

教导人工智能看见和说话:深入了解 OW‑VISCap 方法
链接表
摘要和1. 引言
-
相关工作
2.1 开放世界视频实例分割
2.2 密集视频对象描述和2.3 对象查询的对比损失
2.4 通用视频理解和2.5 封闭世界视频实例分割
-
方法
3.1 概述
3.2 开放世界对象查询
3.3 描述头
3.4 查询间对比损失和3.5 训练
-
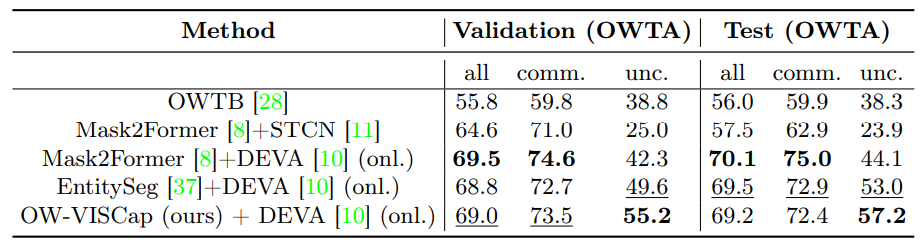
实验和4.1 数据集与评估指标
4.2 主要结果
4.3 消融研究和4.4 定性结果
-
结论、致谢和参考文献
\ 补充材料
A. 额外分析
B. 实现细节
C. 局限性
3 方法
给定一个视频,我们的目标是联合检测、分割和描述视频中存在的对象实例。重要的是,请注意对象实例类别可能不是训练集的一部分(例如,图3(顶行)中显示的降落伞),这使我们的目标处于开放世界设置中。为了实现这一目标,给定的视频首先被分解成短片段,每个片段由T帧组成。每个片段使用我们的方法OW-VISCap进行处理。我们在第4节中讨论每个片段结果的合并。
\ 我们在3.1节中提供OW-VISCap处理每个片段的概述。然后我们讨论我们的贡献:(a)在3.2节中引入开放世界对象查询,(b)在3.3节中使用掩码注意力进行以对象为中心的描述,以及(c)在3.4节中使用查询间对比损失以确保对象查询彼此不同。在3.5节中,我们讨论最终的训练目标。
3.1 概述
\ 开放世界和封闭世界对象查询都由我们专门设计的描述头处理,该描述头生成以对象为中心的描述,分类头生成类别标签,以及检测头生成分割掩码或边界框。
\ 
\ 我们引入查询间对比损失以确保对象查询被鼓励彼此不同。我们在3.4节中提供详细信息。对于封闭世界对象,这种损失有助于消除高度重叠的假阳性。对于开放世界对象,它有助于发现新对象。
\ 最后,我们在3.5节中提供完整的训练目标。
\
3.2 开放世界对象查询
\ 
\ 
\ 我们首先使用匈牙利算法[34]通过最小化匹配成本将真实对象与开放世界预测匹配。然后使用最优匹配来计算最终的开放世界损失。
\ 
\
3.3 描述头
\ 
\
3.4 查询间对比损失
\ 
\
3.5 训练
我们的总训练损失是
\ 
\ ![表2:VidSTG [57]数据集上的密集视频对象描述结果。Off.表示离线方法,onl.指在线方法。](https://cdn.hackernoon.com/images/null-0v3336a.png)
\
:::info 作者:
(1) Anwesa Choudhuri,伊利诺伊大学厄巴纳-香槟分校 ([email protected]);
(2) Girish Chowdhary,伊利诺伊大学厄巴纳-香槟分校 ([email protected]);
(3) Alexander G. Schwing,伊利诺伊大学厄巴纳-香槟分校 ([email protected])。
:::
:::info 本论文可在arxiv上获取,采用CC by 4.0 Deed(署名4.0国际)许可证。
:::
\


您可能也会喜欢

Revolut延迟IPO至2028年,成功获得英国银行牌照

MAGA总检察长在参议院竞选升温之际宣誓承认违反道德规范:《华尔街日报》




