

DiverGen Torna o Treino de Segmentação de Instâncias em Grande Escala Mais Eficaz
:::info Autores:
(1) Chengxiang Fan, com contribuição igual da Universidade de Zhejiang, China;
(2) Muzhi Zhu, com contribuição igual da Universidade de Zhejiang, China;
(3) Hao Chen, Universidade de Zhejiang, China ([email protected]);
(4) Yang Liu, Universidade de Zhejiang, China;
(5) Weijia Wu, Universidade de Zhejiang, China;
(6) Huaqi Zhang, vivo Mobile Communication Co..
(7) Chunhua Shen, Universidade de Zhejiang, China ([email protected]).
:::
Tabela de Links
Resumo e 1 Introdução
-
Trabalhos Relacionados
-
Nossa Proposta DiverGen
3.1. Análise da Distribuição de Dados
3.2. Aprimoramento da Diversidade de Dados Generativos
3.3. Pipeline Generativo
-
Experiências
4.1. Configurações
4.2. Resultados Principais
4.3. Estudos de Ablação
-
Conclusões, Agradecimentos e Referências
\ Apêndice
A. Detalhes de Implementação
B. Visualização
Resumo
A segmentação de instâncias é intensiva em dados e, à medida que a capacidade do modelo aumenta, a escala de dados torna-se crucial para melhorar a precisão. A maioria dos conjuntos de dados de segmentação de instâncias hoje requer anotação manual dispendiosa, limitando a sua escala de dados. Os modelos treinados com tais dados são propensos a sobreajuste no conjunto de treino, especialmente para categorias raras. Embora trabalhos recentes tenham explorado modelos generativos para criar conjuntos de dados sintéticos para aumento de dados, estas abordagens não aproveitam eficientemente todo o potencial dos modelos generativos.
\ Para abordar estas questões, introduzimos uma estratégia mais eficiente para construir conjuntos de dados generativos para aumento de dados, denominada DiverGen. Primeiramente, fornecemos uma explicação do papel dos dados generativos na perspetiva da discrepância de distribuição. Investigamos o impacto de diferentes dados na distribuição aprendida pelo modelo. Argumentamos que os dados generativos podem expandir a distribuição de dados que o modelo pode aprender, mitigando assim o sobreajuste. Adicionalmente, descobrimos que a diversidade dos dados generativos é crucial para melhorar o desempenho do modelo e aprimorá-la através de várias estratégias, incluindo diversidade de categorias, diversidade de prompts e diversidade de modelos generativos. Com estas estratégias, podemos escalar os dados para milhões enquanto mantemos a tendência de melhoria do desempenho do modelo. No conjunto de dados LVIS, o DiverGen supera significativamente o modelo forte X-Paste, alcançando +1,1 box AP e +1,1 mask AP em todas as categorias, e +1,9 box AP e +2,5 mask AP para categorias raras. Os nossos códigos estão disponíveis em https://github.com/aim-uofa/DiverGen.
1. Introdução
A segmentação de instâncias [2, 4, 9] é uma das tarefas desafiadoras na visão computacional, exigindo a previsão de máscaras e categorias para instâncias numa imagem, que serve como base para numerosas aplicações visuais. À medida que as capacidades de aprendizagem dos modelos melhoram, a demanda por dados de treino aumenta. No entanto, os conjuntos de dados atuais para segmentação de instâncias dependem fortemente de anotação manual, que é demorada e dispendiosa, e a escala do conjunto de dados não pode atender às necessidades de treino dos modelos. Apesar do recente surgimento do conjunto de dados anotado automaticamente SA-1B [12], ele carece de anotações de categoria, não atendendo aos requisitos de segmentação de instâncias. Enquanto isso, o desenvolvimento contínuo do modelo generativo melhorou significativamente a controlabilidade e o realismo das amostras geradas. Por exemplo, o recente modelo de difusão text2image [22, 24] pode gerar imagens de alta qualidade correspondentes aos prompts de entrada. Portanto, os métodos atuais [27, 28, 34] usam modelos generativos para aumento de dados, gerando conjuntos de dados para complementar o treino de modelos em conjuntos de dados reais e melhorar o desempenho do modelo. Embora os métodos atuais tenham proposto várias estratégias para permitir que os dados generativos impulsionem o desempenho do modelo, ainda existem algumas limitações: 1) Os métodos existentes não exploraram totalmente o potencial dos modelos generativos. Primeiro, alguns métodos [34] não apenas usam dados generativos, mas também precisam rastrear imagens da internet, o que é significativamente desafiador para obter dados em larga escala. Enquanto isso, o conteúdo dos dados rastreados da internet é incontrolável e precisa de verificação extra. Segundo, os métodos existentes não utilizam totalmente a controlabilidade dos modelos generativos. Os métodos atuais frequentemente adotam modelos projetados manualmente para construir prompts, limitando a saída potencial dos modelos generativos. 2) Os métodos existentes [27, 28] frequentemente explicam o papel dos dados generativos da perspetiva do desequilíbrio de classes ou escassez de dados, sem considerar a discrepância entre dados do mundo real e dados generativos. Além disso, esses métodos tipicamente mostram desempenho de modelo melhorado apenas em cenários com um número limitado de amostras reais, e a eficácia dos dados generativos em conjuntos de dados reais de larga escala existentes, como LVIS [8], não é investigada minuciosamente.
