

Detail Teknis: Pelatihan BSGAL, Backbone Swin-L, dan Strategi Ambang Batas Dinamis
Tabel Tautan
Abstrak dan 1 Pendahuluan
-
Karya Terkait
2.1. Augmentasi Data Generatif
2.2. Pembelajaran Aktif dan Analisis Data
-
Pendahuluan
-
Metode Kami
4.1. Estimasi Kontribusi dalam Skenario Ideal
4.2. Pembelajaran Aktif Generatif Streaming Batch
-
Eksperimen dan 5.1. Pengaturan Offline
5.2. Pengaturan Online
-
Kesimpulan, Dampak Lebih Luas, dan Referensi
\
A. Detail Implementasi
B. Ablasi Lebih Lanjut
C. Diskusi
D. Visualisasi
A. Detail Implementasi
A.1. Dataset
Kami memilih LVIS (Gupta et al., 2019) sebagai dataset untuk eksperimen kami. LVIS adalah dataset segmentasi instans skala besar, terdiri dari sekitar 160.000 gambar dengan lebih dari 2 juta anotasi segmentasi instans berkualitas tinggi di 1203 kategori dunia nyata. Dataset ini dibagi lebih lanjut menjadi tiga kategori: langka, umum, dan sering, berdasarkan kemunculannya di seluruh gambar. Instans yang ditandai sebagai 'langka' muncul dalam 1-10 gambar, instans 'umum' muncul dalam 11-100 gambar, sedangkan instans 'sering' muncul dalam lebih dari 100 gambar. Dataset keseluruhan menunjukkan distribusi ekor panjang, sangat menyerupai distribusi data di dunia nyata, dan banyak diterapkan dalam berbagai pengaturan, termasuk segmentasi few-shot (Liu et al., 2023) dan segmentasi dunia terbuka (Wang et al., 2022; Zhu et al., 2023). Oleh karena itu, kami percaya bahwa memilih LVIS memungkinkan refleksi yang lebih baik dari kinerja model dalam skenario dunia nyata. Kami menggunakan pembagian dataset LVIS resmi, dengan sekitar 100.000 gambar dalam set pelatihan dan 20.000 gambar dalam set validasi.
A.2. Generasi Data
Proses generasi dan anotasi data kami konsisten dengan Zhao et al. (2023), dan kami memperkenalkannya secara singkat di sini. Pertama, kami menggunakan StableDiffusion V1.5 (Rombach et al., 2022a) (SD) sebagai model generatif. Untuk 1203 kategori dalam LVIS (Gupta et al., 2019), kami menghasilkan 1000 gambar per kategori, dengan resolusi gambar 512 × 512. Template prompt untuk generasi adalah "a photo of a single {CATEGORY NAME}". Kami menggunakan U2Net (Qin et al., 2020), SelfReformer (Yun and Lin, 2022), UFO (Su et al., 2023), dan CLIPseg (Luddecke and Ecker, 2022) masing-masing untuk menganotasi gambar generatif mentah, dan memilih mask dengan skor CLIP tertinggi sebagai anotasi akhir. Untuk memastikan kualitas data, gambar dengan skor CLIP di bawah 0,21 disaring sebagai gambar berkualitas rendah. Selama pelatihan, kami juga menggunakan strategi penempelan instans yang disediakan oleh Zhao et al. (2023) untuk augmentasi data. Untuk setiap instans, kami mengubah ukurannya secara acak agar sesuai dengan distribusi kategorinya dalam set pelatihan. Jumlah maksimum instans yang ditempel per gambar ditetapkan menjadi 20.
