

Відкрите семантичне вилучення: конвеєр Grounded-SAM, CLIP та DINOv2
Таблиця посилань
Анотація та 1 Вступ
-
Пов'язані роботи
2.1. Навігація на основі зору та мови
2.2. Семантичне розуміння сцени та сегментація екземплярів
2.3. 3D реконструкція сцени
-
Методологія
3.1. Збір даних
3.2. Семантична інформація відкритого набору з зображень
3.3. Створення 3D-представлення відкритого набору
3.4. Навігація на основі мови
-
Експерименти
4.1. Кількісна оцінка
4.2. Якісні результати
-
Висновок та майбутня робота, Заява про розкриття інформації та Посилання
3.2. Семантична інформація відкритого набору з зображень
\ 3.2.1. Виявлення семантичних масок відкритого набору та масок екземплярів
\ Нещодавно випущена модель Segment Anything (SAM) [21] набула значної популярності серед дослідників та промислових практиків завдяки своїм передовим можливостям сегментації. Однак SAM має тенденцію створювати надмірну кількість масок сегментації для одного і того ж об'єкта. Ми використовуємо модель Grounded-SAM [32] для нашої методології, щоб вирішити цю проблему. Цей процес включає генерацію набору масок у три етапи, як показано на рисунку 2. Спочатку створюється набір текстових міток за допомогою моделі Recognizing Anything (RAM) [33]. Потім створюються обмежувальні рамки, що відповідають цим міткам, за допомогою моделі Grounding DINO [25]. Зображення та обмежувальні рамки потім подаються в SAM для створення агностичних до класу масок сегментації для об'єктів, видимих на зображенні. Ми надаємо детальне пояснення цього підходу нижче, який ефективно зменшує проблему надмірної сегментації, включаючи семантичні дані з RAM та Grounding-DINO.
\ Модель RAM [33] обробляє вхідне RGB-зображення для створення семантичного маркування об'єкта, виявленого на зображенні. Це надійна базова модель для маркування зображень, що демонструє чудову здатність до розпізнавання з нульовим прикладом для точної ідентифікації різних загальних категорій. Вихід цієї моделі пов'язує кожне вхідне зображення з набором міток, які описують категорії об'єктів на зображенні. Процес починається з доступу до вхідного зображення та перетворення його в колірний простір RGB, потім змінюється розмір, щоб відповідати вимогам вхідних даних моделі, і нарешті перетворюється в тензор, роблячи його сумісним з аналізом моделі. Після цього модель RAM генерує мітки або теги, які описують різні об'єкти або особливості, присутні на зображенні. Для уточнення згенерованих міток застосовується процес фільтрації, який включає видалення небажаних класів з цих міток. Зокрема, відкидаються нерелевантні теги, такі як "стіна", "підлога", "стеля" та "офіс", разом з іншими попередньо визначеними класами, які вважаються непотрібними для контексту дослідження. Крім того, цей етап дозволяє доповнити набір міток будь-якими необхідними класами, які спочатку не були виявлені моделлю RAM. Нарешті, вся відповідна інформація агрегується в структурований формат. Зокрема, кожне зображення каталогізується в словнику img_dict, який записує шлях зображення разом із набором згенерованих міток, забезпечуючи таким чином доступний репозиторій даних для подальшого аналізу.
\ Після маркування вхідного зображення згенерованими мітками робочий процес продовжується викликом моделі Grounding DINO [25]. Ця модель спеціалізується на прив'язці текстових фраз до конкретних областей зображення, ефективно окреслюючи цільові об'єкти обмежувальними рамками. Цей процес ідентифікує та просторово локалізує об'єкти на зображенні, закладаючи основу для більш детального аналізу. Після ідентифікації та локалізації об'єктів за допомогою обмежувальних рамок використовується модель Segment Anything (SAM) [21]. Основна функція моделі SAM полягає в створенні масок сегментації для об'єктів у цих обмежувальних рамках. Таким чином, SAM ізолює окремі об'єкти, забезпечуючи більш детальний та специфічний для об'єкта аналіз, ефективно відокремлюючи об'єкти від їх фону та один від одного на зображенні.
