

Extração Semântica de Conjunto Aberto: Pipeline Grounded-SAM, CLIP e DINOv2
Tabela de Links
Resumo e 1 Introdução
-
Trabalhos Relacionados
2.1. Navegação de Visão e Linguagem
2.2. Compreensão Semântica de Cena e Segmentação de Instâncias
2.3. Reconstrução de Cena 3D
-
Metodologia
3.1. Recolha de Dados
3.2. Informação Semântica de Conjunto Aberto a partir de Imagens
3.3. Criação da Representação 3D de Conjunto Aberto
3.4. Navegação Guiada por Linguagem
-
Experiências
4.1. Avaliação Quantitativa
4.2. Resultados Qualitativos
-
Conclusão e Trabalho Futuro, Declaração de Divulgação e Referências
3.2. Informação Semântica de Conjunto Aberto a partir de Imagens
\ 3.2.1. Deteção de Máscaras Semânticas e de Instâncias de Conjunto Aberto
\ O modelo Segment Anything (SAM) [21] recentemente lançado ganhou popularidade significativa entre investigadores e profissionais da indústria devido às suas capacidades de segmentação de ponta. No entanto, o SAM tende a produzir um número excessivo de máscaras de segmentação para o mesmo objeto. Adotamos o modelo Grounded-SAM [32] para a nossa metodologia para resolver este problema. Este processo envolve a geração de um conjunto de máscaras em três etapas, como ilustrado na Figura 2. Inicialmente, um conjunto de etiquetas de texto é criado usando o modelo Recognizing Anything (RAM) [33]. Subsequentemente, caixas delimitadoras correspondentes a estas etiquetas são criadas usando o modelo Grounding DINO [25]. A imagem e as caixas delimitadoras são então inseridas no SAM para gerar máscaras de segmentação agnósticas de classe para os objetos vistos na imagem. Fornecemos uma explicação detalhada desta abordagem abaixo, que efetivamente mitiga o problema de sobre-segmentação incorporando insights semânticos do RAM e Grounding-DINO.
\ O modelo RAM [33] processa a imagem RGB de entrada para produzir rotulagem semântica do objeto detetado na imagem. É um modelo fundamental robusto para etiquetagem de imagens, demonstrando notável capacidade zero-shot em identificar com precisão várias categorias comuns. A saída deste modelo associa cada imagem de entrada com um conjunto de etiquetas que descrevem as categorias de objetos na imagem. O processo começa com o acesso à imagem de entrada e conversão para o espaço de cores RGB, depois redimensionada para se adequar aos requisitos de entrada do modelo, e finalmente transformando-a num tensor, tornando-a compatível com a análise pelo modelo. Após isto, o modelo RAM gera etiquetas, ou tags, que descrevem os vários objetos ou características presentes na imagem. Um processo de filtração é empregado para refinar as etiquetas geradas, que envolve a remoção de classes indesejadas destas etiquetas. Especificamente, tags irrelevantes como "parede", "chão", "teto" e "escritório" são descartadas, juntamente com outras classes predefinidas consideradas desnecessárias para o contexto do estudo. Adicionalmente, esta etapa permite a ampliação do conjunto de etiquetas com quaisquer classes necessárias não inicialmente detetadas pelo modelo RAM. Finalmente, toda a informação pertinente é agregada num formato estruturado. Especificamente, cada imagem é catalogada dentro do dicionário img_dict, que regista o caminho da imagem juntamente com o conjunto de etiquetas geradas, garantindo assim um repositório acessível de dados para análise subsequente.
\ Após a etiquetagem da imagem de entrada com etiquetas geradas, o fluxo de trabalho progride invocando o modelo Grounding DINO [25]. Este modelo especializa-se em fundamentar frases textuais para regiões específicas dentro de uma imagem, delineando efetivamente objetos-alvo com caixas delimitadoras. Este processo identifica e localiza espacialmente objetos dentro da imagem, estabelecendo as bases para análises mais granulares. Após identificar e localizar objetos via caixas delimitadoras, o Segment Anything Model (SAM) [21] é empregado. A função primária do modelo SAM é gerar máscaras de segmentação para os objetos dentro destas caixas delimitadoras. Ao fazer isso, o SAM isola objetos individuais, permitindo uma análise mais detalhada e específica do objeto, separando efetivamente os objetos do seu fundo e uns dos outros dentro da imagem.
\ Neste ponto, instâncias de objetos foram identificadas, localizadas e isoladas. Cada objeto é identificado com vários detalhes, incluindo as coordenadas da caixa delimitadora, um termo descritivo para o objeto, a probabilidade ou pontuação de confiança da existência do objeto expressa em logits, e a máscara de segmentação. Além disso, cada objeto está associado a características de incorporação CLIP e DINOv2, detalhes dos quais são elaborados na subsecção seguinte.