\ Selain itu, untuk lebih memperluas keragaman data yang dihasilkan dan membuat penelitian kami lebih universal, kami juga menggunakan model generatif lain, termasuk DeepFloyd-IF (Shonenkov et al., 2023) (IF) dan Perfusion (Tewel et al., 2023) (PER), dengan 500 gambar per kategori per model. Untuk IF, kami menggunakan model pra-terlatih yang disediakan oleh penulis, dan gambar yang dihasilkan adalah output dari Stage II, dengan resolusi 256×256. Untuk PER, model dasar yang kami gunakan adalah StableDiffusion V1.5. Untuk setiap kategori, kami fine-tune model menggunakan gambar yang dipotong dari set pelatihan, dengan 400 langkah fine-tuning. Kami menggunakan model yang telah di-fine-tune untuk menghasilkan gambar.
\ 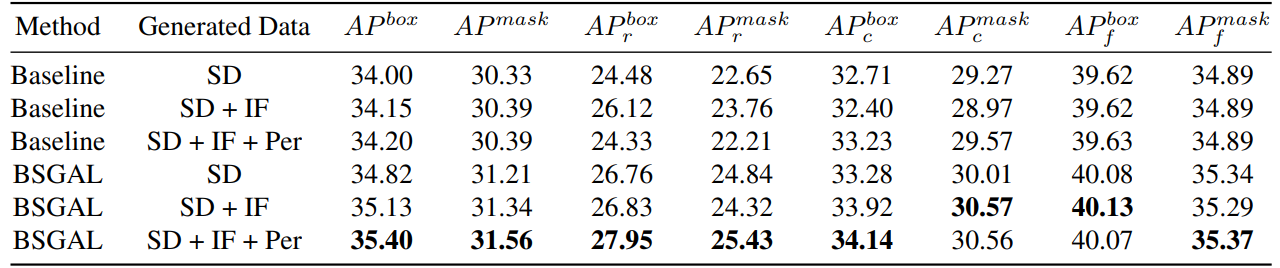
\ Kami juga mengeksplorasi efek penggunaan data yang dihasilkan berbeda pada kinerja model (lihat Tabel 7). Kami dapat melihat bahwa berdasarkan StableDiffusion V1.5 asli, menggunakan model generatif lain dapat membawa beberapa peningkatan kinerja, tetapi peningkatan ini tidak jelas. Secara khusus, untuk kategori frekuensi tertentu, kami menemukan bahwa IF memiliki peningkatan yang lebih signifikan untuk kategori langka, sementara PER memiliki peningkatan yang lebih signifikan untuk kategori umum. Ini mungkin karena data IF lebih beragam, sementara data PER lebih konsisten dengan distribusi set pelatihan. Mengingat bahwa kinerja keseluruhan telah ditingkatkan sampai tingkat tertentu, kami akhirnya mengadopsi data yang dihasilkan dari SD + IF + PER untuk eksperimen selanjutnya.
A.3. Pelatihan Model
Mengikuti Zhao et al. (2023), Kami menggunakan CenterNet2 (Zhou et al., 2021) sebagai model segmentasi kami, dengan ResNet-50 (He et al., 2016) atau Swin-L (Liu et al., 2022) sebagai backbone. Untuk ResNet-50, iterasi pelatihan maksimum ditetapkan menjadi 90.000 dan model diinisialisasi dengan bobot yang pertama kali dilatih pada ImageNet-22k kemudian di-fine-tune pada LVIS (Gupta et al., 2019), seperti yang dilakukan Zhao
\ 
\ et al. (2023). Dan kami menggunakan 4 GPU Nvidia 4090 dengan ukuran batch 16 selama pelatihan. Untuk Swin-L, iterasi pelatihan maksimum ditetapkan menjadi 180.000 dan model diinisialisasi dengan bobot yang dilatih pada ImageNet-22k, karena eksperimen awal kami menunjukkan bahwa inisialisasi ini dapat membawa sedikit peningkatan dibandingkan dengan bobot yang dilatih dengan LVIS. Dan kami menggunakan 4 GPU Nvidia A100 dengan ukuran batch 16 untuk pelatihan. Selain itu, karena jumlah parameter Swin-L yang besar, memori tambahan yang ditempati untuk menyimpan gradien besar, jadi kami sebenarnya menggunakan algoritma dalam Algoritma 2.
\ Parameter lain yang tidak ditentukan juga mengikuti pengaturan yang sama seperti X-Paste (Zhao et al., 2023), seperti optimizer AdamW (Loshchilov and Hutter, 2017) dengan learning rate awal 1e−4.
A.4. Jumlah Data
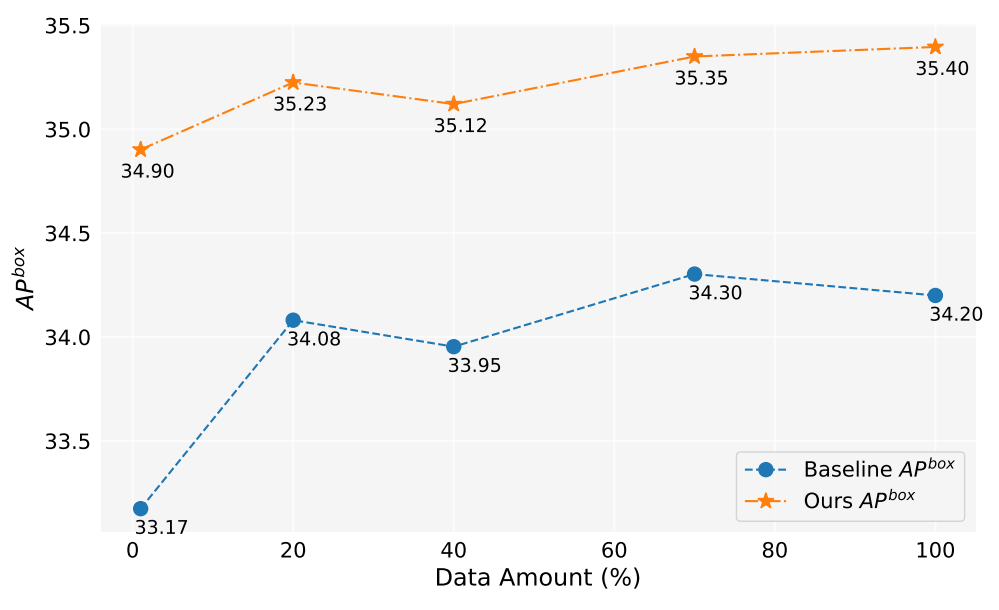
