

Deteção de Anomalias Baseada em Transformers Utilizando Incorporações de Sequências de Registos

Tabela de links
Resumo
1 Introdução
2 Contexto e Trabalhos Relacionados
2.1 Diferentes Formulações da Tarefa de Deteção de Anomalias Baseada em Logs
2.2 Supervisionado vs. Não Supervisionado
2.3 Informação dentro dos Dados de Log
2.4 Agrupamento de Janela Fixa
2.5 Trabalhos Relacionados
3 Uma Abordagem Configurável de Deteção de Anomalias Baseada em Transformer
3.1 Formulação do Problema
3.2 Análise de Logs e Incorporação de Logs
3.3 Codificação Posicional e Temporal
3.4 Estrutura do Modelo
3.5 Classificação Binária Supervisionada
4 Configuração Experimental
4.1 Conjuntos de Dados
4.2 Métricas de Avaliação
4.3 Geração de Sequências de Log de Comprimentos Variados
4.4 Detalhes de Implementação e Ambiente Experimental
5 Resultados Experimentais
5.1 RQ1: Como é que o nosso modelo proposto de deteção de anomalias se comporta em comparação com as linhas de base?
5.2 RQ2: Quanto é que a informação sequencial e temporal dentro das sequências de log afeta a deteção de anomalias?
5.3 RQ3: Quanto é que os diferentes tipos de informação contribuem individualmente para a deteção de anomalias?
6 Discussão
7 Ameaças à validade
8 Conclusões e Referências
\
3 Uma Abordagem Configurável de Deteção de Anomalias Baseada em Transformer
Neste estudo, apresentamos um novo método baseado em transformer para deteção de anomalias. O modelo utiliza sequências de log como entradas para detetar anomalias. O modelo emprega um modelo BERT pré-treinado para incorporar modelos de log, permitindo a representação de informação semântica dentro das mensagens de log. Estas incorporações, combinadas com codificação posicional ou temporal, são subsequentemente introduzidas no modelo transformer. A informação combinada é utilizada na subsequente geração de representações ao nível da sequência de log, facilitando o processo de deteção de anomalias. Projetamos o nosso modelo para ser flexível: As características de entrada são configuráveis para que possamos usar ou conduzir experiências com diferentes combinações de características dos dados de log. Além disso, o modelo é projetado e treinado para lidar com sequências de log de entrada de comprimentos variados. Nesta secção, apresentamos a nossa formulação do problema e o design detalhado do nosso método.
\ 3.1 Formulação do Problema
Seguimos os trabalhos anteriores [1] para formular a tarefa como uma tarefa de classificação binária, na qual treinamos o nosso modelo proposto para classificar sequências de log em anomalias e normais de forma supervisionada. Para as amostras utilizadas no treino e avaliação do modelo, utilizamos uma abordagem de agrupamento flexível para gerar sequências de log de comprimentos variados. Os detalhes são apresentados na Secção 4
\ 3.2 Análise de Logs e Incorporação de Logs
No nosso trabalho, transformamos eventos de log em vetores numéricos codificando modelos de log com um modelo de linguagem pré-treinado. Para obter os modelos de log, adotamos o analisador Drain [24], que é amplamente utilizado e tem bom desempenho de análise na maioria dos conjuntos de dados públicos [4]. Utilizamos um modelo sentence-bert pré-treinado [25] (ou seja, all-MiniLML6-v2 [26]) para incorporar os modelos de log gerados pelo processo de análise de log. O modelo pré-treinado é treinado com um objetivo de aprendizagem contrastiva e alcança desempenho de última geração em várias tarefas de PNL. Utilizamos este modelo pré-treinado para criar uma representação que captura informação semântica de mensagens de log e ilustra a similaridade entre modelos de log para o modelo de deteção de anomalias downstream. A dimensão de saída do modelo é 384.
\ 3.3 Codificação Posicional e Temporal
O modelo transformer original [27] adota uma codificação posicional para permitir que o modelo utilize a ordem da sequência de entrada. Como o modelo não contém recorrência nem convolução, os modelos serão agnósticos à sequência de log sem a codificação posicional. Embora alguns estudos sugiram que modelos transformer sem codificação posicional explícita permanecem competitivos com modelos padrão ao lidar com dados sequenciais [28, 29], é importante notar que qualquer permutação da sequência de entrada produzirá o mesmo estado interno do modelo. Como a informação sequencial ou temporal pode ser indicadores importantes para anomalias dentro de sequências de log, trabalhos anteriores baseados em modelos transformer utilizam a codificação posicional padrão para injetar a ordem de eventos de log ou modelos na sequência [11, 12, 21], visando detetar anomalias associadas à ordem de execução errada. No entanto, notamos que numa implementação de replicação comumente usada de um método baseado em transformer [5], a codificação posicional foi, de facto, omitida. Até onde sabemos, nenhum trabalho existente codificou a informação temporal baseada nos timestamps dos logs para o seu método de deteção de anomalias. A eficácia da utilização de informação sequencial ou temporal na tarefa de deteção de anomalias não é clara.
