

Solusi Kelangkaan Data: S-CycleGAN untuk Terjemahan CT-ke-Ultrasound
Tabel Tautan
Abstrak dan 1 Pendahuluan
-
Karya terkait
-
Pengaturan masalah
-
Metodologi
4.1. Distilasi berbasis batas keputusan
4.2. Konsolidasi pengetahuan
-
Hasil eksperimen dan 5.1. Pengaturan Eksperimen
5.2. Perbandingan dengan metode SOTA
5.3. Studi ablasi
-
Kesimpulan dan pekerjaan masa depan dan Referensi
\
Materi Tambahan
- Detail analisis teoretis pada mekanisme KCEMA dalam IIL
- Ikhtisar algoritma
- Detail dataset
- Detail implementasi
- Visualisasi gambar input berdebu
- Hasil eksperimen lebih lanjut
Abstrak
Pembelajaran inkremental berbasis instans (IIL) berfokus pada pembelajaran berkelanjutan dengan data dari kelas yang sama. Dibandingkan dengan pembelajaran inkremental berbasis kelas (CIL), IIL jarang dieksplorasi karena IIL kurang menderita dari kelupaan katastrofik (CF). Namun, selain mempertahankan pengetahuan, dalam skenario penerapan dunia nyata di mana ruang kelas selalu telah ditentukan sebelumnya, promosi model yang berkelanjutan dan hemat biaya dengan potensi ketidaktersediaan data sebelumnya adalah kebutuhan yang lebih penting. Oleh karena itu, kami pertama-tama mendefinisikan pengaturan IIL baru dan lebih praktis sebagai meningkatkan kinerja model selain menahan CF hanya dengan pengamatan baru. Dua masalah harus ditangani dalam pengaturan IIL baru: 1) kelupaan katastrofik yang terkenal karena tidak ada akses ke data lama, dan 2) memperluas batas keputusan yang ada untuk pengamatan baru karena pergeseran konsep. Untuk mengatasi masalah ini, wawasan utama kami adalah memperluas batas keputusan secara moderat untuk kasus kegagalan sambil mempertahankan batas lama. Oleh karena itu, kami mengusulkan metode distilasi berbasis batas keputusan baru dengan mengkonsolidasikan pengetahuan kepada guru untuk memudahkan siswa mempelajari pengetahuan baru. Kami juga menetapkan tolok ukur pada dataset yang ada seperti Cifar-100 dan ImageNet. Terutama, eksperimen ekstensif menunjukkan bahwa model guru dapat menjadi pembelajar inkremental yang lebih baik daripada model siswa, yang membalikkan metode berbasis distilasi pengetahuan sebelumnya yang memperlakukan siswa sebagai peran utama.
1. Pendahuluan
Dalam beberapa tahun terakhir, banyak jaringan berbasis pembelajaran mendalam yang sangat baik diusulkan untuk berbagai tugas, seperti klasifikasi gambar, segmentasi, dan deteksi. Meskipun jaringan ini berkinerja baik pada data pelatihan, mereka pasti gagal pada beberapa data baru yang tidak dilatih dalam aplikasi dunia nyata. Terus-menerus dan secara efisien meningkatkan kinerja model yang diterapkan pada data baru ini adalah kebutuhan penting. Solusi saat ini untuk melatih ulang jaringan menggunakan semua data yang terakumulasi memiliki dua kelemahan: 1) dengan meningkatnya ukuran data, biaya pelatihan semakin tinggi setiap kali, misalnya, lebih banyak jam GPU dan jejak karbon yang lebih besar [20], dan 2) dalam beberapa kasus data lama tidak lagi dapat diakses karena kebijakan privasi atau anggaran terbatas untuk penyimpanan data. Dalam kasus di mana hanya sedikit atau tidak ada data lama yang tersedia atau digunakan, melatih ulang model pembelajaran mendalam dengan data baru selalu menyebabkan penurunan kinerja pada data lama, yaitu, masalah kelupaan katastrofik (CF). Untuk mengatasi masalah CF, pembelajaran inkremental [4, 5, 22, 29], juga dikenal sebagai pembelajaran berkelanjutan, diusulkan. Pembelajaran inkremental secara signifikan meningkatkan nilai praktis model pembelajaran mendalam dan menarik minat penelitian yang intens.
