

Sintesis Gambar Medis: S-CycleGAN untuk RUSS dan Segmentasi
Tabel Tautan
Abstrak dan 1 Pendahuluan
-
Karya terkait
-
Pengaturan masalah
-
Metodologi
4.1. Distilasi berbasis batas keputusan
4.2. Konsolidasi pengetahuan
-
Hasil eksperimen dan 5.1. Pengaturan Eksperimen
5.2. Perbandingan dengan metode SOTA
5.3. Studi ablasi
-
Kesimpulan dan pekerjaan masa depan dan Referensi
\
Materi Tambahan
- Detail analisis teoretis pada mekanisme KCEMA dalam IIL
- Ikhtisar algoritma
- Detail dataset
- Detail implementasi
- Visualisasi gambar input berdebu
- Hasil eksperimen lebih lanjut
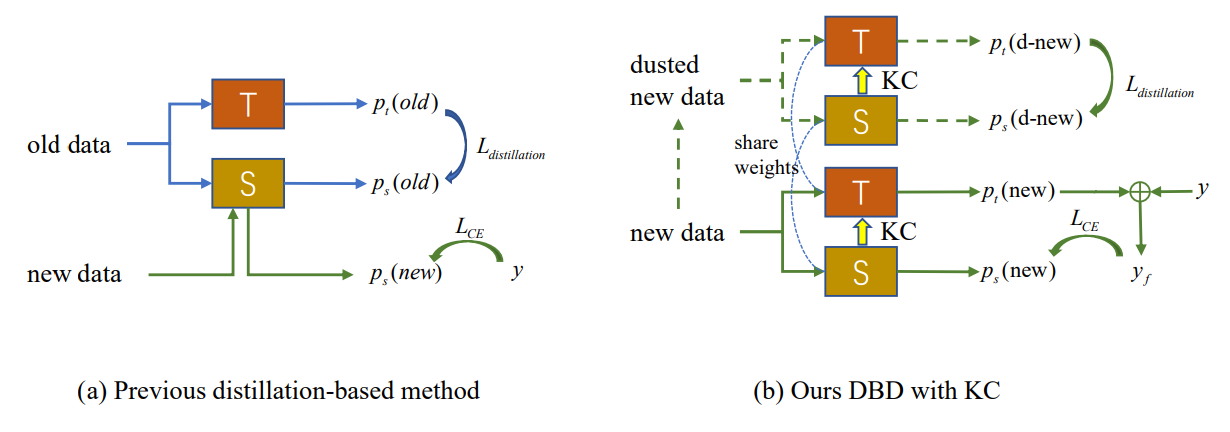
4. Metodologi
Seperti ditunjukkan pada Gbr. 2 (a), terjadinya pergeseran konsep dalam pengamatan baru menyebabkan munculnya sampel luar yang gagal ditangani oleh model yang ada. IIL baru harus memperluas batas keputusan ke sampel luar ini serta menghindari pelupaan katastrofik (CF) pada batas lama. Metode konvensional berbasis distilasi pengetahuan mengandalkan beberapa contoh yang dipertahankan [22] atau data tambahan [33, 34] untuk menahan CF. Namun, dalam pengaturan IIL yang diusulkan, kita tidak memiliki akses ke data lama selain pengamatan baru. Distilasi berdasarkan pengamatan baru ini bertentangan dengan pembelajaran pengetahuan baru jika tidak ada parameter baru yang ditambahkan ke model. Untuk menyeimbangkan antara belajar dan tidak melupakan, kami mengusulkan metode distilasi berbasis batas keputusan yang tidak memerlukan data lama. Selama pembelajaran, pengetahuan baru yang dipelajari oleh siswa secara berkala dikonsolidasikan kembali ke model guru, yang membawa generalisasi lebih baik dan merupakan upaya perintis di bidang ini.
\ 
\
:::info Penulis:
(1) Qiang Nie, Universitas Sains dan Teknologi Hong Kong (Guangzhou);
(2) Weifu Fu, Tencent Youtu Lab;
(3) Yuhuan Lin, Tencent Youtu Lab;
(4) Jialin Li, Tencent Youtu Lab;
(5) Yifeng Zhou, Tencent Youtu Lab;
(6) Yong Liu, Tencent Youtu Lab;
(7) Qiang Nie, Universitas Sains dan Teknologi Hong Kong (Guangzhou);
(8) Chengjie Wang, Tencent Youtu Lab.
:::
:::info Makalah ini tersedia di arxiv di bawah lisensi CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
\
Anda Mungkin Juga Menyukai

Koreksi Bitcoin: Mengapa Penurunan Sementara Ini Menandakan Peluang Beli yang Kuat

Pengajuan SEC terkait Bitcoin mencatat pertumbuhan rekor di tahun 2025, dengan kemajuan legislatif mendorong adopsi on-chain institusional.