

Buat Pipeline Data Anda 5X Lebih Cepat dengan Adaptive Batching
Apakah Anda memiliki panggilan LLM yang masif dalam alur transformasi data Anda?
CocoIndex mungkin dapat membantu. Ini didukung oleh mesin Rust yang sangat performa dan sekarang mendukung batching adaptif secara langsung. Hal ini telah meningkatkan Throughput hingga ~5× (≈80% runtime lebih cepat) untuk alur kerja AI native. Dan yang terbaik, Anda tidak perlu mengubah kode apa pun karena batching terjadi secara otomatis, beradaptasi dengan lalu lintas Anda dan menjaga GPU tetap dimanfaatkan sepenuhnya.
Berikut yang kami pelajari saat membangun dukungan batching adaptif ke dalam Cocoindex.
Tapi pertama, mari jawab beberapa pertanyaan yang mungkin ada di pikiran Anda.
Mengapa batching mempercepat pemrosesan?
-
Overhead tetap per panggilan: Ini terdiri dari semua pekerjaan persiapan dan administratif yang diperlukan sebelum komputasi sebenarnya dapat dimulai. Contohnya termasuk pengaturan peluncuran kernel GPU, transisi Python-ke-C/C++, penjadwalan tugas, alokasi dan manajemen memori, serta pembukuan yang dilakukan oleh framework. Tugas-tugas overhead ini sebagian besar independen dari ukuran input tetapi harus dibayar penuh untuk setiap panggilan.
\
-
Pekerjaan bergantung data: Bagian komputasi ini berskala langsung dengan ukuran dan kompleksitas input. Ini mencakup operasi floating-point (FLOPs) yang dilakukan oleh model, pergerakan data di seluruh hierarki memori, pemrosesan token, dan operasi spesifik input lainnya. Tidak seperti overhead tetap, biaya ini meningkat secara proporsional dengan volume data yang diproses.
Ketika item diproses secara individual, overhead tetap terjadi berulang kali untuk setiap item, yang dapat dengan cepat mendominasi total runtime, terutama ketika komputasi per item relatif kecil. Sebaliknya, memproses beberapa item bersama dalam batch secara signifikan mengurangi dampak overhead per item. Batching memungkinkan biaya tetap diamortisasi di banyak item, sambil juga memungkinkan optimasi perangkat keras dan perangkat lunak yang meningkatkan efisiensi pekerjaan bergantung data. Optimasi ini termasuk pemanfaatan pipeline GPU yang lebih efektif, pemanfaatan cache yang lebih baik, dan lebih sedikit peluncuran kernel, yang semuanya berkontribusi pada throughput yang lebih tinggi dan latensi keseluruhan yang lebih rendah.
\
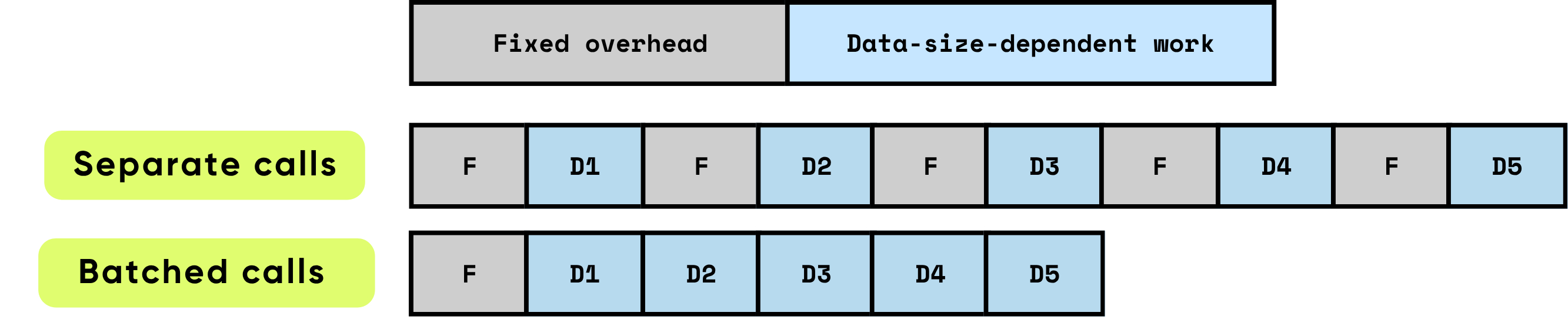
\ Batching secara signifikan meningkatkan kinerja dengan mengoptimalkan efisiensi komputasi dan pemanfaatan sumber daya. Ini memberikan beberapa manfaat yang saling melengkapi:
\
-
Mengamortisasi overhead satu kali: Setiap fungsi atau panggilan API membawa overhead tetap — peluncuran kernel GPU, transisi Python-ke-C/C++, penjadwalan tugas, manajemen memori, dan pembukuan framework. Dengan memproses item dalam batch, overhead ini tersebar di banyak input, secara dramatis mengurangi biaya per item dan menghilangkan pekerjaan pengaturan berulang.
\
-
Memaksimalkan efisiensi GPU: Batch yang lebih besar memungkinkan GPU untuk menjalankan operasi sebagai perkalian matriks padat dan sangat paralel, umumnya diimplementasikan sebagai General Matrix–Matrix Multiplication (GEMM). Pemetaan ini memastikan perangkat keras berjalan pada pemanfaatan yang lebih tinggi, memanfaatkan sepenuhnya unit komputasi paralel, meminimalkan siklus idle, dan mencapai throughput puncak. Operasi kecil tanpa batch membuat banyak GPU kurang dimanfaatkan, membuang kapasitas komputasi yang mahal.
