

Виявлення аномалій на основі трансформерів з використанням вбудовувань послідовностей журналів

Table of links
Анотація
1 Introduction
2 Background and Related Work
2.1 Different Formulations of the Log-based Anomaly Detection Task
2.2 Supervised v.s. Unsupervised
2.3 Information within Log Data
2.4 Fix-Window Grouping
2.5 Related Works
3 A Configurable Transformer-based Anomaly Detection Approach
3.1 Problem Formulation
3.2 Log Parsing and Log Embedding
3.3 Positional & Temporal Encoding
3.4 Model Structure
3.5 Supervised Binary Classification
4 Experimental Setup
4.1 Datasets
4.2 Evaluation Metrics
4.3 Generating Log Sequences of Varying Lengths
4.4 Implementation Details and Experimental Environment
5 Experimental Results
5.1 RQ1: How does our proposed anomaly detection model perform compared to the baselines?
5.2 RQ2: How much does the sequential and temporal information within log sequences affect anomaly detection?
5.3 RQ3: How much do the different types of information individually contribute to anomaly detection?
6 Discussion
7 Threats to validity
8 Conclusions and References
\
3 A Configurable Transformer-based Anomaly Detection Approach
У цьому дослідженні ми представляємо новий метод виявлення аномалій на основі трансформера. Модель приймає послідовності логів як вхідні дані для виявлення аномалій. Модель використовує попередньо навчену модель BERT для вбудовування шаблонів логів, що дозволяє представляти семантичну інформацію в повідомленнях логів. Ці вбудовування, поєднані з позиційним або часовим кодуванням, потім подаються на вхід моделі трансформера. Об'єднана інформація використовується в подальшому створенні представлень на рівні послідовності логів, що сприяє процесу виявлення аномалій. Ми розробили нашу модель гнучкою: вхідні функції можна налаштовувати, щоб ми могли використовувати або проводити експерименти з різними комбінаціями функцій даних логів. Крім того, модель розроблена та навчена для обробки вхідних послідовностей логів різної довжини. У цьому розділі ми представляємо формулювання нашої проблеми та детальний дизайн нашого методу.
\ 3.1 Problem Formulation
Ми слідуємо попереднім роботам [1], щоб сформулювати завдання як завдання бінарної класифікації, в якому ми навчаємо нашу запропоновану модель класифікувати послідовності логів на аномальні та нормальні під наглядом. Для зразків, що використовуються в навчанні та оцінці моделі, ми використовуємо гнучкий підхід до групування для створення послідовностей логів різної довжини. Деталі представлені в розділі 4
\ 3.2 Log Parsing and Log Embedding
У нашій роботі ми перетворюємо події логів у числові вектори, кодуючи шаблони логів за допомогою попередньо навченої мовної моделі. Щоб отримати шаблони логів, ми використовуємо парсер Drain [24], який широко використовується і має хорошу продуктивність аналізу для більшості загальнодоступних наборів даних [4]. Ми використовуємо попередньо навчену модель sentence-bert [25] (тобто all-MiniLML6-v2 [26]) для вбудовування шаблонів логів, створених процесом аналізу логів. Попередньо навчена модель навчається з метою контрастного навчання і досягає найсучаснішої продуктивності в різних завданнях NLP. Ми використовуємо цю попередньо навчену модель для створення представлення, яке фіксує семантичну інформацію повідомлень логів і ілюструє схожість між шаблонами логів для моделі виявлення аномалій нижчого рівня. Вихідний розмір моделі становить 384.
\ 3.3 Positional & Temporal Encoding
Оригінальна модель трансформера [27] використовує позиційне кодування, щоб дозволити моделі використовувати порядок вхідної послідовності. Оскільки модель не містить рекурсії та згортки, моделі будуть агностичними до послідовності логів без позиційного кодування. Хоча деякі дослідження припускають, що моделі трансформерів без явного позиційного кодування залишаються конкурентоспроможними зі стандартними моделями при роботі з послідовними даними [28, 29], важливо зазначити, що будь-яка перестановка вхідної послідовності призведе до однакового внутрішнього стану моделі. Оскільки послідовна інформація або часова інформація можуть бути важливими індикаторами аномалій у послідовностях логів, попередні роботи, які базуються на моделях трансформерів, використовують стандартне позиційне кодування для введення порядку подій логів або шаблонів у послідовності [11, 12, 21], з метою виявлення аномалій, пов'язаних з неправильним порядком виконання. Однак ми помітили, що в загальновживаній реалізації репліки методу на основі трансформера [5] позиційне кодування було фактично опущено. Наскільки нам відомо, жодна існуюча робота не кодувала часову інформацію на основі часових міток логів для свого методу виявлення аномалій. Ефективність використання послідовної або часової інформації в завданні виявлення аномалій неясна.
