

Google akan melatih AI dalam 21 bahasa Afrika, termasuk Yoruba, Hausa dan Igbo.
Google bersama konsortium institusi penyelidikan Afrika telah melancarkan dataset WAXAL, satu usaha baharu yang penting untuk menangani salah satu cabaran utama kecerdasan buatan (AI) di benua tersebut: ketidakmampuan AI untuk mentafsir dan memahami kebanyakan bahasa Afrika.
Projek ini menyediakan sebuah dataset suara besar dan terbuka yang merangkumi 21 bahasa Afrika Sub-Sahara, sekali gus membawa teknologi suara kepada lebih daripada 100 juta orang yang selama ini terpinggir daripada ekonomi AI.
Dataset WAXAL merupakan hasil kerjasama tiga tahun yang dibiayai oleh Google dan diketuai oleh universiti-universiti tempatan serta kumpulan komuniti.
Dataset ini mengandungi 1,250 jam transkripsi suara sebenar dan lebih daripada 20 jam rakaman berkualiti studio yang bertujuan untuk membina suara sintetik berketepatan tinggi. Dataset ini memberi tumpuan kepada bahasa-bahasa seperti Hausa, Yoruba, Luganda, Igbo, dan Acholi—bahasa-bahasa yang digunakan oleh puluhan juta penduduk, namun masih kurang diperhatikan oleh sistem-sistem suara komersial.

Walaupun banyak perbincangan tentang AI global, teknologi suara masih sangat tertumpu pada bahasa Inggeris dan segelintir bahasa Eropah serta Asia sahaja. Afrika, yang menjadi rumah bagi lebih daripada 2,000 bahasa, sebaliknya sering terpinggir.
Kesenjangan ini bukan sekadar isu akademik; ia turut menentukan siapa yang boleh menggunakan perkhidmatan digital, siapa yang dapat mengakses alat pendidikan dan penjagaan kesihatan, serta siapa yang mampu membina syarikat berteraskan platform AI moden. Google melihat usaha ini sebagai langkah untuk mengurangkan jurang data lama yang menyebabkan banyak bahasa Afrika tidak tersenarai dalam senarai asisten suara dan alat-alat lain.
Mengapa dataset WAXAL penting bagi arkitektur AI Afrika
Selain menangani ketidakseimbangan ini secara langsung, projek ini juga penting dari segi data itu sendiri.
Tidak seperti inisiatif terdahulu yang mana data suara Afrika diambil dan dimiliki oleh pihak luar, WAXAL diketuai sepenuhnya oleh institusi-institusi Afrika. Universiti Makerere di Uganda, Universiti Ghana, dan Digital Umuganda di Rwanda mengurus pengumpulan data, penyertaan komuniti, serta pengurusan bahasa, dengan sokongan teknikal daripada Google Research Africa.
Paling penting, institusi-institusi tersebut kekal memiliki hak milik ke atas data tersebut. Ini merupakan satu perubahan yang signifikan dalam bidang yang sering dikritik kerana cenderung mengulangi dinamik ekstraktif di bawah semangat “keterbukaan”.
Menurut Aisha Walcott-Bryant, Ketua Google Research Africa, “Impak terakhir WAXAL ialah pemberdayaan rakyat Afrika. Dataset ini menyediakan landasan penting bagi pelajar, penyelidik, dan usahawan untuk membina teknologi mengikut istilah mereka sendiri, dalam bahasa mereka sendiri, sekali gus mencapai lebih daripada 100 juta orang.”
“Kami menantikan para inovator Afrika menggunakan data ini untuk mencipta pelbagai perkara, daripada alat pendidikan baharu hingga perkhidmatan berteraskan suara yang membuka peluang ekonomi yang nyata di seluruh benua,” tambah beliau.
 Aisha Walcott-Bryant, Ketua Google Research Africa
Aisha Walcott-Bryant, Ketua Google Research Africa
Penyataan ini turut disokong oleh universiti-universiti yang terlibat. Joyce Nakatumba-Nabende, pensyarah kanan di Universiti Makerere, berkata:
“Agar AI dapat memberi impak sebenar di Afrika, ia harus berbicara dalam bahasa kami dan memahami konteks kami. Dataset WAXAL memberikan penyelidik kami data berkualiti tinggi yang diperlukan untuk membina teknologi suara yang mencerminkan komuniti kami yang unik. Di Uganda, dataset ini telah mengukuhkan kapasiti penyelidikan tempatan kami dan menyokong projek-projek baharu yang dipimpin oleh pelajar dan fakulti.”