\
-
Mengurangi overhead transfer data: Batching meminimalkan frekuensi transfer memori antara CPU (host) dan GPU (device). Lebih sedikit operasi Host-to-Device (H2D) dan Device-to-Host (D2H) berarti lebih sedikit waktu yang dihabiskan untuk memindahkan data dan lebih banyak waktu yang dikhususkan untuk komputasi sebenarnya. Ini penting untuk sistem throughput tinggi, di mana bandwidth memori sering menjadi faktor pembatas daripada daya komputasi mentah.
Secara kombinasi, efek-efek ini mengarah pada peningkatan throughput yang sangat besar. Batching mengubah banyak komputasi kecil yang tidak efisien menjadi operasi besar yang sangat dioptimalkan yang sepenuhnya memanfaatkan kemampuan perangkat keras modern. Untuk beban kerja AI — termasuk model bahasa besar, visi komputer, dan pemrosesan data real-time — batching bukan hanya optimasi; ini penting untuk mencapai kinerja tingkat produksi yang dapat diskalakan.
\
Seperti apa batching untuk kode Python normal
Kode tanpa batching – sederhana tapi kurang efisien
Cara paling alami untuk mengatur pipeline adalah memproses data bagian demi bagian. Misalnya, loop dua lapis seperti ini:
for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: vector = model.encode([chunk.text]) # one item at a time index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
Ini mudah dibaca dan dipahami: setiap chunk mengalir langsung melalui beberapa langkah.
Batching manual – lebih efisien tapi rumit
Anda dapat mempercepatnya dengan batching, tetapi bahkan versi "batch semuanya sekaligus" yang paling sederhana membuat kode jauh lebih rumit:
\
# 1) Collect payloads and remember where each came from batch_texts = [] metadata = [] # (file_id, chunk_id) for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: batch_texts.append(chunk.text) metadata.append((file.name, chunk.offset)) # 2) One batched call (library will still mini-batch internally) vectors = model.encode(batch_texts) # 3) Zip results back to their sources for (file_name, chunk_offset), vector in zip(metadata, vectors): index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
Selain itu, melakukan batch semuanya sekaligus biasanya tidak ideal karena langkah berikutnya hanya dapat dimulai setelah langkah ini selesai untuk semua data.
Dukungan Batching CocoIndex
CocoIndex menjembatani kesenjangan dan memungkinkan Anda mendapatkan yang terbaik dari kedua dunia – menjaga kesederhanaan kode Anda dengan mengikuti aliran alami, sambil mendapatkan efisiensi dari batching yang disediakan oleh runtime CocoIndex.
Kami telah mengaktifkan dukungan batching untuk fungsi bawaan berikut:
- EmbedText
- SentenceTransformerEmbed
- ColPaliEmbedImage
- ColPaliEmbedQuery
Ini tidak mengubah API. Kode Anda yang sudah ada akan berfungsi tanpa perubahan apa pun – tetap mengikuti aliran alami, sambil menikmati efisiensi batching.
Untuk fungsi kustom, mengaktifkan batching sangat sederhana:
- Atur
batching=Truedalam dekorator fungsi kustom. - Ubah argumen dan tipe pengembalian menjadi
list.
Misalnya, jika Anda ingin membuat fungsi kustom yang memanggil API untuk membuat thumbnail gambar.
@cocoindex.op.function(batching=True) def make_image_thumbnail(self, args: list[bytes]) -> list[bytes]: ...
:::tip Lihat dokumentasi batching untuk detail lebih lanjut.
:::
Bagaimana CocoIndex Melakukan Batching
