

Превосходя полную тонкую настройку всего с 0,2% параметров
Таблица ссылок
Резюме и 1. Введение
-
Предпосылки
2.1 Смесь экспертов
2.2 Адаптеры
-
Смесь адаптаций
3.1 Политика маршрутизации
3.2 Регуляризация согласованности
3.3 Объединение модулей адаптации и 3.4 Совместное использование модулей адаптации
3.5 Связь с байесовскими нейронными сетями и ансамблированием моделей
-
Эксперименты
4.1 Экспериментальная установка
4.2 Ключевые результаты
4.3 Исследование методом абляции
-
Связанные работы
-
Выводы
-
Ограничения
-
Благодарности и ссылки
Приложение
A. Наборы данных для few-shot NLU B. Исследование методом абляции C. Подробные результаты по задачам NLU D. Гиперпараметры
5 Связанные работы
Параметрически эффективная тонкая настройка PLM. Недавние работы по параметрически эффективной тонкой настройке (PEFT) можно примерно разделить на две
\ 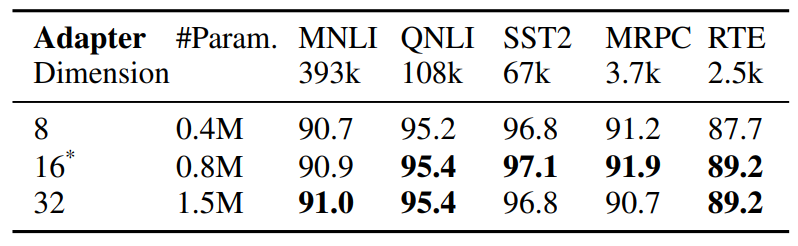
\ категории: (1) настройка подмножества существующих параметров, включая тонкую настройку головы (Lee et al., 2019), настройку смещения (Zaken et al., 2021), (2) настройка вновь введенных параметров, включая адаптеры (Houlsby et al., 2019; Pfeiffer et al., 2020), настройку подсказок (Lester et al., 2021), префиксную настройку (Li and Liang, 2021) и низкоранговую адаптацию (Hu et al., 2021). В отличие от предыдущих работ, работающих с одним модулем адаптации, AdaMix вводит смесь модулей адаптации со стохастической маршрутизацией во время обучения и объединением модулей адаптации во время вывода, чтобы сохранить те же вычислительные затраты, что и при использовании одного модуля. Кроме того, AdaMix может использоваться поверх любого метода PEFT для дальнейшего повышения его производительности.
\ Смесь экспертов (MoE). Shazeer et al., 2017 представили модель MoE с единой сетью шлюзов с маршрутизацией Top-k и балансировкой нагрузки между экспертами. Fedus et al., 2021 предлагают схемы инициализации и обучения для маршрутизации Top-1. Zuo et al., 2021 предлагают регуляризацию согласованности для случайной маршрутизации; Yang et al., 2021 предлагают маршрутизацию k Top-1 с прототипами экспертов, а Roller et al., 2021; Lewis et al., 2021 решают другие проблемы балансировки нагрузки. Все вышеперечисленные работы изучают разреженный MoE с предварительным обучением всей модели с нуля. В отличие от этого, мы изучаем параметрически эффективную адаптацию предварительно обученных языковых моделей путем настройки только очень небольшого числа разреженных параметров адаптера.
\ Усреднение весов модели. Недавние исследования (Szegedy et al., 2016; Matena and Raffel, 2021; Wortsman et al., 2022; Izmailov et al., 2018) изучают агрегацию моделей путем усреднения всех весов модели. (Matena and Raffel, 2021) предлагают объединять предварительно обученные языковые модели, которые настроены на различные задачи классификации текста. (Wortsman et al., 2022) исследует усреднение весов модели из различных независимых запусков на одной и той же задаче с различными конфигурациями гиперпараметров. В отличие от вышеупомянутых работ по полной тонкой настройке модели, мы фокусируемся на параметрически эффективной тонкой настройке. Мы исследуем усреднение весов для объединения весов модулей адаптации, состоящих из малых настраиваемых параметров, которые обновляются во время настройки модели, сохраняя при этом большие параметры модели фиксированными.