Di Universiti Ghana, Profesor Madya Isaac Wiafe menekankan skala penyertaan awam:
“Bagi kami di Universiti Ghana, impak WAXAL bukan sekadar data itu sendiri. Dataset ini telah memberi kami keupayaan untuk membina sumber bahasa kami sendiri dan melatih generasi baharu penyelidik AI. Lebih daripada 7,000 sukarelawan menyertai kami kerana mereka ingin suara dan bahasa mereka turut terlibat dalam masa depan digital. Hari ini, usaha kolektif ini telah mencetuskan ekosistem inovasi dalam bidang seperti kesihatan, pendidikan, dan pertanian. Ini membuktikan bahawa apabila data wujud, peluang akan terbuka luas di mana-mana.”
Ada alasan untuk optimisme yang berhati-hati. Dataset suara terbuka dapat menurunkan halangan bagi startup dan penyelidik tempatan yang tidak mempunyai sumber untuk mengumpul data dalam skala besar. Selain itu, dataset ini juga dapat mengurangkan ketergantungan pada API luar negara yang jarang sekali menyokong bahasa Afrika dengan baik, jika tidak langsung tidak menyokong sama sekali.
 Dataset WAXAL
Dataset WAXAL
Namun begitu, dataset tidak menjamin hasil; pembinaan sistem suara yang boleh dipercayai memerlukan pelaburan berterusan, pelaksanaan di peringkat tempatan, serta saluran komersial yang memastikan nilai tetap berada di dalam negara. Peranan Google sebagai pembiaya dan penganjur pasti akan menjadi tumpuan, terutama berkaitan cara data WAXAL digunakan oleh syarikat global pada masa hadapan.
Pada masa ini, pelancaran dataset WAXAL menandakan satu langkah konkret menuju ekosistem AI yang lebih inklusif dari segi bahasa. Dataset ini tidak menyelesaikan semua cabaran AI Afrika, tetapi ia menangani satu aspek asas. Suara sering kali merupakan antara antara muka paling semula jadi untuk berinteraksi dengan teknologi. Memastikan AI dapat mendengar Afrika berbicara, dalam segala kepelbagaiannya, sepatutnya sudah lama dilaksanakan.
Artikel Google akan melatih AI dalam 21 bahasa Afrika, termasuk Yoruba, Hausa, dan Igbo, pertama kali diterbitkan di Technext.
Anda Mungkin Juga Suka
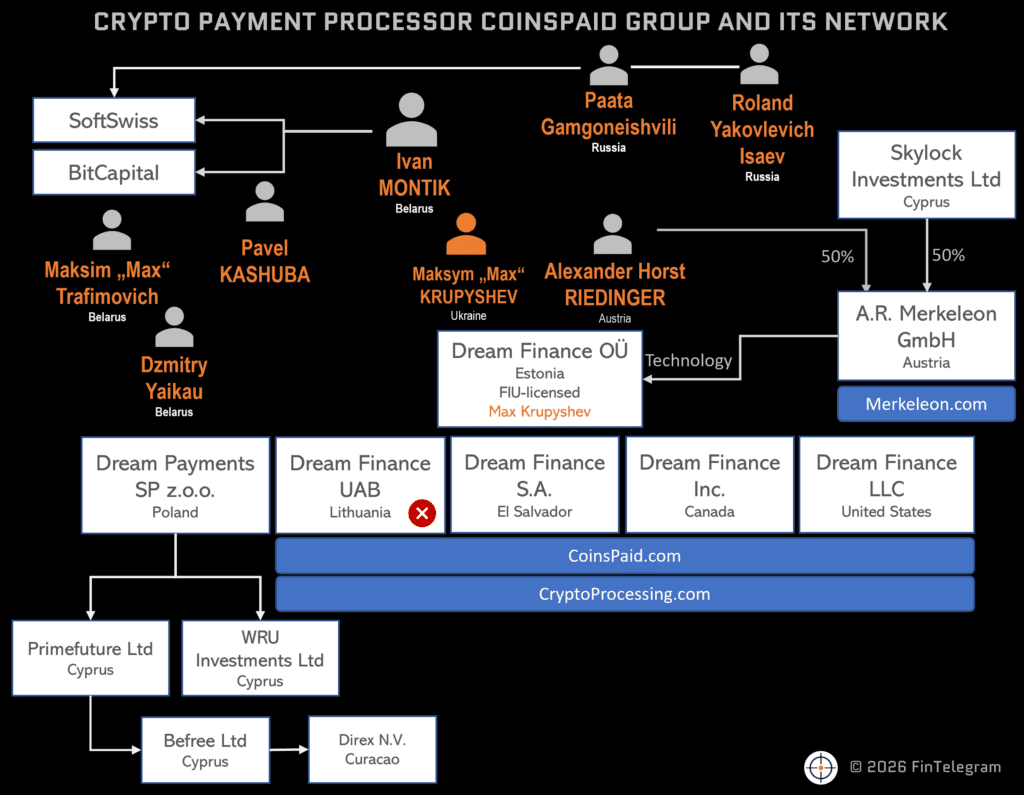
MiCA Guillotine Sekali Lagi: CoinsPaid (Dream Finance) Menyertai utPay dalam Senarai Hitam Peraturan Lithuania
Dalam satu lagi tamparan keras kepada industri kripto, CoinsPaid (sebelum ini dikenali sebagai Dream Finance), sebuah platform pembayaran digital yang berfokus pada aset kripto, telah tersenarai dalam senarai hitam peraturan oleh Suruhanjaya Kewangan Lithuania. Langkah ini menambahkan kekecewaan terhadap pelaksanaan undang-undang Pasaran Aset Digital Eropah (MiCA), yang sepatutnya menjadi tonggak penting bagi pengawalseliaan industri kripto di benua tersebut.
