

การแมตติ้งแบบใช้มาสก์นำทางที่แข็งแกร่ง: การจัดการกับข้อมูลนำเข้าที่มีสัญญาณรบกวนและความหลากหลายของวัตถุ
สารบัญลิงก์
บทคัดย่อและ 1. บทนำ
-
งานวิจัยที่เกี่ยวข้อง
-
MaGGIe
3.1. Efficient Masked Guided Instance Matting
3.2. Feature-Matte Temporal Consistency
-
ชุดข้อมูล Instance Matting
4.1. Image Instance Matting และ 4.2. Video Instance Matting
-
การทดลอง
5.1. การฝึกล่วงหน้าบนข้อมูลภาพ
5.2. การฝึกบนข้อมูลวิดีโอ
-
การอภิปรายและเอกสารอ้างอิง
\ เอกสารเพิ่มเติม
-
รายละเอียดสถาปัตยกรรม
-
Image matting
8.1. การสร้างและเตรียมชุดข้อมูล
8.2. รายละเอียดการฝึก
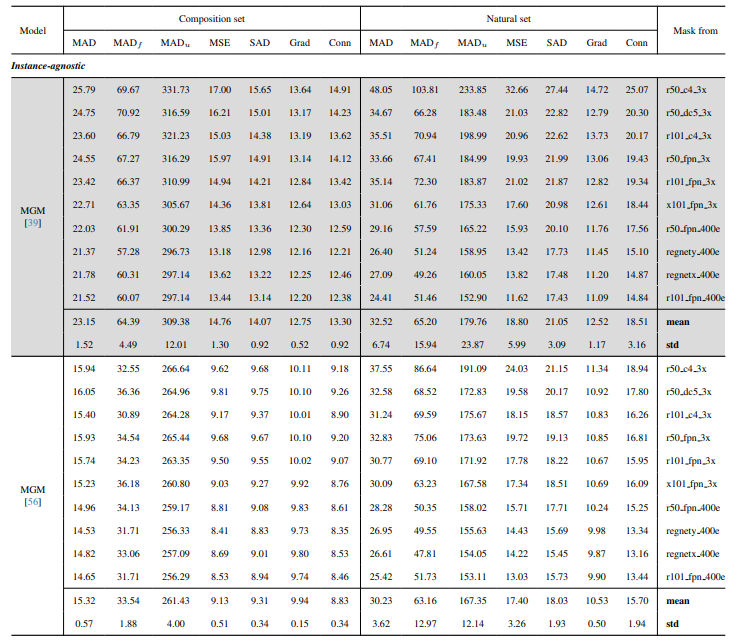
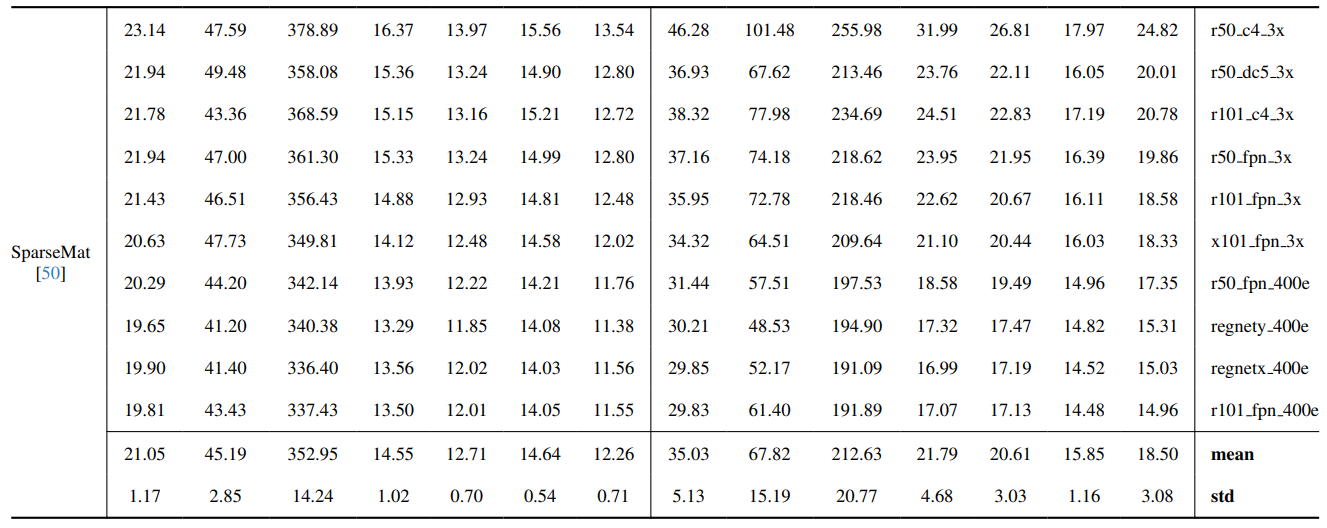
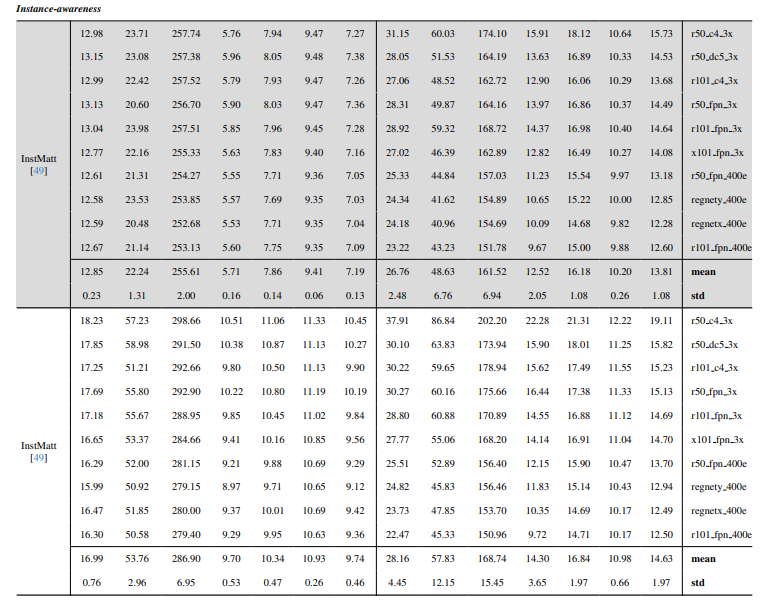
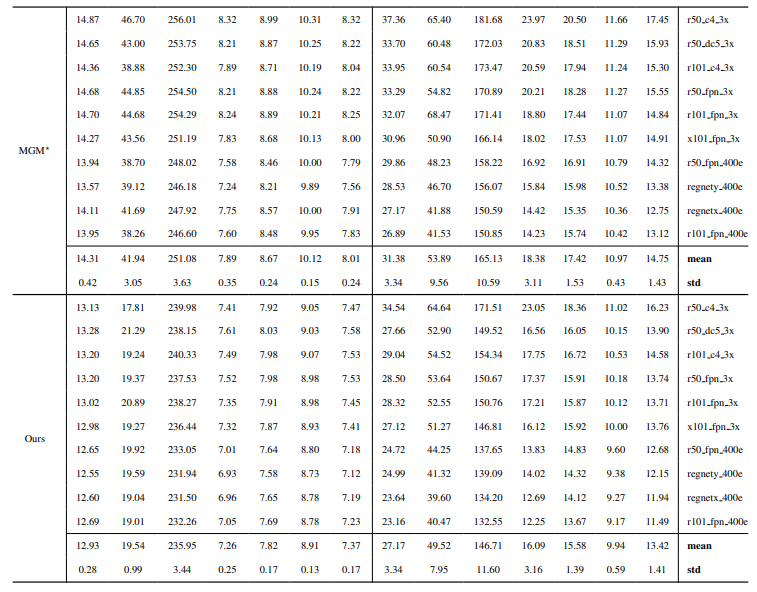
8.3. รายละเอียดเชิงปริมาณ
8.4. ผลลัพธ์เชิงคุณภาพเพิ่มเติมบนภาพธรรมชาติ
-
Video matting
9.1. การสร้างชุดข้อมูล
9.2. รายละเอียดการฝึก
9.3. รายละเอียดเชิงปริมาณ
9.4. ผลลัพธ์เชิงคุณภาพเพิ่มเติม
8.4. ผลลัพธ์เชิงคุณภาพเพิ่มเติมบนภาพธรรมชาติ
