

Ekstraksi Semantik Open-Set: Pipeline Grounded-SAM, CLIP, dan DINOv2
Tabel Tautan
Abstrak dan 1 Pendahuluan
-
Karya Terkait
2.1. Navigasi Visi-dan-Bahasa
2.2. Pemahaman Semantik Adegan dan Segmentasi Instance
2.3. Rekonstruksi Adegan 3D
-
Metodologi
3.1. Pengumpulan Data
3.2. Informasi Semantik Open-set dari Gambar
3.3. Membuat Representasi 3D Open-set
3.4. Navigasi Berbasis Bahasa
-
Eksperimen
4.1. Evaluasi Kuantitatif
4.2. Hasil Kualitatif
-
Kesimpulan dan Pekerjaan Masa Depan, Pernyataan Pengungkapan, dan Referensi
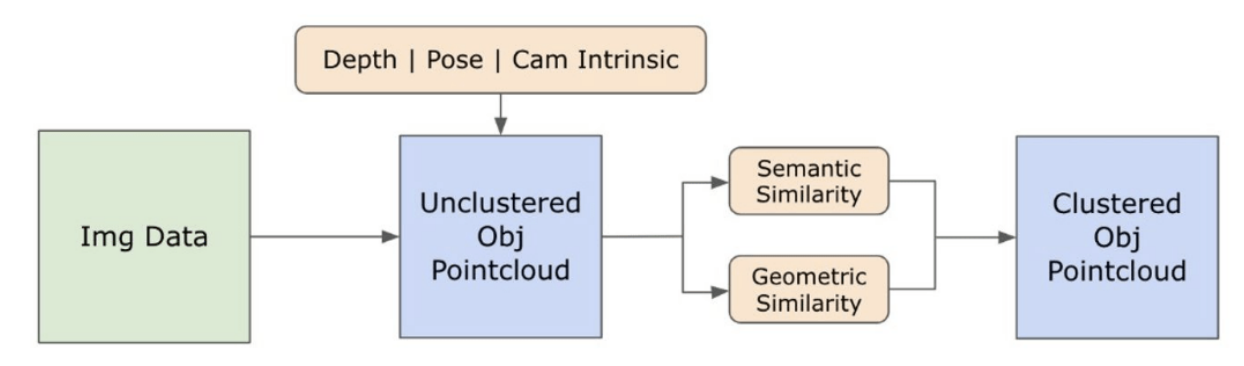
3.2. Informasi Semantik Open-set dari Gambar
\ 3.2.1. Deteksi Semantik Open-set dan Mask Instance
\ Model Segment Anything (SAM) [21] yang baru dirilis telah mendapatkan popularitas signifikan di kalangan peneliti dan praktisi industri karena kemampuan segmentasinya yang mutakhir. Namun, SAM cenderung menghasilkan jumlah mask segmentasi yang berlebihan untuk objek yang sama. Kami mengadopsi model Grounded-SAM [32] untuk metodologi kami untuk mengatasi hal ini. Proses ini melibatkan pembuatan serangkaian mask dalam tiga tahap, seperti yang digambarkan pada Gambar 2. Awalnya, serangkaian label teks dibuat menggunakan model Recognizing Anything (RAM) [33]. Selanjutnya, kotak pembatas yang sesuai dengan label-label ini dibuat menggunakan model Grounding DINO [25]. Gambar dan kotak pembatas kemudian dimasukkan ke dalam SAM untuk menghasilkan mask segmentasi agnostik-kelas untuk objek yang terlihat dalam gambar. Kami memberikan penjelasan rinci tentang pendekatan ini di bawah, yang secara efektif mengurangi masalah segmentasi berlebihan dengan menggabungkan wawasan semantik dari RAM dan Grounding-DINO.
\ Model RAM [33] memproses gambar RGB input untuk menghasilkan pelabelan semantik dari objek yang terdeteksi dalam gambar. Ini adalah model dasar yang kuat untuk penandaan gambar, menunjukkan kemampuan zero-shot yang luar biasa dalam mengidentifikasi berbagai kategori umum secara akurat. Output dari model ini mengaitkan setiap gambar input dengan serangkaian label yang menggambarkan kategori objek dalam gambar. Proses dimulai dengan mengakses gambar input dan mengubahnya ke ruang warna RGB, kemudian mengubah ukurannya agar sesuai dengan persyaratan input model, dan akhirnya mengubahnya menjadi tensor, membuatnya kompatibel dengan analisis oleh model. Setelah ini, model RAM menghasilkan label, atau tag, yang menggambarkan berbagai objek atau fitur yang ada dalam gambar. Proses filtrasi digunakan untuk menyaring label yang dihasilkan, yang melibatkan penghapusan kelas yang tidak diinginkan dari label-label ini. Secara khusus, tag yang tidak relevan seperti "dinding", "lantai", "langit-langit", dan "kantor" dibuang, bersama dengan kelas-kelas yang telah ditentukan sebelumnya yang dianggap tidak perlu untuk konteks penelitian. Selain itu, tahap ini memungkinkan untuk penambahan set label dengan kelas-kelas yang diperlukan yang tidak terdeteksi awalnya oleh model RAM. Akhirnya, semua informasi yang relevan dikumpulkan ke dalam format terstruktur. Secara khusus, setiap gambar dikatalogkan dalam kamus img_dict, yang mencatat jalur gambar bersama dengan set label yang dihasilkan, sehingga memastikan repositori data yang dapat diakses untuk analisis selanjutnya.
\ Setelah penandaan gambar input dengan label yang dihasilkan, alur kerja berlanjut dengan memanggil model Grounding DINO [25]. Model ini mengkhususkan diri dalam mendasarkan frasa tekstual ke wilayah tertentu dalam gambar, secara efektif menggambarkan objek target dengan kotak pembatas. Proses ini mengidentifikasi dan melokalisasi objek secara spasial dalam gambar, meletakkan dasar untuk analisis yang lebih terperinci. Setelah mengidentifikasi dan melokalisasi objek melalui kotak pembatas, Segment Anything Model (SAM) [21] digunakan. Fungsi utama model SAM adalah menghasilkan mask segmentasi untuk objek dalam kotak pembatas ini. Dengan melakukan hal ini, SAM mengisolasi objek individual, memungkinkan analisis yang lebih rinci dan spesifik objek dengan secara efektif memisahkan objek dari latar belakang dan satu sama lain dalam gambar.