CoinsPaid bukanlah satu-satunya syarikat yang mengalami nasib serupa. Sebelum ini, utPay, sebuah penyedia perkhidmatan pembayaran digital yang juga beroperasi dalam ruang kripto, telah disekat daripada menyediakan perkhidmatan di Lithuania atas alasan ketidakpatuhan terhadap garis panduan MiCA. Keputusan ini menunjukkan bahawa walaupun MiCA telah diluluskan, pelaksanaannya masih menghadapi cabaran besar dalam menyeimbangkan inovasi teknologi dengan keperluan pengawalseliaan yang ketat.
Menurut laporan terbaru, CoinsPaid didakwa gagal mematuhi beberapa piawaian penting yang ditetapkan oleh MiCA, termasuk pengesahan identiti pengguna, pemantauan aktiviti transaksi mencurigakan, serta pengendalian dana pelanggan secara telus dan selamat. Pihak berkuasa Lithuania mendakwa bahawa syarikat tersebut tidak menunjukkan komitmen yang cukup untuk memastikan keselamatan dan integriti sistem kewangan mereka.
Keputusan ini turut menimbulkan persoalan tentang tahap kesiapan pelaksanaan MiCA di negara-negara Eropah lain. Walaupun undang-undang ini dirancang untuk membentuk landskap kripto yang lebih selamat dan terjamin, kegagalan beberapa pihak untuk mematuhi peraturan tersebut menunjukkan bahawa masih terdapat jurang antara dasar dan pelaksanaan. Ini juga menyerlahkan keperluan bagi kerajaan dan institusi kewangan untuk bekerjasama dengan lebih rapat bagi memastikan keberkesanan undang-undang tersebut.
Bagi para pelabur dan pengguna kripto, langkah ini merupakan pengingat bahawa industri ini masih berada dalam fasa awal perkembangan. Walaupun MiCA dijangka memberikan kestabilan dan kepercayaan kepada pasaran, ia juga memerlukan masa untuk benar-benar diterima pakai sepenuhnya. Sementara itu, CoinsPaid dan utPay kini terpaksa mencari jalan alternatif untuk terus beroperasi, sama ada melalui penyesuaian peraturan atau mencari pasaran baharu yang lebih mesra.
Dengan keputusan ini, kita dapat melihat bahawa perjalanan menuju pengawalseliaan yang sempurna bagi industri kripto masih panjang. Namun, langkah-langkah seperti ini bukan sahaja menguji ketahanan industri, tetapi juga membuka ruang untuk pembaharuan dan penambahbaikan dalam usaha mencipta ekosistem kripto yang lebih selamat dan mampan.
Key Points
- CoinsPaid dan utPay telah disenarai hitam oleh Suruhanjaya Kewangan Lithuania atas alasan ketidakpatuhan terhadap MiCA.
