

解決 3D 分割的最大瓶頸
:::info 作者:
(1) George Tang,麻省理工學院;
(2) Krishna Murthy Jatavallabhula,麻省理工學院;
(3) Antonio Torralba,麻省理工學院。
:::
連結目錄
摘要和 I. 引言
II. 背景
III. 方法
IV. 實驗
V. 結論和參考文獻
\ 
\ 摘要— 我們解決了從一系列已知姿態的 RGB 圖像中學習 3D 實例分割的隱式場景表示問題。為此,我們引入了 3DIML,這是一個新穎的框架,能夠高效學習可從新視角渲染以產生視角一致的實例分割掩碼的標籤場。3DIML 顯著改進了現有基於隱式場景表示方法的訓練和推理運行時間。與先前以自監督方式優化神經場的方法不同,後者需要複雜的訓練程序和損失函數設計,3DIML 利用兩階段處理。第一階段 InstanceMap 將由前端實例分割模型生成的圖像序列的 2D 分割掩碼作為輸入,並將相應的掩碼關聯到 3D 標籤。這些幾乎視角一致的偽標籤掩碼隨後在第二階段 InstanceLift 中用於監督神經標籤場的訓練,該標籤場插值 InstanceMap 遺漏的區域並解決歧義。此外,我們引入了 InstanceLoc,它通過融合兩者的輸出,使得在給定訓練好的標籤場和現成的圖像分割模型的情況下,能夠近乎實時地定位實例掩碼。我們在 Replica 和 ScanNet 數據集的序列上評估 3DIML,並在圖像序列的溫和假設下展示 3DIML 的有效性。我們在保持相當質量的同時,相比現有隱式場景表示方法實現了巨大的實際加速,展示了其促進更快速、更有效的 3D 場景理解的潛力。
I. 引言
智能代理需要在物體層面上理解場景,以有效執行特定情境下的行動,如導航和操作。雖然從圖像中分割物體已通過在互聯網規模數據集上訓練的可擴展模型取得了顯著進展[1],[2],但將這些能力擴展到 3D 環境仍然具有挑戰性。
\ 在本研究中,我們解決了從已知姿態的 2D 圖像中學習 3D 場景表示的問題,該表示將底層場景分解為其組成物體的集合。解決此問題的現有方法專注於訓練與類別無關的 3D 分割模型[3],[4],需要大量標註的 3D 數據,並直接在顯式 3D 場景表示(如點雲)上操作。另一類方法[5],[6]則提出直接將現成實例分割模型的分割掩碼提升到隱式 3D 表示中,如神經輻射場(NeRF)[7],使其能夠從新視角渲染 3D 一致的實例掩碼。
\ 然而,基於神經場的方法一直難以優化,[5]和[6]需要數小時來優化低至中等解析度的圖像(如 300 × 640)。特別是,全景提升[5]隨場景中物體數量的增加呈立方增長,阻止其應用於包含數百個物體的場景,而對比提升[6]則需要複雜的多階段訓練程序,阻礙了其在機器人應用中的實用性。
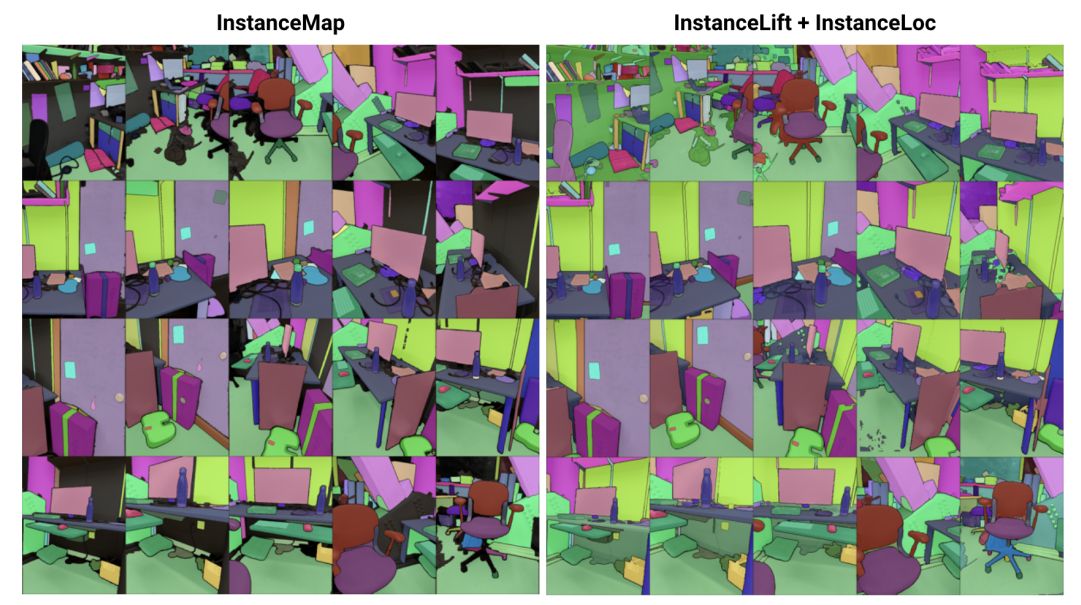
\ 為此,我們提出了3DIML,一種從已知姿態的 RGB 圖像中學習 3D 一致實例分割的高效技術。3DIML 包括兩個階段:InstanceMap 和 InstanceLift。給定使用前端實例分割模型[2]從 RGB 序列中提取的視角不一致的 2D 實例掩碼,InstanceMap 生成一系列視角一致的實例掩碼。為此,我們首先使用相似圖像對之間的關鍵點匹配來關聯不同幀之間的掩碼。然後,我們使用這些可能含噪的關聯來監督神經標籤場 InstanceLift,它利用 3D 結構來插值缺失的標籤並解決歧義。與需要多階段訓練和額外損失函數設計的先前工作不同,我們僅使用單一渲染損失進行實例標籤監督,使訓練過程能夠顯著更快地收斂。3DIML的總運行時間(包括 InstanceMap)僅需 10-20 分鐘,而先前的方法則需要 3-6 小時。