\ No nosso método proposto, tentamos incorporar codificação sequencial e temporal no modelo transformer e explorar a importância da informação sequencial e temporal para deteção de anomalias. Especificamente, o nosso método proposto tem diferentes variantes utilizando as seguintes técnicas de codificação sequencial ou temporal. A codificação é então adicionada à representação de log, que serve como entrada para a estrutura transformer.
\ 
3.3.1 Codificação de Tempo Decorrido Relativo (RTEE)
Propomos este método de codificação temporal, RTEE, que simplesmente substitui o índice de posição na codificação posicional pelo tempo de cada evento de log. Primeiro calculamos o tempo decorrido de acordo com os timestamps dos eventos de log na sequência de log. Em vez de usar o índice de sequência do evento de log como a posição para equações sinusoidais e cossinusoidais, usamos o tempo decorrido relativo ao primeiro evento de log na sequência de log para substituir o índice de posição. A Tabela 1 mostra um exemplo de intervalos de tempo numa sequência de log. No exemplo, temos uma sequência de log contendo 7 eventos com um intervalo de tempo de 7 segundos. O tempo decorrido do primeiro evento para cada evento na sequência é utilizado para calcular a codificação de tempo para os eventos correspondentes. Semelhante à codificação posicional, a codificação é calculada com as equações 1 mencionadas acima, e a codificação não será atualizada durante o processo de treino.
\ 
3.4 Estrutura do Modelo
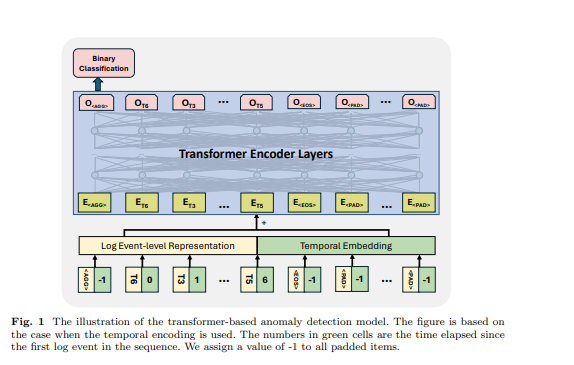
O transformer é uma arquitetura de rede neural que depende do mecanismo de auto-atenção para capturar a relação entre elementos de entrada numa sequência. Os modelos e frameworks baseados em transformer têm sido usados na tarefa de deteção de anomalias por muitos trabalhos anteriores [6, 11, 12, 21]. Inspirados pelos trabalhos anteriores, usamos um modelo baseado em codificador transformer para deteção de anomalias. Projetamos a nossa abordagem para aceitar sequências de log de comprimentos variados e gerar representações ao nível da sequência. Para alcançar isso, empregamos alguns tokens específicos na sequência de log de entrada para o modelo gerar representação de sequência e identificar os tokens preenchidos e o fim da sequência de log, inspirando-nos no design do modelo BERT [31]. Na sequência de log de entrada, usamos os seguintes tokens: é colocado no início de cada sequência para permitir que o modelo gere informação agregada para toda a sequência, é adicionado no final da sequência para significar a sua conclusão, é usado para marcar os tokens mascarados sob o paradigma de treino auto-supervisionado, e é usado para tokens preenchidos. As incorporações para estes tokens especiais são geradas aleatoriamente com base na dimensão da representação de log usada. Um exemplo é mostrado na Figura 1, o tempo decorrido para , e são definidos como -1. A representação ao nível do evento de log e a incorporação posicional ou temporal são somadas como a característica de entrada da estrutura transformer.
\ 3.5 Classificação Binária Supervisionada Sob este objetivo de treino, utilizamos a saída do primeiro token do modelo transformer enquanto ignoramos as saídas dos outros tokens. Esta saída do primeiro token é projetada para agregar a informação de toda a sequência de log de entrada, semelhante ao token do modelo BERT, que fornece uma representação agregada da sequência de tokens. Portanto, consideramos a saída deste token como uma representação ao nível da sequência. Treinamos o modelo com um objetivo de classificação binária (ou seja, Perda de Entropia Cruzada Binária) com esta representação.
\ 
:::info Autores:
- Xingfang Wu
- Heng Li
- Foutse Khomh
:::
:::info Este artigo está disponível no arxiv sob a licença CC by 4.0 Deed (Atribuição 4.0 Internacional).
:::
\


Você também pode gostar

Range huy động 8,3 triệu USD Series A do TX Ventures dẫn đầu

A Copa do Mundo de 2026 tem uma arma secreta contra os cambistas — e funciona na Avalanche

A EarnOS angaria 18,5 milhões de dólares para expandir a plataforma de envolvimento verificado