Dalam pekerjaan ini, kami telah menghasilkan lebih dari 2 juta gambar. Gambar 5 menunjukkan kinerja model saat menggunakan jumlah data yang dihasilkan berbeda (1%, 10%, 40%, 70%, 100%). Secara keseluruhan, seiring dengan peningkatan jumlah data yang dihasilkan, kinerja model juga meningkat, tetapi juga ada beberapa fluktuasi. Metode kami selalu lebih baik daripada baseline, yang membuktikan efektivitas dan ketahanan metode kami.
A.5. Estimasi Kontribusi
\ Dengan demikian, kami pada dasarnya menghitung kesamaan kosinus. Kemudian kami melakukan perbandingan eksperimental, seperti yang ditunjukkan pada Tabel 8,
\ 
\ 
\ kita dapat melihat bahwa jika kita menormalkan gradien, metode kita akan memiliki peningkatan tertentu. Selain itu, karena kita perlu menjaga dua ambang batas yang berbeda, sulit untuk memastikan konsistensi tingkat penerimaan. Jadi kami mengadopsi strategi ambang batas dinamis, menetapkan tingkat penerimaan terlebih dahulu, mempertahankan antrian untuk menyimpan kontribusi dari iterasi sebelumnya, dan kemudian secara dinamis menyesuaikan ambang batas sesuai dengan antrian, sehingga tingkat penerimaan tetap pada tingkat penerimaan yang telah ditetapkan sebelumnya.
A.6. Eksperimen Mainan
Berikut adalah pengaturan eksperimen spesifik yang diimplementasikan pada CIFAR-10: Kami menggunakan ResNet18 sederhana sebagai model dasar dan melakukan pelatihan selama 200 epoch, dan akurasi setelah pelatihan pada set pelatihan asli adalah 93,02%. Learning rate ditetapkan pada 0,1, menggunakan optimizer SGD. Momentum 0,9 berlaku, dengan weight decay 5e-4. Kami menggunakan penjadwal learning rate cosine annealing. Gambar bising yang dibangun ditunjukkan pada Gambar 6. Penurunan kualitas gambar diamati seiring dengan peningkatan tingkat noise. Terutama, ketika tingkat noise mencapai 200, gambar menjadi sangat sulit untuk diidentifikasi. Untuk Tabel 1, kami menggunakan Split1 sebagai R, sementara G terdiri dari 'Split2 + Noise40', 'Split3 + Noise100', 'Split4 + Noise200',
A.7. Penyederhanaan Hanya Forward Sekali
\
:::info Penulis:
(1) Muzhi Zhu, dengan kontribusi yang sama dari Universitas Zhejiang, China;
(2) Chengxiang Fan, dengan kontribusi yang sama dari Universitas Zhejiang, China;
(3) Hao Chen, Universitas Zhejiang, China ([email protected]);
(4) Yang Liu, Universitas Zhejiang, China;
(5) Weian Mao, Universitas Zhejiang, China dan Universitas Adelaide, Australia;
(6) Xiaogang Xu, Universitas Zhejiang, China;
(7) Chunhua Shen, Universitas Zhejiang, China ([email protected]).
:::
:::info Makalah ini tersedia di arxiv di bawah lisensi CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
\


Anda Mungkin Juga Menyukai

Bukan celah hukum: Kontrol ekspor AI Singapura memungkinkan Tiongkok mengakses AI AS secara legal

Futures Perpetual Bitcoin: Rasio Long/Short di Bursa Teratas

Ekosistem Token LAB: Panduan Platform Perdagangan Multi-Rantai & Imbalan