\ 此外,我們設計了 InstaLoc,這是一個快速定位管道,它接收新視角並定位該圖像中分割的所有實例(使用快速實例分割模型[8]),通過稀疏查詢標籤場並融合標籤預測與提取的圖像區域。最後,3DIML極為模塊化,我們可以輕鬆替換我們方法的組件,以便在更高性能的組件可用時使用它們。
\ 總結我們的貢獻:
\ • 一種高效的神經場學習方法,將 3D 場景分解為其組成物體
\ • 一種快速實例定位算法,融合對訓練好的標籤場的稀疏查詢與高性能圖像實例分割模型,生成 3D 一致的實例分割掩碼
\ • 在單個 GPU(NVIDIA RTX 3090)上基準測試的整體實際運行時間比先前技術提高了 14-24 倍
II. 背景
2D 分割:視覺轉換器架構的普及和圖像數據集規模的增加導致了一系列最先進的圖像分割模型。全景提升和對比提升都通過學習神經場將 Mask2Former [1]生成的全景分割掩碼提升到 3D。在開放集分割方面,Segment Anything(SAM)[2]通過在 1100 萬張圖像上訓練 10 億個掩碼,實現了前所未有的性能。HQ-SAM [9]改進了 SAM 的細粒度掩碼。FastSAM [8]將 SAM 提煉為 CNN 架構,實現了類似的性能,同時速度提高了數個數量級。在本研究中,我們使用 GroundedSAM [10],[11],它改進了 SAM 以生成物體級而非部件級的分割掩碼。
\ 用於 3D 實例分割的神經場:NeRF 是隱式場景表示,可以準確編碼複雜的幾何、語義和其他模態,並解決視角不一致的監督[12]。全景提升[5]在 NeRF 的高效變體 TensoRF [13]上構建語義和實例分支,利用匈牙利匹配損失函數將學習的實例掩碼分配給參考視角不一致掩碼的代理物體 ID。隨著物體數量的增加,這種方法擴展性差(由於匈牙利匹配的立方複雜度)。對比提升[6]通過在場景特徵上採用對比學習來解決這個問題,正負關係由它們是否投影到同一掩碼上決定。此外,對比提升需要基於慢-快聚類的損失以實現穩定訓練,雖然比全景提升性能更快,但需要多階段訓練,導致收斂緩慢。與我們同時進行的 Instance-NeRF [14]直接學習標籤場,但他們的掩碼關聯基於使用 NeRF-RPN [15]在 NeRF 中檢測物體。相比之下,我們的方法允許擴展到非常高的圖像解析度,同時僅需少量(40-60)神經場查詢來渲染分割掩碼。
\ 運動結構恢復:在 InstanceMap 的掩碼關聯過程中,我們從可擴展的 3D 重建管道如 hLoc [16]獲得靈感,包括首先使用視覺描述符匹配圖像視角,然後應用關鍵點匹配作為掩碼關聯的初步步驟。我們使用 LoFTR [17]進行關鍵點提取和匹配。
\
:::info 本論文可在 arxiv 上獲取,根據 CC by 4.0 Deed(Attribution 4.0 International)許可證發布。
:::
\
您可能也會喜歡

策略如何在比特幣持有量疑慮中保持 Nasdaq 100 現貨強勢

Ripple 獲得美國銀行業准入,推動 XRP 長期目標邁向 $27