\ У нашому запропонованому методі ми намагаємося включити послідовне та часове кодування в модель трансформера та дослідити важливість послідовної та часової інформації для виявлення аномалій. Зокрема, наш запропонований метод має різні варіанти, що використовують наступні методи послідовного або часового кодування. Кодування потім додається до представлення логу, яке служить вхідними даними для структури трансформера.
\ 
3.3.1 Relative Time Elapse Encoding (RTEE)
Ми пропонуємо цей метод часового кодування, RTEE, який просто замінює індекс позиції в позиційному кодуванні на час кожної події логу. Спочатку ми обчислюємо час, що минув, відповідно до часових міток подій логів у послідовності логів. Замість використання індексу послідовності подій логів як позиції для синусоїдальних та косинусоїдальних рівнянь, ми використовуємо відносний час, що минув до першої події логу в послідовності логів, щоб замінити індекс позиції. Таблиця 1 показує приклад часових інтервалів у послідовності логів. У прикладі ми маємо послідовність логів, що містить 7 подій з часовим проміжком 7 секунд. Час, що минув від першої події до кожної події в послідовності, використовується для обчислення часового кодування для відповідних подій. Подібно до позиційного кодування, кодування обчислюється за допомогою вищезгаданих рівнянь 1, і кодування не оновлюватиметься під час процесу навчання.
\ 
3.4 Model Structure
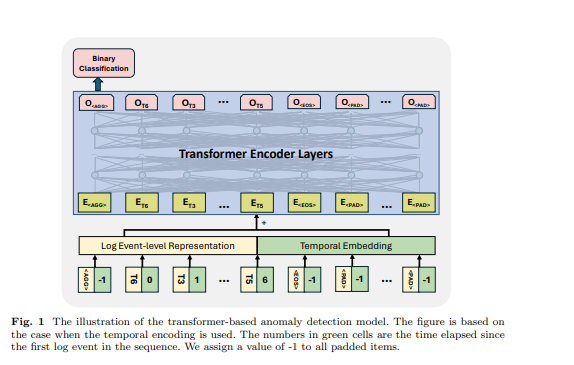
Трансформер - це архітектура нейронної мережі, яка покладається на механізм самоуваги для фіксації взаємозв'язку між вхідними елементами в послідовності. Моделі та фреймворки на основі трансформерів використовувалися в завданні виявлення аномалій багатьма попередніми роботами [6, 11, 12, 21]. Натхненні попередніми роботами, ми використовуємо модель на основі кодувальника трансформера для виявлення аномалій. Ми розробляємо наш підхід для прийняття послідовностей логів різної довжини та створення представлень на рівні послідовності. Для досягнення цього ми використали деякі специфічні токени у вхідній послідовності логів для моделі, щоб створити представлення послідовності та ідентифікувати заповнені токени та кінець послідовності логів, черпаючи натхнення з дизайну моделі BERT [31]. У вхідній послідовності логів ми використовували наступні токени: розміщується на початку кожної послідовності, щоб дозволити моделі генерувати агреговану інформацію для всієї послідовності, додається в кінці послідовності, щоб позначити її завершення, використовується для позначення маскованих токенів під парадигмою самоконтрольованого навчання, і використовується для заповнених токенів. Вбудовування для цих спеціальних токенів генеруються випадковим чином на основі розміру використовуваного представлення логу. Приклад показано на рисунку 1, час, що минув для , та встановлено на -1. Представлення на рівні події логу та позиційне або часове вбудовування підсумовуються як вхідна функція структури трансформера.
\ 3.5 Supervised Binary Classification За цією метою навчання ми використовуємо вихід першого токена моделі трансформера, ігноруючи виходи інших токенів. Цей вихід першого токена призначений для агрегації інформації всієї вхідної послідовності логів, подібно до токена моделі BERT, який забезпечує агреговане представлення послідовності токенів. Тому ми розглядаємо вихід цього токена як представлення на рівні послідовності. Ми навчаємо модель з метою бінарної класифікації (тобто Binary Cross Entropy Loss) з цим представленням.
\ 
:::info Authors:
- Xingfang Wu
- Heng Li
- Foutse Khomh
:::
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
\


Вам також може сподобатися

Експерт-аналітик: «Можливо, сезону альткоїнів більше ніколи не буде, але якщо він настане, зверніть увагу на ці дати»

SBI та Rakuten розширюють асортимент інвестиційних продуктів на основі Bitcoin та блокчейн Ethereum




