

5 Cara Mengejutkan AI Saat Ini Gagal untuk Benar-benar "Berpikir"

Model bahasa besar (LLMs) telah meningkat kemampuannya secara drastis, menunjukkan kinerja luar biasa dalam tugas-tugas mulai dari pemahaman bahasa alami hingga pembuatan kode. Kita berinteraksi dengan mereka setiap hari, dan kelancaran mereka bisa mengejutkan, menempatkan kita tepat di lembah aneh kecerdasan buatan. Tetapi apakah kinerja canggih ini setara dengan pemikiran asli, atau hanya ilusi teknologi tinggi?
\ Semakin banyak penelitian menunjukkan bahwa di balik tirai kompetensi terdapat serangkaian keterbatasan mendalam dan kontraintuitif. Artikel ini mengeksplorasi lima kegagalan paling signifikan yang mengungkap jurang antara kinerja AI dan pemahaman sejati seperti manusia.
Mereka Tidak Bernalar Lebih Keras; Mereka Hanya Kolaps
Sebuah makalah terbaru dari Apple Research, berjudul "Ilusi Berpikir," mengungkapkan cacat kritis bahkan pada "Model Penalaran Besar" (LRMs) yang paling canggih yang menggunakan teknik seperti Chain-of-Thought. Penelitian menunjukkan bahwa model-model ini tidak benar-benar bernalar tetapi merupakan simulator canggih yang menabrak tembok keras ketika masalah menjadi cukup kompleks.
\ Para peneliti menggunakan teka-teki Menara Hanoi untuk menguji model, mengidentifikasi tiga rezim kinerja berbeda berdasarkan kompleksitas teka-teki:
\
- Kompleksitas Rendah (3 cakram): Model standar non-penalaran berkinerja sama baik, atau bahkan lebih baik, daripada model LRM "berpikir".
- Kompleksitas Menengah (6 cakram): LRM yang menghasilkan rantai pemikiran lebih panjang menunjukkan keunggulan yang jelas.
- Kompleksitas Tinggi (7+ cakram): Kedua jenis model mengalami "kolaps total," dengan akurasi mereka anjlok ke nol.
\
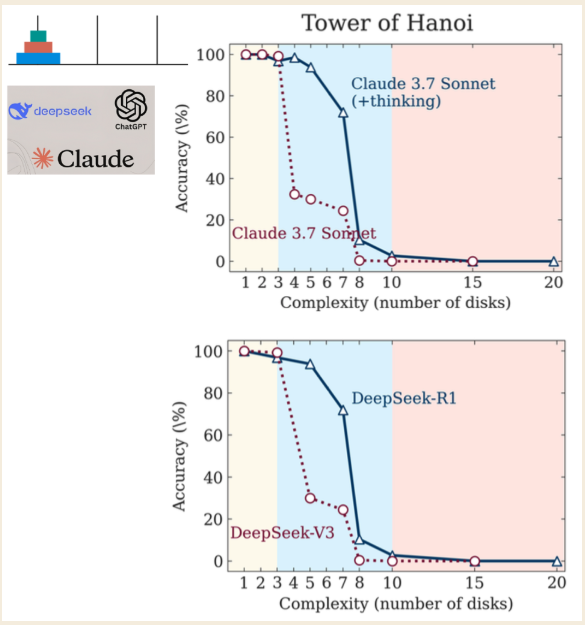
Temuan yang paling kontraintuitif adalah bahwa model "berpikir" lebih sedikit saat masalah menjadi lebih sulit. Yang lebih menyedihkan lagi, mereka gagal menghitung dengan benar bahkan ketika secara eksplisit diberi algoritma yang diperlukan untuk memecahkan teka-teki. Ini menunjukkan ketidakmampuan mendasar untuk menerapkan aturan di bawah tekanan, peniruan pemikiran yang kosong yang hancur ketika paling dibutuhkan. (Para peneliti mencatat bahwa meskipun Anthropic, laboratorium AI pesaing, telah mengajukan keberatan, mereka tetap merupakan keluhan kecil daripada bantahan mendasar terhadap temuan.)
\ Seperti yang dikatakan oleh para peneliti dari University of Arizona, perilaku ini menangkap esensi ilusi:
...menunjukkan bahwa LLM bukanlah penalar berprinsip tetapi lebih merupakan simulator canggih dari teks yang menyerupai penalaran.
Rantai Pemikiran" Mereka Sering Kali Fatamorgana
Chain-of-Thought (CoT) adalah proses di mana LLM menuliskan "penalaran" langkah demi langkah sebelum memberikan jawaban akhir, fitur yang dirancang untuk meningkatkan akurasi dan mengungkapkan logika internalnya. Namun, studi terbaru yang menganalisis bagaimana LLM menangani aritmatika dasar menunjukkan proses ini sering kali merupakan "fatamorgana rapuh."
\ Mengejutkan, ada inkonsistensi besar antara langkah-langkah penalaran dalam CoT dan jawaban akhir yang diberikan model. Dalam tugas yang melibatkan penambahan sederhana, sebuah penemuan mengejutkan dibuat: di lebih dari 60% sampel, model menghasilkan langkah-langkah penalaran yang salah yang entah bagaimana, secara misterius, mengarah ke jawaban akhir yang benar.
