

Перемога над повним дотренуванням з використанням лише 0,2% параметрів
Таблиця посилань
Анотація та 1. Вступ
-
Передумови
2.1 Суміш експертів
2.2 Адаптери
-
Суміш адаптацій
3.1 Політика маршрутизації
3.2 Регуляризація узгодженості
3.3 Об'єднання модулів адаптації та 3.4 Спільне використання модулів адаптації
3.5 Зв'язок з байєсівськими нейронними мережами та ансамблюванням моделей
-
Експерименти
4.1 Експериментальна установка
4.2 Ключові результати
4.3 Дослідження абляції
-
Пов'язані роботи
-
Висновки
-
Обмеження
-
Подяка та посилання
Додаток
A. Набори даних NLU з малою кількістю прикладів B. Дослідження абляції C. Детальні результати завдань NLU D. Гіперпараметри
5 Пов'язані роботи
Параметрично-ефективне точне налаштування PLM. Останні роботи з параметрично-ефективного точного налаштування (PEFT) можна приблизно розділити на дві
\ 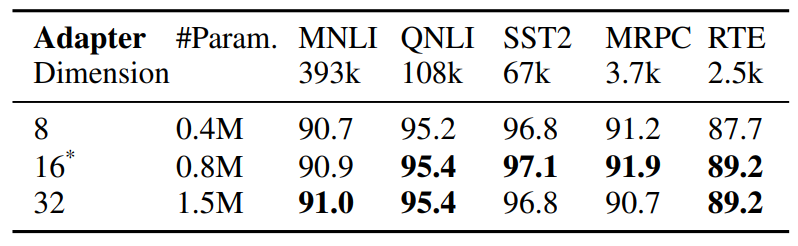
\ категорії: (1) налаштування підмножини існуючих параметрів, включаючи точне налаштування головної частини (Lee et al., 2019), налаштування зміщення (Zaken et al., 2021), (2) налаштування нових параметрів, включаючи адаптери (Houlsby et al., 2019; Pfeiffer et al., 2020), налаштування підказок (Lester et al., 2021), префіксне налаштування (Li and Liang, 2021) та низькорангову адаптацію (Hu et al., 2021). На відміну від попередніх робіт, що працюють з одним модулем адаптації, AdaMix вводить суміш модулів адаптації зі стохастичною маршрутизацією під час навчання та об'єднанням модулів адаптації під час виведення, щоб зберегти ті ж обчислювальні витрати, що й з одним модулем. Крім того, AdaMix можна використовувати поверх будь-якого методу PEFT для подальшого підвищення його продуктивності.
\ Суміш експертів (MoE). Shazeer et al., 2017 представили модель MoE з єдиною мережею шлюзування з маршрутизацією T op-k та балансуванням навантаження між експертами. Fedus et al., 2021 пропонують схеми ініціалізації та навчання для маршрутизації T op-1. Zuo et al., 2021 пропонують регуляризацію узгодженості для випадкової маршрутизації; Yang et al., 2021 пропонують маршрутизацію k T op-1 з прототипами експертів, а Roller et al., 2021; Lewis et al., 2021 вирішують інші проблеми балансування навантаження. Усі вищезгадані роботи вивчають розріджений MoE з попереднім навчанням всієї моделі з нуля. На відміну від цього, ми вивчаємо параметрично-ефективну адаптацію попередньо навчених мовних моделей, налаштовуючи лише дуже малу кількість розріджених параметрів адаптера.
\ Усереднення ваг моделі. Останні дослідження (Szegedy et al., 2016; Matena and Raffel, 2021; Wortsman et al., 2022; Izmailov et al., 2018) вивчають агрегацію моделей шляхом усереднення всіх ваг моделі. (Matena and Raffel, 2021) пропонують об'єднувати попередньо навчені мовні моделі, які точно налаштовані на різних завданнях класифікації тексту. (Wortsman et al., 2022) досліджує усереднення ваг моделі з різних незалежних запусків на одному завданні з різними конфігураціями гіперпараметрів. На відміну від вищезгаданих робіт з повним точним налаштуванням моделі, ми зосереджуємося на параметрично-ефективному точному налаштуванні. Ми досліджуємо усереднення ваг для об'єднання ваг модулів адаптації, що складаються з малих налаштовуваних параметрів, які оновлюються під час налаштування моделі, зберігаючи при цьому великі параметри моделі фіксованими.
6 Висновки
Ми розробили нову структуру AdaMix для параметрично-ефективного точного налаштування (PEFT) великих попередньо навчених мовних моделей (PLM). AdaMix використовує суміш модулів адаптації для покращення продуктивності завдань без збільшення обчислювальних витрат (наприклад, FLOPs, параметрів) базового методу адаптації. Ми демонструємо, що AdaMix працює та покращує різні методи PEFT, такі як адаптери та низькорангові розкладання для завдань NLU та NLG.
\ Налаштовуючи лише 0,1 − 0,2% параметрів PLM, AdaMix перевершує повне точне налаштування моделі, яке оновлює всі параметри моделі, а також інші сучасні методи PEFT.
