

Mengajarkan AI untuk Melihat dan Berbicara: Di Balik Pendekatan OW‑VISCap
Tabel Tautan
Abstrak dan 1. Pendahuluan
-
Karya Terkait
2.1 Segmentasi Instans Video Dunia-Terbuka
2.2 Captioning Objek Video Padat dan 2.3 Loss Kontrastif untuk Kueri Objek
2.4 Pemahaman Video Umum dan 2.5 Segmentasi Instans Video Dunia-Tertutup
-
Pendekatan
3.1 Ikhtisar
3.2 Kueri Objek Dunia-Terbuka
3.3 Kepala Captioning
3.4 Loss Kontrastif Antar-Kueri dan 3.5 Pelatihan
-
Eksperimen dan 4.1 Dataset dan Metrik Evaluasi
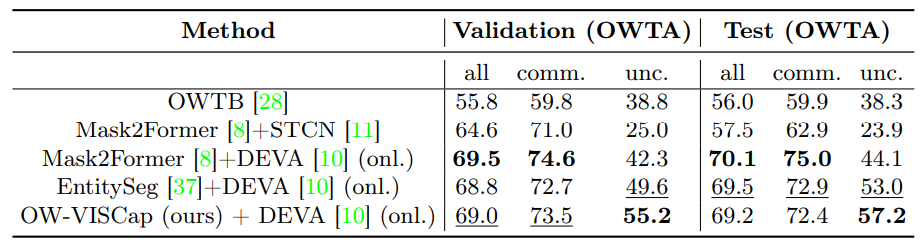
4.2 Hasil Utama
4.3 Studi Ablasi dan 4.4 Hasil Kualitatif
-
Kesimpulan, Ucapan Terima Kasih, dan Referensi
\ Materi Tambahan
A. Analisis Tambahan
B. Detail Implementasi
C. Keterbatasan
3 Pendekatan
Diberikan sebuah video, tujuan kami adalah untuk secara bersamaan mendeteksi, mensegmentasi, dan memberi caption instans objek yang ada dalam video. Penting untuk dicatat bahwa kategori instans objek mungkin tidak menjadi bagian dari set pelatihan (misalnya, parasut yang ditunjukkan pada Gambar 3 (baris atas)), menempatkan tujuan kami dalam pengaturan dunia-terbuka. Untuk mencapai tujuan ini, video yang diberikan pertama-tama dipecah menjadi klip pendek, masing-masing terdiri dari T frame. Setiap klip diproses menggunakan pendekatan kami OW-VISCap. Kami membahas penggabungan hasil dari setiap klip di Bagian 4.
\ Kami memberikan ikhtisar OW-VISCap untuk memproses setiap klip di Bagian 3.1. Kemudian kami membahas kontribusi kami: (a) pengenalan kueri objek dunia-terbuka di Bagian 3.2, (b) penggunaan perhatian bertopeng untuk captioning berpusat objek di Bagian 3.3, dan (c) penggunaan loss kontrastif antar-kueri untuk memastikan bahwa kueri objek berbeda satu sama lain di Bagian 3.4. Di Bagian 3.5, kami membahas tujuan pelatihan akhir.
3.1 Ikhtisar
\ Baik kueri objek dunia-terbuka maupun dunia-tertutup diproses oleh kepala captioning yang dirancang khusus yang menghasilkan caption berpusat objek, kepala klasifikasi yang menghasilkan label kategori, dan kepala deteksi yang menghasilkan baik mask segmentasi atau kotak pembatas.
\ 
\ Kami memperkenalkan loss kontrastif antar-kueri untuk memastikan bahwa kueri objek didorong untuk berbeda satu sama lain. Kami memberikan detail di Bagian 3.4. Untuk objek dunia tertutup, loss ini membantu dalam menghilangkan false positive yang sangat tumpang tindih. Untuk objek dunia-terbuka, ini membantu dalam penemuan objek baru.
\ Akhirnya, kami memberikan tujuan pelatihan lengkap di Bagian 3.5.
\
3.2 Kueri Objek Dunia-Terbuka
\ 
\ 
\ Pertama-tama kami mencocokkan objek ground truth dengan prediksi dunia-terbuka dengan meminimalkan biaya pencocokan menggunakan algoritma Hungarian [34]. Pencocokan optimal kemudian digunakan untuk menghitung loss dunia-terbuka akhir.
\ 
\
3.3 Kepala Captioning
\ 
\
3.4 Loss Kontrastif Antar-Kueri
\ 
\
3.5 Pelatihan
Total loss pelatihan kami adalah
\ 
\ ![Tabel 2: Hasil captioning objek video padat pada dataset VidSTG [57]. Off. menunjukkan metode offline dan onl. mengacu pada metode online.](https://cdn.hackernoon.com/images/null-0v3336a.png)
\
:::info Penulis:
(1) Anwesa Choudhuri, University of Illinois at Urbana-Champaign ([email protected]);
(2) Girish Chowdhary, University of Illinois at Urbana-Champaign ([email protected]);
(3) Alexander G. Schwing, University of Illinois at Urbana-Champaign ([email protected]).
:::
:::info Makalah ini tersedia di arxiv di bawah lisensi CC by 4.0 Deed (Attribution 4.0 International).
:::
\


Anda Mungkin Juga Menyukai
Ancaman Kuantum Mengancam Bitcoin dan Kripto—Begini Cara XRP Ledger Bersiap

'Sungguh mengecewakan': Ekonom tercengang menyaksikan Trump menghancurkan ekonomi yang sedang meroket