- Pelaksanaan MiCA masih menghadapi cabaran dalam menyeimbangkan inovasi teknologi dengan keperluan pengawalseliaan yang ketat.
- Keputusan ini menunjukkan perlunya kerjasama antara kerajaan, institusi kewangan, dan pemain industri untuk memastikan keberkesanan undang-undang.
- Industri kripto masih berada dalam fasa awal perkembangan, dan langkah-langkah seperti ini akan membantu mendorong pembaharuan dalam usaha mencipta ekosistem yang lebih selamat.
Disclaimer:
Kandungan ini adalah hasil terjemahan yang bertujuan untuk memberikan maklumat umum sahaja. Sebarang keputusan atau tindakan yang dibuat berdasarkan maklumat ini adalah tanggungjawab pembaca sendiri. Kami tidak bertanggungjawab terhadap sebarang kerugian atau akibat yang timbul daripada penggunaan maklumat ini.
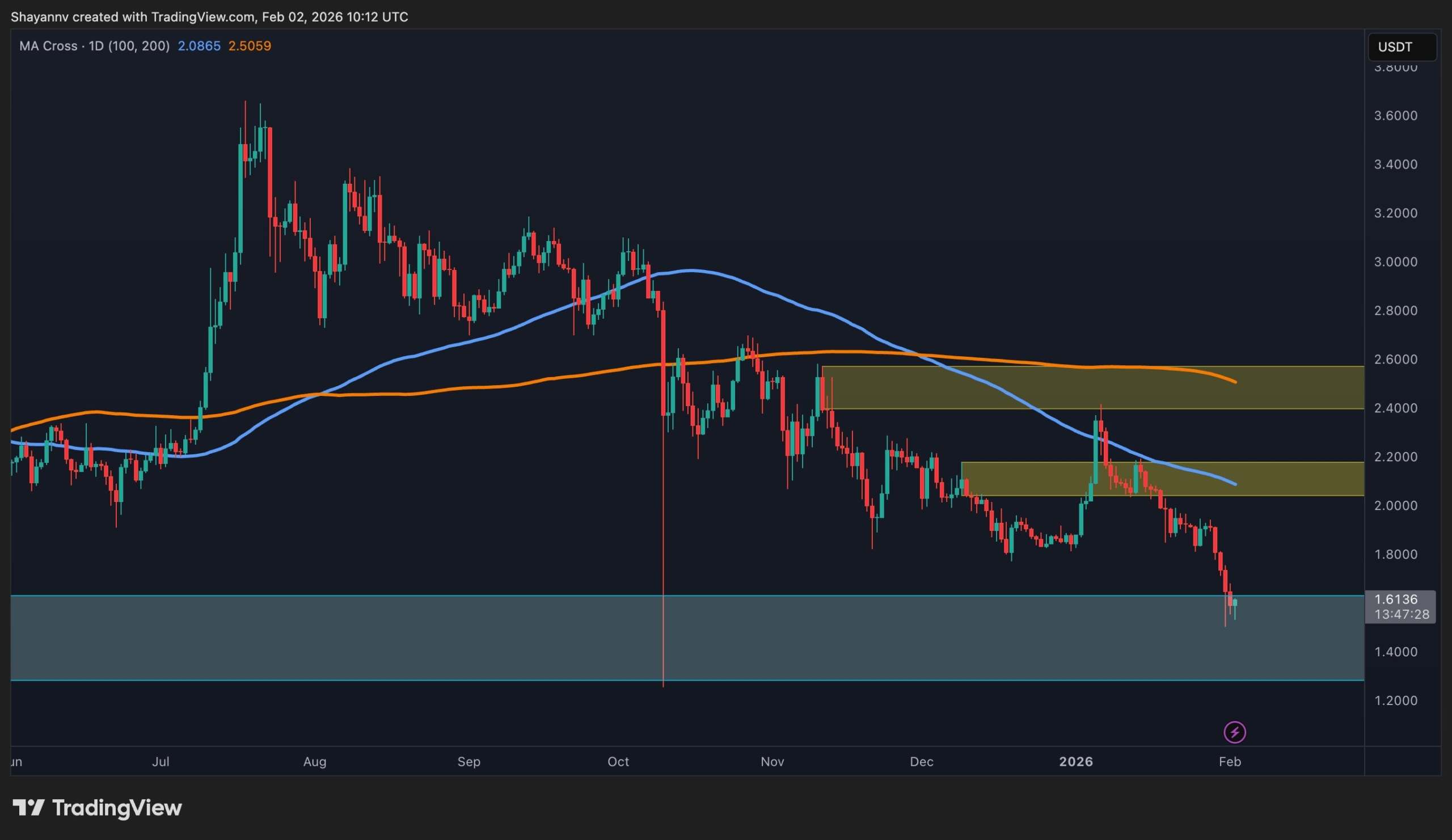
Analisis Harga Ripple: Adakah Pasaran Bear XRP Sudah Bermula?
