在没有系统表的情况下优化 Databricks 集群成本和利用率

在大多数企业 Databricks 环境中(例如在MSC 或大型分析生态系统中),系统表如 system.jobrunlogs 或 system.cluster_events 可能由于安全或治理策略而被限制或禁用。
然而,跟踪集群利用率和成本对以下方面至关重要:
- 了解作业如何有效使用计算资源
- 识别闲置集群或成本泄漏
- 预测基础设施预算
- 构建自定义成本仪表板
本博客演示了一种逐步方法,仅使用 Databricks REST API 来计算集群利用率和成本 — 无需系统表。
项目用例
在我们的 MSC 数据平台中,我们在开发、测试和生产环境中运行多个 Databricks 集群。\n 我们面临三个主要挑战:
- 无法访问系统表(受管理员策略限制)
- 由 ADF 或编排管道动态创建的作业的临时集群
- 无法直接查看集群利用率如何转化为成本
因此,我们构建了一个轻量级利用率分析器:
- 从 Databricks REST API 提取数据
- 计算作业运行时间与集群运行时间的对比
- 使用 DBU 和 VM 费率估算成本
- 输出易于使用的 DataFrame
问题与方法
识别的挑战
团队通常需要了解:
- 哪些集群处于闲置状态(运行但作业活动少)?
- 利用率百分比是多少(作业运行时间与集群运行时间的对比)?
- 每个集群的成本是多少(DBU + VM)?
当 Unity Catalog 系统表(例如 system.jobrunlogs)不可用时,默认的基于 SQL 的方法会失败。REST API 成为可靠的备选方案。
笔记本中使用的高级方法
- 通过 /api/2.0/clusters/list 列出集群。
- 使用集群 JSON 内的时间戳(创建/启动/终止字段)估算集群运行时间。(这是当 /clusters/events 不可用时的实用备选方案。)
- 使用带有时间过滤器(或限制)的 /api/2.1/jobs/runs/list 获取最近的作业运行。
- 使用 clusterinstance.clusterid(或其他集群元数据)将作业运行与集群匹配。
- 计算利用率:利用率 % = 总作业运行时间 / 总集群运行时间。
- 使用简单公式估算成本:成本 = 运行小时数 × (DBU/小时 × 假设的 DBU) + 运行小时数 × 节点数 × VM $/小时。
此笔记本特意使用有界查询(最后 N 次运行、时间窗口),因此运行速度快。
\ 1. 设置和配置
# Databricks 集群利用率和成本分析器(无系统表) # 作者: GPT-5 | 适用于任何具有 REST API 访问权限的工作区 # 要求: Databricks 个人访问令牌、工作区 URL # 您可以在 Databricks 笔记本内部或外部运行此程序。 import requests from datetime import datetime, timezone, timedelta import pandas as pd # ================= 配置 ================= DATABRICKS_HOST = "https://adb-2085295290875554.14.azuredatabricks.net/" # 替换为您的工作区 URL # DATABRICKS_TOKEN = "" # 替换为您的 PAT HEADERS = {"Authorization": f"Bearer {token}"} params={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} # 时间窗口(例如,最近 7 天) DAYS_BACK = 7 SINCE_TS_MS = int((datetime.now(timezone.utc) - timedelta(days=DAYS_BACK)).timestamp() * 1000) UNTIL_TS_MS = int(datetime.now(timezone.utc).timestamp() * 1000) # 成本参数(根据您的定价调整) DBU_RATE_PER_HOUR = 0.40 # 每 DBU/小时的 $ VM_COST_PER_NODE_PER_HOUR = 0.60 # 每个云 VM 节点/小时的 $ DEFAULT_DBU_PER_CLUSTER_PER_HOUR = 8 # 中小型作业集群的典型值 # ==========================================
\ 此部分初始化:
- 用于身份验证的工作区 URL 和令牌
- 您想要分析利用率的时间范围
- 成本假设:
- DBU 费率(每 DBU 的 $/小时)
- VM 节点成本
- 大致的 DBU 消耗
在企业设置中,这些费率可以通过您的 FinOps 或计费 API 动态获取。
-
API 包装函数
\
# Api GET 请求 def api_get(path, params=None): url = f"{DATABRICKS_HOST.rstrip('/')}{path}" try: r = requests.get(url, headers=HEADERS, params=params, timeout=60) if r.status_code == 404: print(f"跳过 :{path} (404 未找到)") return {} r.raise_for_status() return r.json() except Exception as e: print(f"错误: {e}") return {}
\ 此辅助函数标准化所有 REST API GET 调用。\n 它:
-
构建完整的端点 URL
-
优雅地处理 404(当集群或运行已过期时很重要)
-
返回解析后的 JSON
为什么重要: 此函数确保干净的 API 通信,即使任何集群数据丢失也不会中断您的笔记本流程。
\
-
列出所有活动集群
\
# ---------- 步骤 1: 获取所有集群相关详细信息 ---------- def list_clusters(): clusters = [] res = api_get("/api/2.0/clusters/list") return res.get("clusters", [])
\ 这将检索工作区中所有可用的集群。\n 这相当于以编程方式查看您的"计算"选项卡。\n 响应包含:
-
集群 ID
-
名称
-
节点数
-
创建者信息
-
创建和终止时间
用例: 有助于识别在选定窗口中消耗资源的集群。
4. 估算集群运行时间
\
# ---------- 步骤 2: 获取集群事件运行时间 ---------- def get_cluster_runtime(cluster): events = [] offset = 0 limit = 200 # while True: # params = {"cluster_id": cluster_id} created = cluster.get("creator_user_name") created_time = cluster.get("start_time") or cluster.get("created_time") terminated_time = cluster.get("terminated_time") if not created_time: return 0 end_ts = terminated_time or UNTIL_TS_MS start_ms = max(created_time, SINCE_TS_MS) runtime_ms = max(0, end_ts - start_ms) return runtime_ms /1000/3600
\ 我们计算每个集群的总运行小时数:
