

混合适应如何使语言模型微调更经济更智能

链接表
摘要和1. 引言
-
背景
2.1 专家混合
2.2 适配器
-
适配混合
3.1 路由策略
3.2 一致性正则化
3.3 适配模块合并和3.4 适配模块共享
3.5 与贝叶斯神经网络和模型集成的联系
-
实验
4.1 实验设置
4.2 主要结果
4.3 消融研究
-
相关工作
-
结论
-
局限性
-
致谢和参考文献
附录
A. 少样本NLU数据集 B. 消融研究 C. NLU任务的详细结果 D. 超参数
3 适配混合

\
3.1 路由策略
最近的工作如THOR(Zuo等,2021)已经证明随机路由策略与经典路由机制如Switch路由(Fedus等,2021)一样有效,并具有以下优势。由于输入示例被随机路由到不同的专家,因此不需要额外的负载平衡,因为每个专家都有平等的被激活机会,从而简化了框架。此外,在Switch层进行专家选择时没有额外的参数,因此也没有额外的计算。后者在我们的参数高效微调设置中尤为重要,以保持参数和FLOPs与单个适配模块相同。为了分析AdaMix的工作原理,我们在3.5节中展示了随机路由和模型权重平均与贝叶斯神经网络和模型集成的联系。
\ \ 
\ \ 这种随机路由使适配模块能够在训练期间学习不同的转换并获得任务的多种视角。然而,由于训练期间的随机路由协议,这也在推理过程中创造了一个关于使用哪些模块的挑战。我们通过以下两种技术解决这一挑战,这些技术进一步允许我们合并适配模块并获得与单个模块相同的计算成本(FLOPs,可调适配参数数量)。
3.2 一致性正则化
\ 
\ \ \ 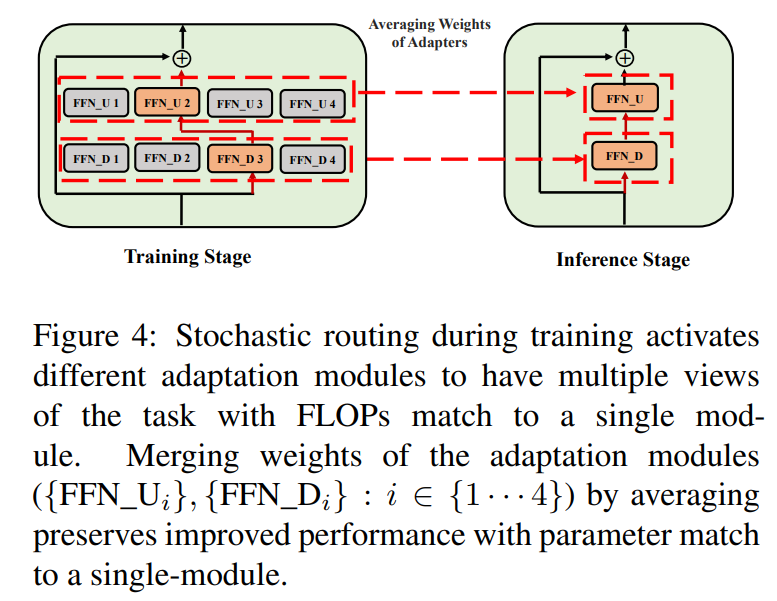
3.3 适配模块合并
虽然上述正则化减轻了推理过程中随机模块选择的不一致性,但它仍然导致托管多个适配模块的服务成本增加。先前在为下游任务微调语言模型的工作中已经表明,平均使用不同随机种子微调的不同模型的权重可以提高性能,优于单个微调模型。最近的研究(Wortsman等,2022)还表明,从相同初始化不同微调的模型位于相同的错误盆地中,这激发了使用权重聚合进行稳健任务总结的动机。我们采用并扩展了先前用于语言模型微调的技术,应用于我们的多视角适配模块的参数高效训练
\ \ 
\
3.4 适配模块共享
\ 
3.5 与贝叶斯神经网络和模型集成的联系
\ 
\ \ 这需要对所有可能的模型权重进行平均,这在实践中是难以处理的。因此,已经开发了几种基于变分推断方法和使用dropout的随机正则化技术的近似方法。在本工作中,我们利用另一种形式的随机正则化,即随机路由。这里的目标是在可处理的分布族中找到一个替代分布qθ(w),以替代难以计算的真实模型后验分布。理想的替代分布是通过最小化候选分布与真实后验分布之间的Kullback-Leibler(KL)散度来确定的。
\ \ 
\ \ \ 
\ \ \ 
\ \ \ \
:::info 作者:
(1) 王亚青,普渡大学 ([email protected]);
(2) Sahaj Agarwal,微软 ([email protected]);
(3) Subhabrata Mukherjee,微软研究院 ([email protected]);
(4) 刘晓东,微软研究院 ([email protected]);
(5) 高静,普渡大学 ([email protected]);
(6) Ahmed Hassan Awadallah,微软研究院 ([email protected]);
(7) 高剑峰,微软研究院 ([email protected])。
:::
:::info 本论文可在arxiv上获取,遵循CC BY 4.0 DEED许可。
:::
\


