

Bagaimana Model AI Hibrid Menyeimbangkan Memori dan Efisiensi
Tabel Tautan
Abstrak dan 1. Pendahuluan
-
Metodologi
-
Eksperimen dan Hasil
3.1 Pemodelan Bahasa pada Data vQuality
3.2 Eksplorasi pada Perhatian dan Rekurensi Linier
3.3 Ekstrapolasi Panjang yang Efisien
3.4 Pemahaman Konteks Panjang
-
Analisis
-
Kesimpulan, Ucapan Terima Kasih, dan Referensi
A. Detail Implementasi
B. Hasil Eksperimen Tambahan
C. Detail Pengukuran Entropi
D. Keterbatasan
\
A Detail Implementasi
\ Untuk lapisan GLA dalam arsitektur Sliding GLA, kami menggunakan jumlah kepala dm/384, rasio ekspansi kunci 0,5, dan rasio ekspansi nilai 1. Untuk lapisan RetNet kami menggunakan jumlah kepala yang setengah dari jumlah kepala kueri perhatian, rasio ekspansi kunci 1 dan rasio ekspansi nilai 2. Implementasi GLA dan RetNet berasal dari repositori Flash Linear Attention[3] [YZ24]. Kami menggunakan implementasi berbasis FlashAttention untuk ekstrapolasi Self-Extend[4]. Model Mamba 432M memiliki lebar model 1024 dan model Mamba 1.3B memiliki lebar model 2048. Semua model yang dilatih pada SlimPajama memiliki konfigurasi pelatihan yang sama dan ukuran menengah MLP seperti Samba, kecuali ditentukan lain. Infrastruktur pelatihan pada SlimPajama didasarkan pada versi modifikasi dari kode dasar TinyLlama[5].
\ 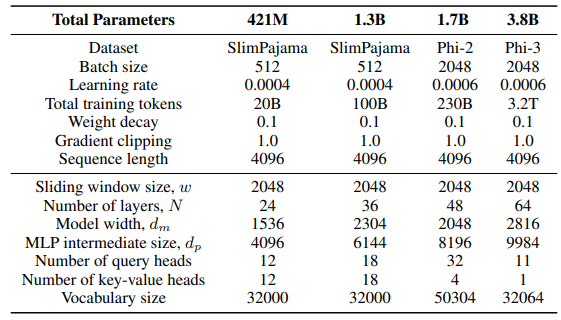
\ Dalam konfigurasi generasi untuk tugas hilir, kami menggunakan decoding greedy untuk GSM8K, dan Nucleus Sampling [HBD+19] dengan suhu τ = 0,2 dan top-p = 0,95 untuk HumanEval. Untuk MBPP dan SQuAD, kami menetapkan τ = 0,01 dan top-p = 0,95.
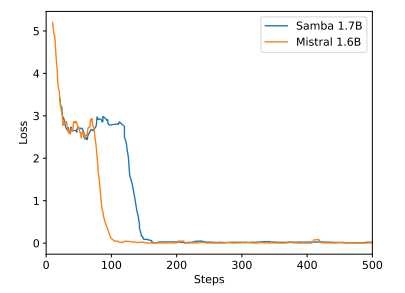
B Hasil Eksperimen Tambahan
\ 
\ 
\ 
\
C Detail Pengukuran Entropi
\ 
\
D Keterbatasan
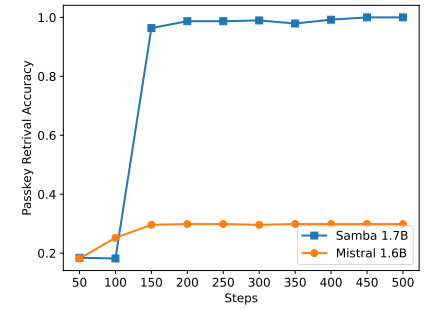
Meskipun Samba menunjukkan kinerja pengambilan memori yang menjanjikan melalui penyetelan instruksi, model dasar pra-terlatihnya memiliki kinerja pengambilan yang mirip dengan model berbasis SWA, seperti yang ditunjukkan pada Gambar 7. Ini membuka arah masa depan untuk lebih meningkatkan kemampuan pengambilan Samba tanpa mengorbankan efisiensi dan kemampuan ekstrapolasinya. Selain itu, strategi hibridisasi Samba tidak selalu lebih baik daripada alternatif lain dalam semua tugas. Seperti yang ditunjukkan pada Tabel 2, MambaSWA-MLP menunjukkan peningkatan kinerja pada tugas-tugas seperti WinoGrande, SIQA, dan GSM8K. Ini memberi kita potensi untuk berinvestasi dalam pendekatan yang lebih canggih untuk melakukan kombinasi dinamis bergantung pada input dari model berbasis SWA dan berbasis SSM.
\
:::info Penulis:
(1) Liliang Ren, Microsoft dan University of Illinois di Urbana-Champaign ([email protected]);
(2) Yang Liu†, Microsoft ([email protected]);
(3) Yadong Lu†, Microsoft ([email protected]);
(4) Yelong Shen, Microsoft ([email protected]);
(5) Chen Liang, Microsoft ([email protected]);
(6) Weizhu Chen, Microsoft ([email protected]).
:::
:::info Makalah ini tersedia di arxiv di bawah lisensi CC BY 4.0.
:::
[3] https://github.com/sustcsonglin/flash-linear-attention
\ [4] https://github.com/datamllab/LongLM/blob/master/selfextendpatch/Llama.py
\ [5] https://github.com/jzhang38/TinyLlama


Anda Mungkin Juga Menyukai

Kalshi Menang: Pengadilan Sirkuit Ketiga Memberikan Kemenangan Pasar Prediksi

MACD Naik, $2.1K Bertahan