\ Pada titik ini, instance objek telah diidentifikasi, dilokalisasi, dan diisolasi. Setiap objek diidentifikasi dengan berbagai detail, termasuk koordinat kotak pembatas, istilah deskriptif untuk objek, kemungkinan atau skor kepercayaan keberadaan objek yang dinyatakan dalam logit, dan mask segmentasi. Selain itu, setiap objek dikaitkan dengan fitur embedding CLIP dan DINOv2, yang detailnya dijelaskan dalam subbagian berikut.
\ 3.2.2. Ekstraksi Embedding Semantik
\ Untuk meningkatkan pemahaman kami tentang aspek semantik dari instance objek yang telah disegmentasi dan diberi mask dalam gambar kami, kami menggunakan dua model, CLIP [9] dan DINOv2 [10], untuk memperoleh representasi fitur dari gambar yang dipotong dari setiap objek. Model yang dilatih secara eksklusif dengan CLIP mencapai pemahaman semantik yang kuat tentang gambar tetapi tidak dapat membedakan kedalaman dan detail rumit dalam gambar tersebut. Di sisi lain, DINOv2 menunjukkan kinerja superior dalam persepsi kedalaman dan unggul dalam mengidentifikasi hubungan tingkat piksel yang halus di seluruh gambar. Sebagai Vision Transformer yang dilatih secara self-supervised, DINOv2 dapat mengekstrak detail fitur yang halus tanpa mengandalkan data beranotasi, membuatnya sangat efektif dalam mengidentifikasi hubungan spasial dan hierarki dalam gambar. Misalnya, sementara model CLIP mungkin kesulitan membedakan antara dua kursi dengan warna berbeda, seperti merah dan hijau, kemampuan DINOv2 memungkinkan perbedaan tersebut dibuat dengan jelas. Sebagai kesimpulan, model-model ini menangkap fitur semantik dan visual dari objek, yang kemudian digunakan untuk perbandingan kesamaan dalam ruang 3D.
\ 
\ Serangkaian langkah pra-pemrosesan diimplementasikan untuk memproses gambar dengan model DINOv2. Ini termasuk mengubah ukuran, pemotongan tengah, mengubah gambar menjadi tensor, dan menormalkan gambar yang dipotong yang dibatasi oleh kotak pembatas. Gambar yang diproses kemudian dimasukkan ke dalam model DINOv2 bersama dengan label yang diidentifikasi oleh model RAM untuk menghasilkan fitur embedding DINOv2. Di sisi lain, ketika berurusan dengan model CLIP, langkah pra-pemrosesan melibatkan transformasi gambar yang dipotong menjadi format tensor yang kompatibel dengan CLIP, diikuti dengan perhitungan fitur embedding. Embedding ini penting karena mereka merangkum atribut visual dan semantik objek, yang sangat penting untuk pemahaman komprehensif tentang objek dalam adegan. Embedding ini mengalami normalisasi berdasarkan norma L2 mereka, yang menyesuaikan vektor fitur ke panjang unit yang distandarisasi. Langkah normalisasi ini memungkinkan perbandingan yang konsisten dan adil di seluruh gambar yang berbeda.
\ Dalam fase implementasi tahap ini, kami melakukan iterasi pada setiap gambar dalam data kami dan menjalankan prosedur berikut:
\ (1) Gambar dipotong ke wilayah yang diminati menggunakan koordinat kotak pembatas yang disediakan oleh model Grounding DINO, mengisolasi objek untuk analisis rinci.
\ (2) Menghasilkan embedding DINOv2 dan CLIP untuk gambar yang dipotong.
\ (3) Akhirnya, embedding disimpan kembali bersama dengan mask dari bagian sebelumnya.
\ Dengan langkah-langkah ini selesai, kami sekarang memiliki representasi fitur rinci untuk setiap objek, memperkaya dataset kami untuk analisis dan aplikasi lebih lanjut.
\
:::info Penulis:
(1) Laksh Nanwani, International Institute of Information Technology, Hyderabad, India; penulis ini berkontribusi sama dalam pekerjaan ini;
(2) Kumaraditya Gupta, International Institute of Information Technology, Hyderabad, India;
(3) Aditya Mathur, International Institute of Information Technology, Hyderabad, India; penulis ini berkontribusi sama dalam pekerjaan ini;
(4) Swayam Agrawal, International Institute of Information Technology, Hyderabad, India;
(5) A.H. Abdul Hafez, Hasan Kalyoncu University, Sahinbey, Gaziantep, Turkey;
(6) K. Madhava Krishna, International Institute of Information Technology, Hyderabad, India.
:::
:::info Makalah ini tersedia di arxiv di bawah lisensi CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International).
:::
\


Anda Mungkin Juga Menyukai

Bukan celah hukum: Kontrol ekspor AI Singapura memungkinkan Tiongkok mengakses AI AS secara legal

Futures Perpetual Bitcoin: Rasio Long/Short di Bursa Teratas

Ketegangan di pasar energi menjadi penyebab kekhawatiran bagi stabilitas keuangan