รูปที่ 13 แสดงประสิทธิภาพของโมเดลของเราในสถานการณ์ที่ท้าทาย โดยเฉพาะในการแสดงผลบริเวณเส้นผมอย่างแม่นยำ เฟรมเวิร์กของเรามีประสิทธิภาพเหนือกว่า MGM⋆ อย่างสม่ำเสมอในการรักษารายละเอียด โดยเฉพาะในการโต้ตอบของ instance ที่ซับซ้อน เมื่อเปรียบเทียบกับ InstMatt โมเดลของเราแสดงความเหนือกว่าในการแยก instance และความแม่นยำของรายละเอียดในบริเวณที่คลุมเครือ
\ รูปที่ 14 และรูปที่ 15 แสดงประสิทธิภาพของโมเดลของเราและงานก่อนหน้าในกรณีสุดขีดที่เกี่ยวข้องกับหลาย instance ในขณะที่ MGM⋆ ประสบปัญหากับสัญญาณรบกวนและความแม่นยำในสถานการณ์ instance หนาแน่น โมเดลของเราคงความแม่นยำสูง InstMatt ที่ไม่มีข้อมูลการฝึกเพิ่มเติม แสดงข้อจำกัดในสถานการณ์ที่ซับซ้อนเหล่านี้
\ ความทนทานของแนวทางแบบ mask-guided ของเราได้รับการแสดงเพิ่มเติมในรูปที่ 16 ที่นี่เราเน้นถึงความท้าทายที่ตัวแปร MGM และ SparseMat เผชิญในการทำนายส่วนที่ขาดหายไปในอินพุต mask ซึ่งโมเดลของเราจัดการได้ อย่างไรก็ตาม สิ่งสำคัญคือต้องทราบว่าโมเดลของเราไม่ได้ออกแบบมาเป็นเครือข่ายการแบ่งส่วน instance ของมนุษย์ ดังที่แสดงในรูปที่ 17 เฟรมเวิร์กของเราปฏิบัติตามคำแนะนำอินพุต เพื่อให้แน่ใจว่าการทำนาย alpha matte แม่นยำแม้จะมีหลาย instance ใน mask เดียวกัน