7 Обмеження
Запропонований метод AdaMix є дещо обчислювально інтенсивним, оскільки він включає точне налаштування великомасштабних мовних моделей. Вартість навчання запропонованого AdaMix вища, ніж у стандартних методів PEFT, оскільки процедура навчання включає кілька копій адаптерів. На основі наших емпіричних спостережень, кількість ітерацій навчання для AdaMix зазвичай становить від 1 до 2 разів навчання для стандартних методів PEFT. Це негативно впливає на вуглецевий слід від навчання описаних моделей.
\ AdaMix є ортогональним до більшості існуючих досліджень параметрично-ефективного точного налаштування (PEFT) і потенційно може покращити продуктивність будь-якого методу PEFT. У цій роботі ми досліджуємо два репрезентативні методи PEFT, такі як адаптер та LoRA, але ми не експериментували з іншими комбінаціями, такими як налаштування підказок та префіксне налаштування. Ми залишаємо ці дослідження для майбутньої роботи.
8 Подяка
Автори хотіли б подякувати анонімним рецензентам за їхні цінні коментарі та корисні пропозиції, а також подякувати Guoqing Zheng та Ruya Kang за їхні проникливі коментарі до проєкту. Ця робота частково підтримується Національним науковим фондом США за грантами NSFIIS 1747614 та NSF-IIS-2141037. Будь-які думки, висновки та рекомендації, висловлені в цьому матеріалі, належать автору(ам) і не обов'язково відображають погляди Національного наукового фонду.
Посилання
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. 2021. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7319– 7328, Online. Association for Computational Linguistics.
\ Roy Bar Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. 2006. The second PASCAL recognising textual entailment challenge.
\ Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. 2009. The fifth PASCAL recognizing textual entailment challenge. In TAC.
\ Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel HerbertVoss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
\ Ido Dagan, Oren Glickman, and Bernardo Magnini. 2005. The PASCAL recognising textual entailment challenge. In the First International Conference on Machine Learning Challenges: Evaluating Predictive Uncertainty Visual Object Classification, and Recognizing Textual Entailment.
\ Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Volume 1 (Long and Short Papers), pages 4171–4186.
\ William Fedus, Barret Zoph, and Noam Shazeer. 2021. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv preprint arXiv:2101.03961.
\ Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. 2020. Linear mode connectivity and the lottery ticket hypothesis. In International Conference on Machine Learning, pages 3259–3269. PMLR.
\ Yarin Gal and Zoubin Ghahramani. 2015. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. CoRR, abs/1506.02142.
\ Yarin Gal, Riashat Islam, and Zoubin Ghahramani. 2017. Deep Bayesian active learning with image data. In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1183–1192. PMLR.
\ Tianyu Gao, Adam Fisch, and Danqi Chen. 2021. Making pre-trained language models better few-shot learners. In Association for Computational Linguistics (ACL).
\ Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. 2017. The webnlg challenge: Generating text from rdf data. In Proceedings of the 10th International Conference on Natural Language Generation, pages 124–133.
\ Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and Bill Dolan. 2007. The third PASCAL recognizing textual entailment challenge. In the ACLPASCAL Workshop on Textual Entailment and Paraphrasing.
\ Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR.
\ Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.
Вам також може сподобатися

Bitcoin на позначці $90K, оскільки Палата представників тисне на SEC щодо криптовалют у пенсійних планах 401(k)

Стратегія Майкла Сейлора забезпечує місце в Nasdaq 100, поки наближається рішення MSCI
