

Синтез медицинских изображений: S-CycleGAN для RUSS и сегментации

Таблица ссылок
Резюме и 1 Введение
-
Связанные работы
-
Постановка проблемы
-
Методология
4.1. Дистилляция с учетом границы принятия решений
4.2. Консолидация знаний
-
Экспериментальные результаты и 5.1. Настройка эксперимента
5.2. Сравнение с методами SOTA
5.3. Исследование абляции
-
Заключение и дальнейшая работа и Ссылки
\
Дополнительные материалы
- Детали теоретического анализа механизма KCEMA в IIL
- Обзор алгоритма
- Детали набора данных
- Детали реализации
- Визуализация запыленных входных изображений
- Больше экспериментальных результатов
4. Методология
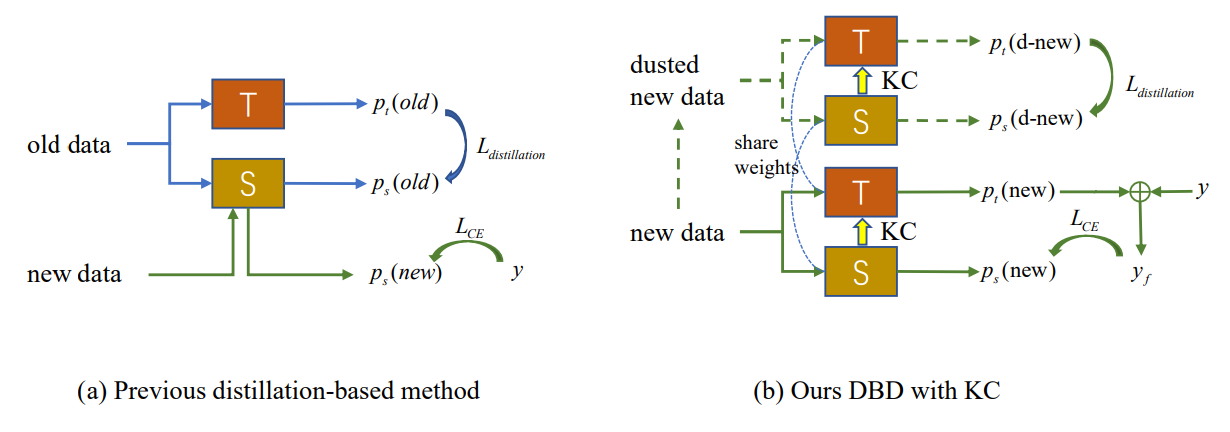
Как показано на Рис. 2 (a), возникновение концептуального дрейфа в новых наблюдениях приводит к появлению внешних образцов, с которыми существующая модель не справляется. Новый IIL должен расширить границу принятия решений до этих внешних образцов, а также избежать катастрофического забывания (CF) на старой границе. Традиционные методы, основанные на дистилляции знаний, полагаются на некоторые сохраненные примеры [22] или вспомогательные данные [33, 34] для противодействия CF. Однако в предложенной настройке IIL у нас нет доступа к каким-либо старым данным, кроме новых наблюдений. Дистилляция, основанная на этих новых наблюдениях, конфликтует с изучением новых знаний, если в модель не добавляются новые параметры. Чтобы найти баланс между обучением и отсутствием забывания, мы предлагаем метод дистилляции с учетом границы принятия решений, который не требует старых данных. Во время обучения новые знания, полученные учеником, периодически консолидируются обратно в модель учителя, что обеспечивает лучшую обобщаемость и является пионерской попыткой в этой области.
\ 
\
:::info Авторы:
(1) Цян Не, Гонконгский университет науки и технологии (Гуанчжоу);
(2) Вэйфу Фу, Лаборатория Tencent Youtu;
(3) Юхуань Линь, Лаборатория Tencent Youtu;
(4) Цзялинь Ли, Лаборатория Tencent Youtu;
(5) Ифэн Чжоу, Лаборатория Tencent Youtu;
(6) Юн Лю, Лаборатория Tencent Youtu;
(7) Цян Не, Гонконгский университет науки и технологии (Гуанчжоу);
(8) Чэнцзе Ван, Лаборатория Tencent Youtu.
:::
:::info Эта статья доступна на arxiv под лицензией CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
\
Вам также может быть интересно

Это не может быть только Гарольд: тренер UP призывает к большему вкладу в Игре 2

State Street и Galaxy запускают токенизированный фонд ликвидности с инвестициями Ondo в размере 200M долларов