-
使用创建和终止时间戳
-
处理当前正在运行的集群(终止时间缺失)
-
标准化为小时
为什么重要: 此值是利用率的分母 — 表示窗口期间的总集群运行时间。
5. 获取最近的作业运行
\
# ------------------获取最近的作业运行 ---------------------------- def get_recent_job_runs(): params ={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} res = api_get("/api/2.1/jobs/runs/list", params) return res.get("runs", [])
\ 此函数不是获取整个作业历史记录(速度很慢),\n 而是检索最近 10 次作业运行以进行快速诊断。
在生产环境中,您可以按以下条件过滤:
- 特定的 job_id
- completed_only=true
- 日期窗口(starttimefrom, starttimeto)
\
-
计算利用率和成本
\
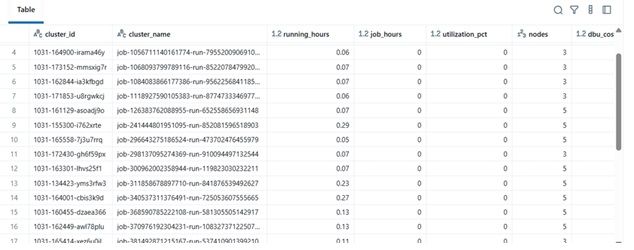
# -------------------------------------计算成本并解析集群利用率详细信息 --------------------- def compute_utilization_and_cost(clusters, job_runs): records =[] now_ms = int(datetime.now(timezone.utc).timestamp() * 1000) for c in clusters: cid = c.get("cluster_id") cname = c.get("cluster_name") print(f"处理集群 {cname}") running_hours = get_cluster_runtime(c) if running_hours == 0: continue job_runtime_ms = 0 for r in job_runs: ci = r.get("cluster_instance",{}) if ci.get("cluster_id") == cid: s = r.get("start_time") or SINCE_TS_MS e = r.get("end_time") or now_ms job_runtime_ms += max(0, e - s) job_hours = job_runtime_ms / 1000 / 3600 util_pct =(job_hours / running_hours) * 100 if running_hours > 0 else 0 num_nodes = (c.get("num_workers") or c.get("autoscale",{}).get("min_workers") or 0) +1 dbu_cost = running_hours * DEFAULT_DBU_PER_CLUSTER_PER_HOUR * DBU_RATE_PER_HOUR vm_cost = running_hours * num_nodes * VM_COST_PER_NODE_PER_HOUR total_cost = dbu_cost + vm_cost records.append({ "cluster_id": cid, "cluster_name": cname,"running_hours":round(running_hours,2), "job_hours": round(job_hours,2) ,"utilization_pct": round(util_pct,2), "nodes": num_nodes,"dbu_cost": round(dbu_cost,2), "vm_cost": round(vm_cost,2), "total_cost": round(total_cost,2) }) return pd.DataFrame(records)
这是逻辑的核心:
-
循环遍历每个集群
-
计算每个集群的总作业运行时间(使用作业运行 API)
-
派生利用率百分比 = (作业小时数 / 集群运行小时数) × 100
-
估算成本:
- 基于费率 × DBU/小时的 DBU 成本
- VM 成本 = 节点数 × 节点成本/小时 × 运行小时数
为什么重要: \n 这提供了效率和支出的统一视图 — 有助于识别成本高但利用率低的集群。
7. 编排管道
\
# ---------- 主程序 ---------- print(f"收集最近 {DAYS_BACK} 天的数据...") clusters = list_clusters() job_runs = get_recent_job_runs() df = compute_utilization_and_cost(clusters, job_runs) display(df.sort_values("utilization_pct", ascending=False))
\ 这个最终块:
-
检索数据
-
执行成本计算
-
显示排序后的 Data Frame
在实践中,此 Data Frame 可以:
-
导出到 Excel 或 Delta 表
-
发送到 Power BI 仪表板
-
集成到 FinOps 自动化管道中
\
结果示例
| clustername | runninghours | jobhours | utilizationpct | nodes | total_cost | |----|----|----|----|----|----| | etl-job-prod | 36.5 | 28.0 | 76.7% | 4 | $142.8 | | dev-debug | 12.0 | 1.2 | 10.0% | 2 | $18.4 | | nightly-adf | 48.0 | 45.0 | 93.7% | 6 | $260.4 |
\ 
\ \
-
实际效益
通过实施此分析器:
-
工程团队即使没有审计访问权限也可以跟踪集群成本。
-
管理人员可以了解未充分利用的集群。
-
DevOps 可以自动终止低使用率集群。
-
财务部门可以使用内部指标验证 Databricks 发票。
在我们的 MSC 项目中,我们将其用作数据平台可观察性堆栈的一部分 — 将 REST API 数据、ADF 作业日志和成本趋势组合到统一的仪表板中。
\


您可能也会喜欢

XRP发出看涨链上信号,尽管价格走势疲软

Vitalik Buterin 标记 OpenClaw 中的数据外泄风险