\ Neste artigo, primeiro exploramos o papel dos dados generativos da perspetiva da discrepância de distribuição, abordando duas questões principais: 1) Por que o aumento de dados generativos melhora o desempenho do modelo? 2) Que tipos de dados generativos são benéficos para melhorar o desempenho do modelo? Primeiro, descobrimos que existem discrepâncias entre a distribuição aprendida pelo modelo dos dados de treino reais limitados e a distribuição dos dados do mundo real. Visualizamos os dados e descobrimos que, em comparação com os dados do mundo real, os dados generativos podem expandir a distribuição de dados que o modelo pode aprender. Além disso, descobrimos que o papel de adicionar dados generativos é aliviar o viés dos dados de treino reais, mitigando efetivamente o sobreajuste dos dados de treino. Segundo, descobrimos que também existem discrepâncias entre a distribuição dos dados generativos e a distribuição dos dados do mundo real. Se essas discrepâncias não forem tratadas adequadamente, o potencial total do modelo generativo não pode ser utilizado. Ao conduzir vários experimentos, descobrimos que usar dados generativos diversos permite que os modelos se adaptem melhor a essas discrepâncias, melhorando o desempenho do modelo.
\ Com base na análise acima, propomos uma estratégia eficiente para aprimorar a diversidade de dados, nomeadamente, Aprimoramento da Diversidade de Dados Generativos. Projetamos várias estratégias de aprimoramento de diversidade para aumentar a diversidade de dados das perspetivas de diversidade de categorias, diversidade de prompts e diversidade de modelos generativos. Para diversidade de categorias, observamos que modelos treinados com dados generativos cobrindo todas as categorias se adaptam melhor à discrepância de distribuição do que modelos treinados com categorias parciais. Portanto, introduzimos não apenas categorias do LVIS [8], mas também categorias extras do ImageNet-1K [23] para aprimorar a diversidade de categorias na geração de dados, reforçando assim a adaptabilidade do modelo à discrepância de distribuição. Para diversidade de prompts, descobrimos que à medida que a escala do conjunto de dados generativo aumenta, os prompts projetados manualmente não podem escalar para o nível correspondente, limitando a diversidade de imagens de saída do modelo generativo. Assim, projetamos um conjunto de estratégias diversas de geração de prompts para usar grandes modelos de linguagem, como ChatGPT, para geração de prompts, exigindo que os grandes modelos de linguagem produzam prompts maximamente diversos sob restrições. Ao combinar prompts projetados manualmente e prompts projetados pelo ChatGPT, enriquecemos efetivamente a diversidade de prompts e melhoramos ainda mais a diversidade de dados generativos. Para diversidade de modelos generativos, descobrimos que dados de diferentes modelos generativos também exibem discrepâncias de distribuição. Expor modelos a dados de diferentes modelos generativos durante o treino pode aprimorar a adaptabilidade a diferentes distribuições. Portanto, empregamos Stable Diffusion [22] e DeepFloyd-IF [24] para gerar imagens para todas as categorias separadamente e misturamos os dois tipos de dados durante o treino para aumentar a diversidade de dados.
\ Ao mesmo tempo, otimizamos o fluxo de trabalho de geração de dados e propomos um pipeline generativo de quatro estágios consistindo em geração de instâncias, anotação de instâncias, filtração de instâncias e aumento de instâncias. No estágio de geração de instâncias, empregamos nosso Aprimoramento da Diversidade de Dados Generativos proposto para aprimorar a diversidade de dados, produzindo dados brutos diversos. No estágio de anotação de instâncias, introduzimos uma estratégia de anotação chamada SAM-background. Esta estratégia obtém anotações de alta qualidade usando pontos de fundo como prompts de entrada para SAM [12], obtendo as anotações dos dados brutos. No estágio de filtração de instâncias, introduzimos uma métrica chamada inter-similaridade CLIP. Utilizando o codificador de imagem CLIP [21], extraímos embeddings de dados generativos e reais, e então calculamos sua similaridade. Uma similaridade mais baixa indica qualidade de dados mais baixa. Após a filtração, obtemos o conjunto de dados generativo final. No estágio de aumento de instâncias, usamos a estratégia de colagem de instâncias [34] para aumentar a eficiência de aprendizagem do modelo em dados generativos.
