

Studi Ablasi Mengkonfirmasi Kebutuhan Tingkat Dinamis untuk Performa RECKONING
Tabel Tautan
Abstrak dan 1. Pendahuluan
-
Latar Belakang
-
Metode
-
Eksperimen
4.1 Kinerja Penalaran Multi-hop
4.2 Penalaran dengan Pengalih Perhatian
4.3 Generalisasi ke Pengetahuan Dunia Nyata
4.4 Analisis Waktu Eksekusi
4.5 Menghafal Pengetahuan
-
Karya Terkait
-
Kesimpulan, Ucapan Terima Kasih, dan Referensi
\ A. Dataset
B. Penalaran Dalam Konteks dengan Pengalih Perhatian
C. Detail Implementasi
D. Tingkat Pembelajaran Adaptif
E. Eksperimen dengan Model Bahasa Besar
D Tingkat Pembelajaran Adaptif
Karya sebelumnya [3, 4] menunjukkan bahwa tingkat pembelajaran tetap yang dibagikan di seluruh langkah dan parameter tidak menguntungkan kinerja generalisasi sistem. Sebaliknya, [3] merekomendasikan mempelajari tingkat pembelajaran untuk
\ 
\ 
\ setiap lapisan jaringan dan setiap langkah adaptasi dalam loop dalam. Parameter lapisan dapat belajar menyesuaikan tingkat pembelajaran secara dinamis pada setiap langkah. Untuk mengontrol tingkat pembelajaran α dalam loop dalam secara adaptif, kami mendefinisikan α sebagai sekumpulan variabel yang dapat disesuaikan: α = {α0, α1, …αL}, di mana L adalah jumlah lapisan dan untuk setiap l = 0, …, L, αl adalah vektor dengan N elemen yang diberikan jumlah langkah loop dalam N yang telah ditentukan sebelumnya. Persamaan pembaruan loop dalam kemudian menjadi
\ 
\ 
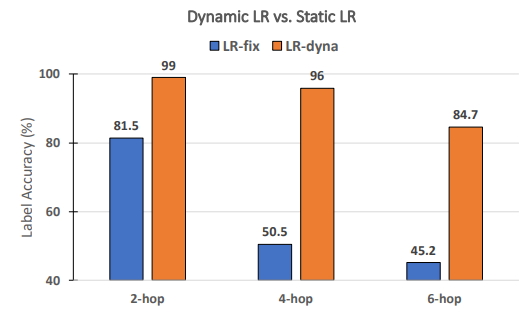
\ Apakah tingkat pembelajaran dinamis diperlukan untuk kinerja RECKONING? Mengikuti karya sebelumnya tentang meta-learning [3, 4], kami secara dinamis mempelajari serangkaian tingkat pembelajaran per-langkah-per-lapisan untuk RECKONING. Dalam studi ablasi ini, kami menganalisis apakah tingkat pembelajaran dinamis untuk loop dalam secara efektif meningkatkan kinerja penalaran loop luar. Demikian pula, kami menetapkan pengaturan eksperimental lainnya dan menetapkan jumlah langkah loop dalam menjadi 4. Seperti yang ditunjukkan Gambar 8, ketika menggunakan tingkat pembelajaran statis (yaitu, semua lapisan dan langkah loop dalam berbagi tingkat pembelajaran konstan), kinerja menurun dengan margin yang besar (penurunan rata-rata 34,2%). Penurunan kinerja menjadi lebih signifikan pada pertanyaan yang memerlukan lebih banyak hop penalaran (penurunan 45,5% untuk 4-hop dan 39,5% untuk 6-hop), menunjukkan pentingnya penggunaan tingkat pembelajaran dinamis dalam loop dalam kerangka kerja kami.
\ 
\
:::info Penulis:
(1) Zeming Chen, EPFL ([email protected]);
(2) Gail Weiss, EPFL ([email protected]);
(3) Eric Mitchell, Stanford University ([email protected])';
(4) Asli Celikyilmaz, Meta AI Research ([email protected]);
(5) Antoine Bosselut, EPFL ([email protected]).
:::
:::info Makalah ini tersedia di arxiv di bawah lisensi CC BY 4.0 DEED.
:::
\


Anda Mungkin Juga Menyukai

Bukan celah hukum: Kontrol ekspor AI Singapura memungkinkan Tiongkok mengakses AI AS secara legal

Nigeria menginvestasikan $9 juta dalam penelitian untuk mendorong ambisi ekonomi digital

Futures Perpetual Bitcoin: Rasio Long/Short di Bursa Teratas