\ 3.2.2. A Extração de Incorporação Semântica
\ Para melhorar a nossa compreensão dos aspetos semânticos das instâncias de objetos que foram segmentados e mascarados dentro das nossas imagens, empregamos dois modelos, CLIP [9] e DINOv2 [10], para derivar as representações de características das imagens recortadas de cada objeto. Um modelo treinado exclusivamente com CLIP alcança uma compreensão semântica robusta de imagens, mas não consegue discernir profundidade e detalhes intrincados dentro dessas imagens. Por outro lado, o DINOv2 demonstra desempenho superior na perceção de profundidade e destaca-se na identificação de relações nuançadas a nível de pixel entre imagens. Como um Vision Transformer auto-supervisionado, o DINOv2 pode extrair detalhes de características nuançadas sem depender de dados anotados, tornando-o particularmente eficaz na identificação de relações espaciais e hierarquias dentro de imagens. Por exemplo, enquanto o modelo CLIP pode ter dificuldade em diferenciar entre duas cadeiras de cores diferentes, como vermelho e verde, as capacidades do DINOv2 permitem que tais distinções sejam feitas claramente. Para concluir, estes modelos capturam tanto as características semânticas quanto visuais dos objetos, que são posteriormente utilizadas para comparações de similaridade no espaço 3D.
\ 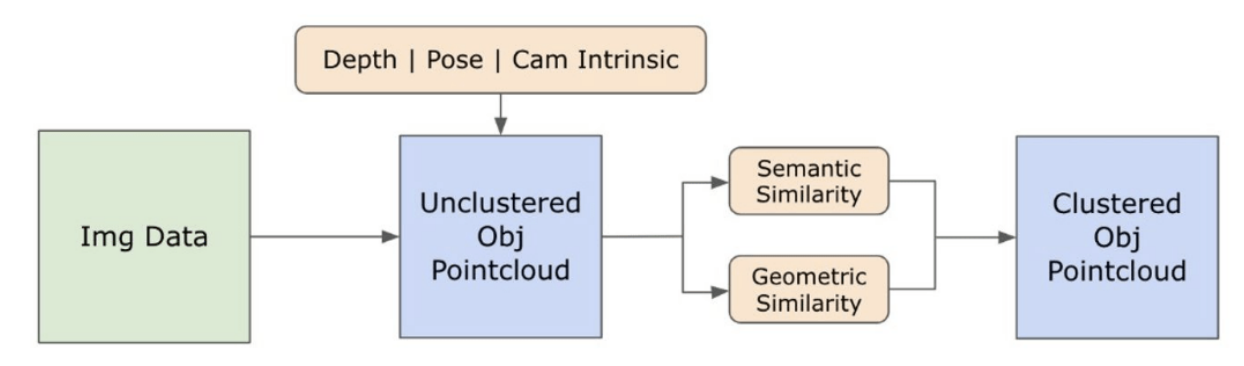
\ Um conjunto de etapas de pré-processamento é implementado para processar imagens com o modelo DINOv2. Estas incluem redimensionamento, recorte central, conversão da imagem para um tensor e normalização das imagens recortadas delineadas pelas caixas delimitadoras. A imagem processada é então alimentada no modelo DINOv2 juntamente com etiquetas identificadas pelo modelo RAM para gerar as características de incorporação DINOv2. Por outro lado, ao lidar com o modelo CLIP, a etapa de pré-processamento envolve transformar a imagem recortada num formato de tensor compatível com CLIP, seguido pelo cálculo de características de incorporação. Estas incorporações são críticas, pois encapsulam os atributos visuais e semânticos dos objetos, que são cruciais para uma compreensão abrangente dos objetos na cena. Estas incorporações passam por normalização baseada na sua norma L2, que ajusta o vetor de características para um comprimento unitário padronizado. Esta etapa de normalização permite comparações consistentes e justas entre diferentes imagens.
\ Na fase de implementação desta etapa, iteramos sobre cada imagem dentro dos nossos dados e executamos os procedimentos subsequentes:
\ (1) A imagem é recortada para a região de interesse usando as coordenadas da caixa delimitadora fornecidas pelo modelo Grounding DINO, isolando o objeto para análise detalhada.
\ (2) Gerar incorporações DINOv2 e CLIP para a imagem recortada.
\ (3) Finalmente, as incorporações são armazenadas juntamente com as máscaras da secção anterior.
\ Com estas etapas concluídas, agora possuímos representações detalhadas de características para cada objeto, enriquecendo nosso conjunto de dados para análise e aplicação adicionais.
\
:::info Autores:
(1) Laksh Nanwani, International Institute of Information Technology, Hyderabad, Índia; este autor contribuiu igualmente para este trabalho;
(2) Kumaraditya Gupta, International Institute of Information Technology, Hyderabad, Índia;
(3) Aditya Mathur, International Institute of Information Technology, Hyderabad, Índia; este autor contribuiu igualmente para este trabalho;
(4) Swayam Agrawal, International Institute of Information Technology, Hyderabad, Índia;
(5) A.H. Abdul Hafez, Hasan Kalyoncu University, Sahinbey, Gaziantep, Turquia;
(6) K. Madhava Krishna, International Institute of Information Technology, Hyderabad, Índia.
:::
:::info Este artigo está disponível no arxiv sob a licença CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International).
:::
\
Você também pode gostar

Nexo adquire corretora cripto argentina e promete expandir operações na América Latina
Shiba Inu pode valorizar 25x novamente, mas as perspetivas da Ozak AI para 2026 parecem muito mais explosivas