\ Experimentos demonstram que nossas estratégias de diversidade de dados projetadas podem melhorar efetivamente o desempenho do modelo e manter a tendência de ganhos de desempenho à medida que a escala de dados aumenta para o nível de milhões, o que permite dados generativos em larga escala para aumento de dados. No conjunto de dados LVIS, o DiverGen supera significativamente o modelo forte X-Paste [34], alcançando +1,1 box AP [8] e +1,1 mask AP em todas as categorias, e +1,9 box AP e +2,5 mask AP para categorias raras.
\ Em resumo, nossas principais contribuições são as seguintes:
\ • Explicamos o papel dos dados generativos da perspetiva da discrepância de distribuição. Descobrimos que os dados generativos podem expandir a distribuição de dados que o modelo pode aprender, mitigando o sobreajuste do conjunto de treino e a diversidade dos dados generativos é crucial para melhorar o desempenho do modelo.
\ • Propomos a estratégia de Aprimoramento da Diversidade de Dados Generativos para aumentar a diversidade de dados dos aspetos de diversidade de categorias, diversidade de prompts e diversidade de modelos generativos. Ao aprimorar a diversidade de dados, podemos escalar os dados para milhões enquanto mantemos a tendência de melhoria do desempenho do modelo.
\ • Otimizamos o pipeline de geração de dados. Propomos uma estratégia de anotação SAM-background para obter anotações de maior qualidade. Também introduzimos uma métrica de filtração chamada inter-similaridade CLIP para filtrar dados e melhorar ainda mais a qualidade do conjunto de dados generativo.
2. Trabalhos Relacionados
Segmentação de instâncias. A segmentação de instâncias é uma tarefa importante no campo da visão computacional e tem sido extensivamente estudada. Ao contrário da segmentação semântica, a segmentação de instâncias não apenas classifica os pixels em nível de pixel, mas também distingue diferentes instâncias da mesma categoria. Anteriormente, o foco da pesquisa de segmentação de instâncias tem sido principalmente no design de estruturas de modelo. Mask-RCNN [9] unifica as tarefas de deteção de objetos e segmentação de instâncias. Subsequentemente, Mask2Former [4] unificou ainda mais as tarefas de segmentação semântica e segmentação de instâncias aproveitando a estrutura do DETR [2].
\ Ortogonal a esses estudos focados na arquitetura do modelo, nosso trabalho investiga principalmente como utilizar melhor os dados gerados para esta tarefa. Focamos no desafiador
\ 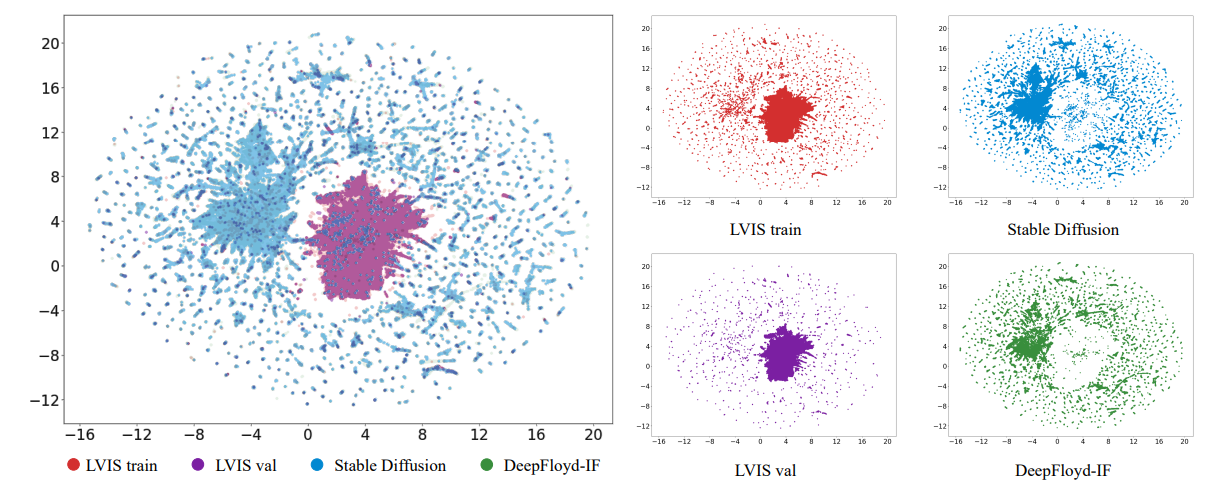
\ conjunto de dados de cauda longa LVIS [8] porque são apenas as categorias de cauda longa que enfrentam o problema de dados reais limitados e requerem imagens generativas para aumento, tornando-o mais significativo na prática.
\ Aumento de dados generativos. O uso de modelos generativos para sintetizar dados de treino para auxiliar tarefas de perceção como classificação [6, 32], deteção [3, 34], segmentação [14, 27, 28], etc. tem receb
Você também pode gostar

Top 7 Criptomoedas populares impulsionam mercados, mas MOBU conquista o trono para a pré-venda de Criptomoeda imperdível de 2025

Especialistas preveem que o preço do Bitcoin irá subir em direção aos $100K após o vencimento das opções
