

Pengaturan IIL Baru: Meningkatkan Model yang Diterapkan Hanya dengan Data Baru
Tabel Tautan
Abstrak dan 1 Pendahuluan
-
Karya terkait
-
Pengaturan masalah
-
Metodologi
4.1. Distilasi berbasis batas keputusan
4.2. Konsolidasi pengetahuan
-
Hasil eksperimen dan 5.1. Pengaturan Eksperimen
5.2. Perbandingan dengan metode SOTA
5.3. Studi ablasi
-
Kesimpulan dan pekerjaan masa depan dan Referensi
\
Materi Tambahan
- Detail analisis teoretis pada mekanisme KCEMA dalam IIL
- Ikhtisar algoritma
- Detail dataset
- Detail implementasi
- Visualisasi gambar input berdebu
- Hasil eksperimen lebih lanjut
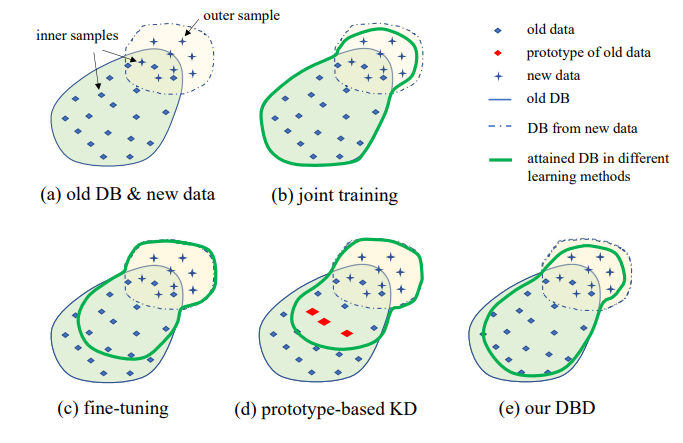
3. Pengaturan masalah
Ilustrasi pengaturan IIL yang diusulkan ditunjukkan pada Gambar 1. Seperti yang dapat dilihat, data dihasilkan secara terus-menerus dan tidak terduga dalam aliran data. Umumnya dalam aplikasi nyata, orang cenderung mengumpulkan data yang cukup terlebih dahulu dan melatih model kuat M0 untuk penerapan. Tidak peduli seberapa kuat modelnya, model tersebut pasti akan menghadapi data di luar distribusi dan gagal menanganinya. Kasus-kasus yang gagal ini dan pengamatan baru dengan skor rendah lainnya akan dianotasi untuk melatih model dari waktu ke waktu. Melatih ulang model dengan semua data kumulatif setiap kali menyebabkan biaya waktu dan sumber daya yang semakin tinggi. Oleh karena itu, IIL baru bertujuan untuk meningkatkan model yang ada hanya dengan data baru setiap kali.
\ 
\ 
\
:::info Penulis:
(1) Qiang Nie, Universitas Sains dan Teknologi Hong Kong (Guangzhou);
(2) Weifu Fu, Tencent Youtu Lab;
(3) Yuhuan Lin, Tencent Youtu Lab;
(4) Jialin Li, Tencent Youtu Lab;
(5) Yifeng Zhou, Tencent Youtu Lab;
(6) Yong Liu, Tencent Youtu Lab;
(7) Qiang Nie, Universitas Sains dan Teknologi Hong Kong (Guangzhou);
(8) Chengjie Wang, Tencent Youtu Lab.
:::
:::info Makalah ini tersedia di arxiv di bawah lisensi CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
\


Anda Mungkin Juga Menyukai

Zoho, Guardian mendorong transformasi digital mendesak untuk bisnis yang dipimpin perempuan di Nigeria

Ajudan utama Trump melakukan kesalahan 'memalukan' terkait Alkitab