\ На цьому етапі екземпляри об'єктів були ідентифіковані, локалізовані та ізольовані. Кожен об'єкт ідентифікується з різними деталями, включаючи координати обмежувальної рамки, описовий термін для об'єкта, ймовірність або оцінку впевненості в існуванні об'єкта, виражену в логітах, та маску сегментації. Крім того, кожен об'єкт пов'язаний з вбудованими функціями CLIP та DINOv2, деталі яких розглядаються в наступному підрозділі.
\ 3.2.2. Вилучення семантичного вбудовування
\ Щоб покращити наше розуміння семантичних аспектів екземплярів об'єктів, які були сегментовані та замасковані в наших зображеннях, ми використовуємо дві моделі, CLIP [9] та DINOv2 [10], для отримання представлень ознак з обрізаних зображень кожного об'єкта. Модель, навчена виключно з CLIP, досягає надійного семантичного розуміння зображень, але не може розрізняти глибину та складні деталі в цих зображеннях. З іншого боку, DINOv2 демонструє кращу продуктивність у сприйнятті глибини та відмінно ідентифікує нюансовані відносини на рівні пікселів між зображеннями. Як самоконтрольований Vision Transformer, DINOv2 може витягувати нюансовані деталі ознак без опори на анотовані дані, що робить його особливо ефективним для ідентифікації просторових відносин та ієрархій у зображеннях. Наприклад, хоча модель CLIP може мати труднощі з розрізненням двох стільців різних кольорів, таких як червоний та зелений, можливості DINOv2 дозволяють чітко робити такі відмінності. На завершення, ці моделі фіксують як семантичні, так і візуальні особливості об'єктів, які пізніше використовуються для порівняння подібності в 3D-просторі.
\ 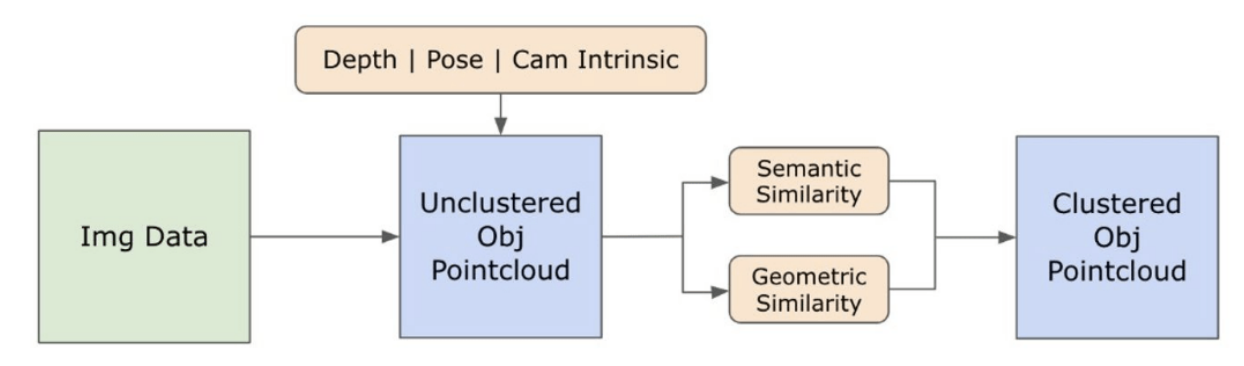
\ Набір кроків попередньої обробки реалізується для обробки зображень з моделлю DINOv2. Вони включають зміну розміру, центральне обрізання, перетворення зображення в тензор та нормалізацію обрізаних зображень, окреслених обмежувальними рамками. Оброблене зображення потім подається в модель DINOv2 разом з мітками, ідентифікованими моделлю RAM, для створення вбудованих функцій DINOv2. З іншого боку, при роботі з моделлю CLIP крок попередньої обробки включає перетворення обрізаного зображення в тензорний формат, сумісний з CLIP, після чого обчислюються вбудовані функції. Ці вбудовування є критичними, оскільки вони інкапсулюють візуальні та семантичні атрибути об'єктів, які є вирішальними для всебічного розуміння об'єктів на сцені. Ці вбудовування проходять нормалізацію на основі їх L2-норми, яка регулює вектор ознак до стандартизованої одиничної довжини. Цей крок нормалізації забезпечує послідовні та справедливі порівняння між різними зображеннями.
\ На етапі реалізації цього етапу ми ітеруємо кожне зображення в наших даних і виконуємо наступні процедури:
\ (1) Зображення обрізається до області інтересу, використовуючи координати обмежувальної рамки, надані моделлю Grounding DINO, ізолюючи об'єкт для детального аналізу.
\ (2) Генеруємо вбудовування DINOv2 та CLIP для обрізаного зображення.
\ (3) Нарешті, вбудовування зберігаються разом з масками з попереднього розділу.
\ З завершенням цих кроків ми тепер маємо детальні представлення ознак для кожного об'єкта, збагачуючи наш набір даних для подальшого аналізу та застосування.
\
:::info Автори:
(1) Лакш Нанвані, Міжнародний інститут інформаційних технологій, Хайдарабад, Індія; цей автор зробив рівний внесок у цю роботу;
(2) Кумарадітья Гупта, Міжнародний інститут інформаційних технологій, Хайдарабад, Індія;
(3) Адітья Матур, Міжнародний інститут інформаційних технологій, Хайдарабад, Індія; цей автор зробив рівний внесок у цю роботу;
(4) Свайям Аграваль, Міжнародний інститут інформаційних технологій, Хайдарабад, Індія;
(5) А.Х. Абдул Хафез, Університет Хасана Кальйонджу, Шахінбей, Газіантеп, Туреччина;
(6) К. Мадхава Крішна, Міжнародний інститут інформаційних технологій, Хайдарабад, Індія.
:::
:::info Ця стаття доступна на arxiv за ліцензією CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International).
:::
\
Вам також може сподобатися

Чому деякі все ще переїжджають до "Блакитної зони" Боракай

Ті, хто пропустив XRP, тепер звертають увагу на Apeing ($APEING) як на одну з наступних криптовалют 2025 року, яка досягне $1