Pendekatan umum
Batching bekerja dengan mengumpulkan permintaan masuk ke dalam antrian dan memutuskan saat yang tepat untuk mengeluarkannya sebagai satu batch. Waktu itu sangat penting — jika tepat, Anda menyeimbangkan throughput, latensi, dan penggunaan sumber daya sekaligus.
Dua kebijakan batching yang banyak digunakan mendominasi lanskap:
- Batching berbasis waktu (flush setiap W milidetik): Dalam pendekatan ini, sistem mengeluarkan semua permintaan yang tiba dalam jendela tetap W milidetik.
-
Keuntungan: Waktu tunggu maksimum untuk setiap permintaan dapat diprediksi, dan implementasinya sederhana. Ini memastikan bahwa bahkan selama lalu lintas rendah, permintaan tidak akan tetap dalam antrian tanpa batas.
-
Kekurangan: Selama periode lalu lintas jarang, permintaan idle terakumulasi perlahan, menambah latensi untuk kedatangan awal. Selain itu, jendela optimal W sering bervariasi dengan karakteristik beban kerja, memerlukan penyesuaian hati-hati untuk mencapai keseimbangan yang tepat antara latensi dan throughput.
\
- Batching berbasis ukuran (flush ketika K item diantrekan): Di sini, batch dipicu setelah antrian mencapai jumlah item yang telah ditentukan, K.
- Keuntungan: Ukuran batch dapat diprediksi, yang menyederhanakan manajemen memori dan desain sistem. Mudah untuk memahami sumber daya yang akan dikonsumsi oleh setiap batch.
- Kekurangan: Ketika lalu lintas rendah, permintaan mungkin tetap dalam antrian untuk jangka waktu yang lama, meningkatkan latensi untuk item yang tiba pertama. Seperti batching berbasis waktu, K optimal bergantung pada pola beban kerja, memerlukan penyesuaian empiris.
Banyak sistem berkinerja tinggi mengadopsi pendekatan hybrid: mereka mengeluarkan batch ketika jendela waktu W berakhir atau antrian mencapai ukuran K — mana yang lebih dulu. Strategi ini menangkap manfaat dari kedua metode, meningkatkan responsivitas selama lalu lintas jarang sambil mempertahankan ukuran batch yang efisien selama beban puncak.
Meskipun demikian, batching selalu melibatkan parameter yang dapat disesuaikan dan trade-off. Pola lalu lintas, karakteristik beban kerja, dan batasan sistem semuanya mempengaruhi pengaturan ideal. Mencapai kinerja optimal sering memerlukan pemantauan, profiling, dan penyesuaian parameter ini secara dinamis untuk menyelaraskan dengan kondisi real-time.
Pendekatan CocoIndex
Level framework: adaptif, bebas knob
CocoIndex mengimplementasikan mekanisme batching yang sederhana dan alami yang beradaptasi secara otomatis dengan beban permintaan yang masuk. Prosesnya bekerja sebagai berikut:
\
- Antrian berkelanjutan: Sementara batch saat ini sedang diproses pada perangkat (misalnya, GPU), permintaan masuk baru tidak langsung diproses. Sebaliknya, mereka diantrekan. Ini memungkinkan sistem untuk mengakumulasi pekerjaan tanpa mengganggu komputasi yang sedang berlangsung.
- Jendela batch otomatis: Ketika batch saat ini selesai, CocoIndex segera mengambil semua permintaan yang telah terakumulasi dalam antrian dan memperlakukannya sebagai batch berikutnya. Kumpulan permintaan ini membentuk jendela batch baru. Sistem kemudian mulai memproses batch ini segera


Anda Mungkin Juga Menyukai

Bukan celah hukum: Kontrol ekspor AI Singapura memungkinkan Tiongkok mengakses AI AS secara legal

Futures Perpetual Bitcoin: Rasio Long/Short di Bursa Teratas

Ekosistem Token LAB: Panduan Platform Perdagangan Multi-Rantai & Imbalan