\ ท้ายที่สุด รูปที่ 12 และรูปที่ 11 เน้นความสามารถในการทำงานทั่วไปของโมเดลของเรา โมเดลสกัดทั้งวัตถุมนุษย์และวัตถุอื่นๆ จากพื้นหลังได้อย่างแม่นยำ แสดงความหลากหลายในสถานการณ์และประเภทวัตถุต่างๆ
\ ตัวอย่างทั้งหมดเป็นภาพจากอินเทอร์เน็ตที่ไม่มีข้อมูลจริง และใช้ mask จาก r101fpn400e เป็นคำแนะนำ
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\
:::info ผู้แต่ง:
(1) Chuong Huynh, University of Maryland, College Park ([email protected]);
(2) Seoung Wug Oh, Adobe Research (seoh,[email protected]);
(3) Abhinav Shrivastava, University of Maryland, College Park ([email protected]);
(4) Joon-Young Lee, Adobe Research ([email protected]).
:::
:::info บทความนี้ มีให้บน arxiv ภายใต้ใบอนุญาต CC by 4.0 Deed (Attribution 4.0 International)
:::
\


คุณอาจชอบเช่นกัน
เงิน 280 ล้านดอลลาร์ถูกระบายออกผ่านการโจมตีทางสังคม
ข่าวราคาบิตคอยน์: ไมเคิล เซย์เลอร์ เผย บิตคอยน์สามารถเข้าถึงผู้คน 5 พันล้านคน ขณะที่ราคากำลังทดสอบการทะลุระดับสำคัญ


