLift. Dadas máscaras de instância 2D inconsistentes com a vista extraídas da sequência RGB usando um modelo de segmentação de instância frontend [2], o InstanceMap produz uma sequência de máscaras de instância consistentes com a vista. Para isso, primeiro associamos máscaras entre frames usando correspondências de pontos-chave entre pares de imagens semelhantes. Em seguida, usamos essas associações potencialmente ruidosas para supervisionar um campo de etiquetas neural, InstanceLift, que explora a estrutura 3D para interpolar etiquetas ausentes e resolver ambiguidades. Ao contrário de trabalhos anteriores, que requerem treino multi-estágio e engenharia adicional de função de perda, usamos uma única perda de renderização para supervisão de etiquetas de instância, permitindo que o processo de treino convirja significativamente mais rápido. O tempo total de execução do 3DIML, incluindo o InstanceMap, leva 10-20 minutos, em oposição a 3-6 horas para a arte anterior.
\ Além disso, desenvolvemos o InstaLoc, um pipeline de localização rápido que recebe uma nova vista e localiza todas as instâncias segmentadas nessa imagem (usando um modelo de segmentação de instância rápido [8]) consultando esparsamente o campo de etiquetas e fundindo as previsões de etiquetas com regiões de imagem extraídas. Finalmente, o 3DIML é extremamente modular, e podemos facilmente trocar componentes do nosso método por outros mais performantes à medida que se tornam disponíveis.
\ Para resumir, as nossas contribuições são:
\ • Uma abordagem eficiente de aprendizagem de campo neural que fatoriza uma cena 3D nos seus objetos constituintes
\ • Um algoritmo rápido de localização de instâncias que funde consultas esparsas ao campo de etiquetas treinado com modelos performantes de segmentação de instância de imagem para gerar máscaras de segmentação de instância 3D consistentes
\ • Uma melhoria geral de tempo de execução prático de 14-24× sobre a arte anterior testada numa única GPU (NVIDIA RTX 3090)
II. CONTEXTO
Segmentação 2D: A prevalência da arquitetura de transformador de visão e a escala crescente de conjuntos de dados de imagens resultaram numa série de modelos de segmentação de imagem de última geração. Panoptic e Contrastive Lifting ambos elevam máscaras de segmentação panóptica produzidas pelo Mask2Former [1] para 3D aprendendo um campo neural. Em direção à segmentação de conjunto aberto, o segment anything (SAM) [2] alcança desempenho sem precedentes treinando em mil milhões de máscaras em 11 milhões de imagens. HQ-SAM [9] melhora o SAM para máscaras de granulação fina. FastSAM [8] destila o SAM numa arquitetura CNN e alcança desempenho semelhante sendo ordens de magnitude mais rápido. Neste trabalho, usamos o GroundedSAM [10], [11], que refina o SAM para produzir máscaras de segmentação ao nível do objeto, em oposição ao nível da parte.
\ Campos neurais para segmentação de instâncias 3D: NeRFs são representações implícitas de cena que podem codificar com precisão geometria complexa, semântica e outras modalidades, bem como resolver supervisão inconsistente de ponto de vista [12]. Panoptic lifting [5] constrói ramos de semântica e instâncias numa variante eficiente do NeRF, TensoRF [13], utilizando uma função de perda de correspondência húngara para atribuir máscaras de instância aprendidas a IDs de objeto substitutos dadas máscaras de referência inconsistentes com a vista. Isto escala mal com o aumento do número de objetos (devido à complexidade cúbica da correspondência húngara). Contrastive lifting [6] aborda isto empregando, em vez disso, aprendizagem contrastiva em características de cena, com relações positivas e negativas determinadas por se projetam ou não na mesma máscara. Além disso, o contrastive lifting requer uma perda baseada em clustering lento-rápido para treino estável, levando a um desempenho mais rápido que o panoptic lifting, mas requer múltiplos estágios de treino, levando a uma convergência lenta. Simultaneamente a nós, Instance-NeRF [14] aprende diretamente um campo de etiquetas, mas baseiam a sua associação de máscaras na utilização do NeRF-RPN [15] para detetar objetos num NeRF. A nossa abordagem, pelo contrário, permite escalar para resoluções de imagem muito altas enquanto requer apenas um pequeno número (40-60) de consultas de campo neural para renderizar máscaras de segmentação.
\ Estrutura a partir do Movimento: Durante a associação de máscaras no InstanceMap, inspiramo-nos em pipelines escaláveis de reconstrução 3D como o hLoc [16], incluindo o uso de descritores visuais para corresponder primeiro pontos de vista de imagem, e depois aplicar correspondência de pontos-chave como preliminar para associação de máscaras. Utilizamos o LoFTR [17] para extração e correspondência de pontos-chave.
\
:::info Este artigo está disponível no arxiv sob a licença CC by 4.0 Deed (Atribuição 4.0 Internacional).
:::
\
Você também pode gostar

Três perfumes importados por menos de R$ 100 que entregam presença

Inundações na Indonésia deixam mais de 1.000 mortos, diz agência
