

混合適應方法如何使語言模型微調更經濟且更智能
連結目錄
摘要和 1. 引言
-
背景
2.1 專家混合
2.2 適配器
-
適配混合
3.1 路由策略
3.2 一致性正則化
3.3 適配模組合併和 3.4 適配模組共享
3.5 與貝葉斯神經網路和模型集成的連接
-
實驗
4.1 實驗設置
4.2 主要結果
4.3 消融研究
-
相關工作
-
結論
-
限制
-
致謝和參考文獻
附錄
A. 少樣本 NLU 數據集 B. 消融研究 C. NLU 任務的詳細結果 D. 超參數
3 適配混合

\
3.1 路由策略
最近的工作如 THOR (Zuo et al., 2021) 已經證明隨機路由等隨機路由策略與 Switch 路由 (Fedus et al., 2021) 等經典路由機制一樣有效,並具有以下優勢。由於輸入示例被隨機路由到不同的專家,因此不需要額外的負載平衡,因為每個專家都有平等的被激活機會,從而簡化了框架。此外,在 Switch 層中沒有額外的參數,因此在專家選擇時不需要額外的計算。後者在我們的參數高效微調設置中特別重要,以保持參數和 FLOPs 與單個適配模組相同。為了分析 AdaMix 的工作原理,我們在 3.5 節中展示了隨機路由和模型權重平均與貝葉斯神經網路和模型集成的連接。
\ \ 
\ \ 這種隨機路由使適配模組能夠在訓練期間學習不同的轉換並獲得任務的多個視角。然而,由於訓練期間的隨機路由協議,這也在推理期間使用哪些模組方面帶來了挑戰。我們通過以下兩種技術解決這一挑戰,這些技術進一步允許我們合併適配模組並獲得與單個模組相同的計算成本(FLOPs,可調適配參數數量)。
3.2 一致性正則化
\ 
\ \ \ 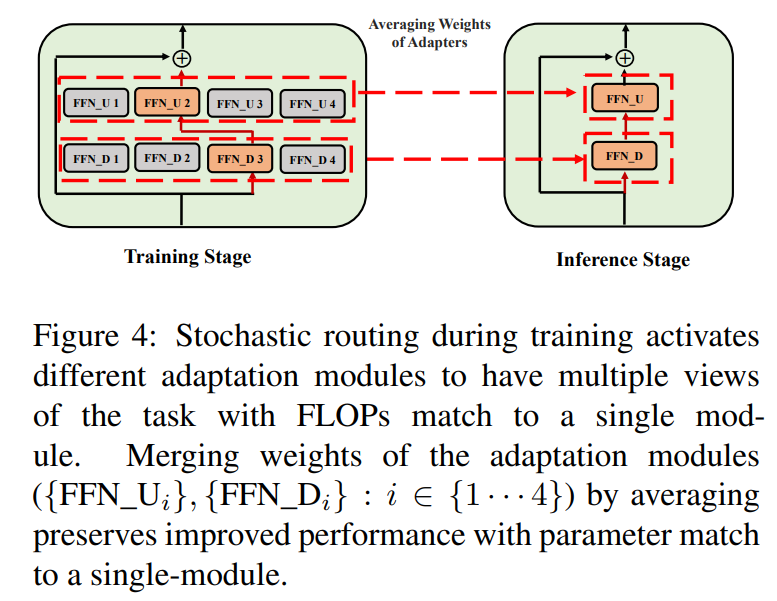
3.3 適配模組合併
雖然上述正則化減輕了推理期間隨機模組選擇的不一致性,但它仍然導致增加了託管多個適配模組的服務成本。先前在為下游任務微調語言模型的工作中已經表明,平均使用不同隨機種子微調的不同模型的權重可以優於單個微調模型。最近的工作 (Wortsman et al., 2022) 也表明,從相同初始化不同微調的模型位於相同的錯誤盆地中,這激發了使用權重聚合進行穩健任務摘要的動機。我們採用並擴展了先前用於語言模型微調的技術,應用於我們的多視角適配模組的參數高效訓練
\ \ 
\
3.4 適配模組共享
\ 
3.5 與貝葉斯神經網路和模型集成的連接
\ 
\ \ 這需要對所有可能的模型權重進行平均,這在實踐中是難以處理的。因此,已經開發了幾種基於變分推斷方法和使用 Dropout 的隨機正則化技術的近似方法。在這項工作中,我們利用另一種形式的隨機正則化,即隨機路由。在這裡,目標是在可處理的分佈族中找到一個替代分佈 qθ(w),可以替代難以計算的真實模型後驗分佈。理想的替代分佈是通過最小化候選分佈與真實後驗分佈之間的 Kullback-Leibler (KL) 散度來確定的。
\ \ 
\ \ \ 
\ \ \ 
\ \ \ \
:::info 作者:
(1) Yaqing Wang,普渡大學 ([email protected]);
(2) Sahaj Agarwal,微軟 ([email protected]);
(3) Subhabrata Mukherjee,微軟研究院 ([email protected]);
(4) Xiaodong Liu,微軟研究院 ([email protected]);
(5) Jing Gao,普渡大學 ([email protected]);
(6) Ahmed Hassan Awadallah,微軟研究院 ([email protected]);
(7) Jianfeng Gao,微軟研究院 ([email protected])。
:::
:::info 本論文可在 Arxiv 上獲取,採用 CC BY 4.0 DEED 許可證。
:::
\
您可能也會喜歡

WSJ:摩根大通推出首個代幣化貨幣市場基金「MONY」,讓資產透過區塊鏈更快結算

Meta 元宇宙策略傳出轉向 資源全面押注 AI 智慧眼鏡