\ Ini setara dengan seorang siswa yang menunjukkan pekerjaan yang tidak masuk akal pada tes matematika tetapi secara ajaib menulis angka akhir yang benar. Anda tidak akan menyimpulkan mereka memahami materi; Anda akan mencurigai mereka menyalin jawaban. Dalam AI, ini menunjukkan bahwa "penalaran" sering kali merupakan pembenaran post-hoc, bukan proses pemikiran asli. Ini bukan bug yang diperbaiki dengan peningkatan skala; masalahnya menjadi lebih buruk dengan model yang lebih canggih, dengan tingkat perilaku kontradiktif ini meningkat menjadi 74% pada GPT-4.
\ Jika "proses pemikiran" internal model adalah fatamorgana, apa yang terjadi ketika dipaksa untuk memecahkan masalah nyata dan kompleks? Seringkali, ia terjun ke dalam kegilaan.
Mereka Terjebak dalam Loop "Turun ke Kegilaan"
Ketika menggunakan LLM untuk tugas kompleks seperti debugging kode, pola berbahaya dapat muncul: "turun ke kegilaan" atau "loop halusinasi." Ini adalah siklus umpan balik di mana LLM, yang mencoba memperbaiki kesalahan pemrograman, terjebak dalam loop irasional yang tidak berakhir. Ia menyarankan perbaikan yang tampak masuk akal tetapi gagal, dan ketika diminta solusi lain, sering kali memperkenalkan kembali kesalahan asli, menjebak pengguna dalam siklus yang sia-sia.
\ Sebuah studi yang menugaskan programmer untuk men-debug kode mengungkapkan tren mengejutkan untuk alur kerja berbantuan AI. Hasilnya jelas: programmer tanpa bantuan AI menyelesaikan lebih banyak tugas dengan benar dan lebih sedikit tugas dengan salah dibandingkan kelompok yang menggunakan LLM untuk bantuan.
\ Renungkan ini: dalam tugas debugging yang kompleks, memiliki asisten AI canggih tidak hanya tidak membantu—itu secara aktif merugikan, menyebabkan hasil yang lebih buruk daripada tidak memiliki AI sama sekali. Peserta yang menggunakan AI sering terjebak dalam loop sia-sia ini, membuang-buang waktu untuk perbaikan yang secara konseptual tidak berdasar. Peneliti juga mengidentifikasi masalah "solusi berisik", di mana perbaikan yang benar terkubur dalam banyaknya saran yang tidak relevan, resep sempurna untuk frustrasi manusia. "Bantuan" yang cacat ini menyoroti bagaimana lapisan mengesankan AI dapat menyembunyikan inti yang sangat tidak dapat diandalkan, terutama ketika taruhannya tinggi.
Benchmark Mengesankan Mereka Dibangun di Atas Fondasi Cacat
Ketika perusahaan AI merilis model baru, mereka menunjuk pada skor benchmark yang mengesankan untuk membuktikan keunggulan mereka. Namun, pandangan lebih dekat dapat mengungkapkan gambaran yang jauh kurang menyanjung.
\ SWE-bench (Software Engineering Benchmark), yang digunakan untuk mengukur kemampuan LLM dalam memperbaiki masalah perangkat lunak dunia nyata dari GitHub, adalah studi kasus utama. Studi independen dari York University menemukan cacat kritis yang sangat melebih-lebihkan kemampuan yang dirasakan model:
\
- Kebocoran Solusi ("Curang"): Dalam 32,67% patch yang berhasil, solusi yang benar sudah disediakan dalam laporan masalah itu sendiri.