6 Выводы
Мы разработали новую структуру AdaMix для параметрически эффективной тонкой настройки (PEFT) больших предварительно обученных языковых моделей (PLM). AdaMix использует смесь модулей адаптации для улучшения производительности последующих задач без увеличения вычислительных затрат (например, FLOPs, параметров) базового метода адаптации. Мы демонстрируем, что AdaMix работает и улучшает различные методы PEFT, такие как адаптеры и низкоранговые разложения для задач NLU и NLG.
\ Настраивая только 0,1 − 0,2% параметров PLM, AdaMix превосходит полную тонкую настройку модели, которая обновляет все параметры модели, а также другие современные методы PEFT.
7 Ограничения
Предложенный метод AdaMix является в некоторой степени вычислительно интенсивным, поскольку он включает тонкую настройку крупномасштабных языковых моделей. Стоимость обучения предложенного AdaMix выше, чем у стандартных методов PEFT, поскольку процедура обучения включает несколько копий адаптеров. На основе наших эмпирических наблюдений, количество итераций обучения для AdaMix обычно составляет от 1 до 2 раз больше, чем обучение для стандартных методов PEFT. Это оказывает негативное влияние на углеродный след от обучения описанных моделей.
\ AdaMix ортогонален большинству существующих исследований параметрически эффективной тонкой настройки (PEFT) и потенциально способен улучшить производительность любого метода PEFT. В этой работе мы исследуем два репрезентативных метода PEFT, такие как адаптер и LoRA, но мы не экспериментировали с другими комбинациями, такими как настройка подсказок и префиксная настройка. Мы оставляем эти исследования для будущей работы.
8 Благодарности
Авторы хотели бы поблагодарить анонимных рецензентов за их ценные комментарии и полезные предложения, а также хотели бы поблагодарить Guoqing Zheng и Ruya Kang за их проницательные комментарии к проекту. Эта работа частично поддержана Национальным научным фондом США в рамках грантов NSFIIS 1747614 и NSF-IIS-2141037. Любые мнения, выводы и заключения или рекомендации, выраженные в этом материале, принадлежат автору(ам) и не обязательно отражают точку зрения Национального научного фонда.
Ссылки
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. 2021. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7319– 7328, Online. Association for Computational Linguistics.
\ Roy Bar Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. 2006. The second PASCAL recognising textual entailment challenge.
\ Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. 2009. The fifth PASCAL recognizing textual entailment challenge. In TAC.
\ Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel HerbertVoss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
\ Ido Dagan, Oren Glickman, and Bernardo Magnini. 2005. The PASCAL recognising textual entailment challenge. In the First International Conference on Machine Learning Challenges: Evaluating Predictive Uncertainty Visual Object Classification, and Recognizing Textual Entailment.
\ Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Volume 1 (Long and Short Papers), pages 4171–4186.
\ William Fedus, Barret Zoph, and Noam Shazeer. 2021. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv preprint arXiv:2101.03961.
\ Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. 2020. Linear mode connectivity and the lottery ticket hypothesis. In International Conference on Machine Learning, pages 3259–3269. PMLR.
\ Yarin Gal and Zoubin Ghahramani. 2015. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. CoRR, abs/1506.02142.
\ Yarin Gal, Riashat Islam, and Zoubin Ghahramani. 2017. Deep Bayesian active learning with image data. In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1183–1192. PMLR.
\ Tianyu Gao, Adam Fisch, and Danqi Chen. 2021. Making pre-trained language models better few-shot learners. In Association for Computational Linguistics (ACL).
\ Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. 2017. The webnlg challenge: Generating text from rdf data. In Proceedings of the 10th International Conference on Natural Language Generation, pages 124–133.
\ Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and Bill Dolan. 2007. The third PASCAL recognizing textual entailment challenge. In the ACLPASCAL Workshop on Textual Entailment and Paraphrasing.
\ Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR.
\ Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
\ Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. 2018. Averaging weights leads to wider optima and better generalization. arXiv preprint arXiv:1803.05407.
\ Jaejun Lee, Raphael
Вам также может быть интересно
Tether выходит на спортивный рынок, делает предложение о покупке футбольного клуба Ювентус

Влияние повышения ставки Банка Японии на Биткоин