Ripple, salah satu projek blockchain terkemuka, telah lama menjadi perhatian dalam dunia kripto. Namun, prestasi harga XRP sejak beberapa bulan kebelakangan ini menimbulkan tanda tanya besar: adakah pasaran bear yang panjang bagi XRP sudah bermula?
Apa Itu Ripple dan XRP?
Ripple adalah sebuah rangkaian pembayaran global yang menggunakan teknologi blockchain untuk mempercepat transaksi antara institusi kewangan. Mata wang digitalnya, XRP, berfungsi sebagai mata wang pertukaran dalam ekosistem Ripple. Sejak pelancarannya pada tahun 2012, XRP telah menjadi salah satu aset kripto paling popular di pasaran, tetapi prestasinya sering kali bergantung pada sentimen pasaran dan perkembangan dalam industri kripto secara keseluruhan.
Mengapa Pasaran Bear XRP Penting?
Pasaran bear merujuk kepada tempoh penurunan harga yang berpanjangan dalam pasaran kripto. Bagi para pelabur, pasaran bear bukan sahaja membawa risiko kerugian, tetapi juga memberikan peluang untuk mengumpul aset pada harga yang lebih rendah. Namun, bagi mereka yang masih baru dalam dunia kripto, pasaran bear boleh menjadi situasi yang mencabar, terutama jika tidak memahami faktor-faktor yang menyebabkan penurunan harga.
Analisis Teknikal: Apakah Tanda-tanda Pasaran Bear Telah Muncul?
Melalui analisis teknikal, para pakar melihat beberapa petunjuk bahawa pasaran bear mungkin sedang berlaku. Indikator seperti Moving Average Convergence Divergence (MACD) dan Relative Strength Index (RSI) menunjukkan trend penurunan yang stabil. Selain itu, volume perdagangan XRP juga menurun, menandakan kurangnya minat daripada pelabur institusi dan individu.
Namun, ada juga pandangan yang optimis. Beberapa penganalisis percaya bahawa penurunan harga XRP mungkin hanya bersifat sementara, dan harga akan kembali meningkat apabila penggunaan teknologi Ripple semakin meluas. Ini termasuk integrasi dengan bank-bank utama dan penyelesaian masalah skalabiliti yang masih menjadi isu utama bagi Ripple.
Apa Langkah yang Perlu Diambil?
Bagi pelabur yang ingin terus berinvestasi dalam XRP, penting untuk memahami risiko yang terlibat. Jika anda masih baru dalam dunia kripto, disarankan untuk melakukan penyelidikan mendalam tentang projek Ripple dan mempertimbangkan strategi pengurusan risiko yang sesuai. Selain itu, sentiasa mengikuti berita terkini mengenai perkembangan dalam industri kripto dan teknologi blockchain.
Kesimpulan
Pasaran bear XRP belum pasti lagi, tetapi ia merupakan masa yang tepat untuk menilai semula strategi pelaburan anda. Walaupun pasaran bear boleh menjadi cabaran, ia juga memberikan peluang untuk memperoleh aset pada harga yang lebih rendah. Oleh itu, jangan lupa untuk sentiasa mengikuti perkembangan terkini dan membuat keputusan berdasarkan maklumat yang tepat.
Key Points:
- Pasaran bear XRP mungkin sudah bermula, namun masih terdapat peluang untuk pelabur yang bijak.
- Analisis teknikal menunjukkan trend penurunan yang stabil, tetapi sentiasa ada kemungkinan pemulihan.
- Pelabur harus mempertimbangkan risiko dan menguruskan portfolio dengan teliti.
Disclaimer: Maklumat dalam artikel ini adalah untuk tujuan maklumat sahaja dan tidak boleh dianggap sebagai nasihat pelaburan. Pelabur dinasihatkan untuk melakukan penyelidikan sendiri sebelum membuat keputusan pelaburan.