- Tes Lemah: Dalam 31,08% kasus di mana model "lulus," tes verifikasi terlalu lemah untuk benar-benar mengkonfirmasi bahwa perbaikan itu benar.
\ Ketika contoh cacat ini disaring, kinerja dunia nyata dari model teratas (SWE-Agent + GPT-4) anjlok. Tingkat resolusinya turun dari yang diiklankan 12,47% menjadi hanya 3,97%. Selain itu, lebih dari 94% masalah dalam benchmark dibuat sebelum tanggal cutoff pengetahuan LLM, menimbulkan pertanyaan serius tentang kebocoran data.
\ Ini mengungkapkan realitas yang mengkhawatirkan: benchmark sering kali merupakan alat pemasaran yang menyajikan skenario terbaik, hasil laboratorium, yang hancur di bawah pengawasan dunia nyata. Kesenjangan antara kekuatan yang diiklankan dan kinerja yang diverifikasi bukan retakan; itu adalah jurang.
Mereka Menguasai Aturan Tetapi Secara Fundamental Kurang Pemahaman
Bahkan jika semua kegagalan teknis di atas diperbaiki, hambatan yang lebih dalam, lebih filosofis tetap ada. LLM kekurangan komponen inti kecerdasan manusia. Sementara para filsuf mendiskusikan kesadaran dan intensionalitas, banyak argumen menunjukkan bahwa rasionalitas, alias kemampuan kita untuk memahami konsep universal dan bernalar secara logis, adalah aspek kunci yang unik bagi manusia dan tidak ada dalam AI.
\ Ide ini diperkuat oleh fisikawan Roger Penrose, yang menggunakan teorema ketidaklengkapan Gödel untuk berpendapat bahwa pemahaman matematika manusia melampaui setiap set aturan algoritmik tetap. Pikirkan algoritma apa pun sebagai buku aturan terbatas. Teorema Gödel menunjukkan bahwa seorang matematikawan manusia selalu dapat melihat buku aturan dari luar dan memahami kebenaran yang tidak dapat dibuktikan oleh buku aturan itu sendiri.
\ Pikiran kita tidak hanya mengikuti aturan dalam buku; kita dapat membaca seluruh buku dan memahami keterbatasannya. Kapasitas wawasan ini, pemahaman "non-computable" ini, adalah yang memisahkan kognisi manusia dari AI yang paling canggih sekalipun.
\ LLM adalah ahli dalam memanipulasi simbol berdasarkan algoritma dan pola statistik. Namun, mereka tidak memiliki kesadaran yang diperlukan untuk pemahaman asli. Seperti yang disimpulkan oleh satu argumen kuat:
Trik Pesulap
Meskipun LLM adalah alat yang sangat kuat yang dapat mensimulasikan perilaku cerdas dengan akurasi yang menakjubkan, bukti yang semakin banyak menunjukkan mereka lebih seperti simulator canggih daripada pemikir asli. Kinerja mereka adalah ilusi besar, tontonan kompetensi yang memukau yang hancur di bawah tekanan, bertentangan dengan logikanya sendiri, dan bergantung pada metrik yang cacat. Ini mirip dengan trik pesulap (tampaknya mustahil), tetapi pada akhirnya ilusi yang dibangun dengan teknik cerdas, bukan sihir sungguhan. Saat kita terus mengintegrasikan sistem ini ke dalam dunia kita, kita harus tetap kritis dan mengajukan pertanyaan penting:
\ Jika mesin AI ini rusak pada masalah yang lebih sulit, bahkan ketika Anda memberi mereka algoritma dan aturan, apakah mereka benar-benar berpikir atau hanya berpura-pura dengan sangat baik?
Podcast:
\
- Apple: DI SINI
- Spotify: DI SINI
\


Anda Mungkin Juga Menyukai

RedotPay Menambahkan SUI untuk Pembayaran Kripto Global

Berita dan Prakiraan Harga Pound Sterling: GBP/USD mungkin menemukan penghalang utama di level tertinggi dua bulan