\ 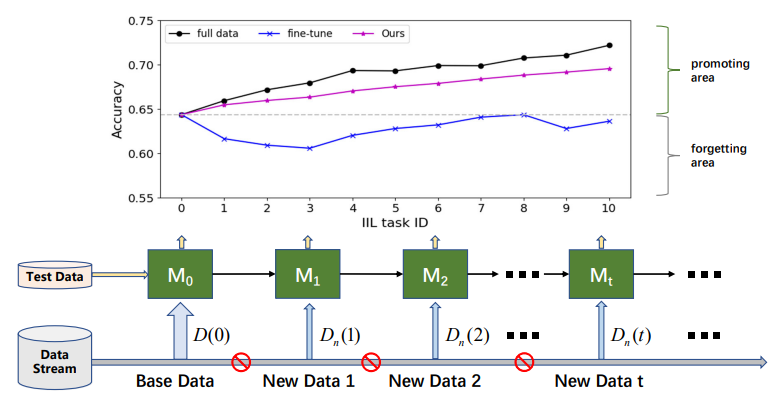
\ Menurut apakah data baru berasal dari kelas yang telah dilihat, pembelajaran inkremental dapat dibagi menjadi tiga skenario [16, 17]: pembelajaran inkremental berbasis instans (IIL) [3, 16] di mana semua data baru termasuk dalam kelas yang telah dilihat, pembelajaran inkremental berbasis kelas (CIL) [4, 12, 15, 22] di mana data baru memiliki label kelas yang berbeda, dan pembelajaran inkremental hibrida [6, 30] di mana data baru terdiri dari pengamatan baru dari kelas lama dan baru. Dibandingkan dengan CIL, IIL relatif kurang dieksplorasi karena kurang rentan terhadap CF. Lomonaco dan Maltoni [16] melaporkan bahwa fine-tuning model dengan penghentian dini dapat menjinakkan masalah CF dengan baik dalam IIL. Namun, kesimpulan ini tidak selalu berlaku ketika tidak ada akses ke data pelatihan lama dan data baru memiliki ukuran yang jauh lebih kecil daripada data lama, seperti yang digambarkan pada Gambar 1. Fine-tuning sering menghasilkan pergeseran dalam batas keputusan daripada memperluas batas tersebut untuk mengakomodasi pengamatan baru. Selain mempertahankan pengetahuan lama, penerapan nyata lebih memperhatikan promosi model yang efisien dalam IIL. Misalnya, dalam deteksi cacat produk industri, kelas cacat selalu terbatas pada kategori yang diketahui. Tetapi morfologi cacat tersebut bervariasi dari waktu ke waktu. Kegagalan pada cacat yang belum terlihat harus diperbaiki secara tepat waktu dan efisien untuk menghindari produk cacat mengalir ke pasar. Sayangnya, penelitian yang ada terutama berfokus pada mempertahankan pengetahuan pada data lama daripada memperkaya pengetahuan dengan pengamatan baru.
\ Dalam makalah ini, untuk meningkatkan model terlatih dengan cepat dan hemat biaya dengan pengamatan baru dari kelas yang telah dilihat, kami pertama-tama mendefinisikan pengaturan IIL baru sebagai mempertahankan pengetahuan yang dipelajari serta meningkatkan kinerja model pada pengamatan baru tanpa akses ke data lama. Dengan kata sederhana, kami bertujuan untuk meningkatkan model yang ada hanya dengan memanfaatkan data baru dan mencapai kinerja yang sebanding dengan model yang dilatih ulang dengan semua data yang terakumulasi. IIL baru ini menantang karena pergeseran konsep [6] yang disebabkan oleh pengamatan baru, seperti variasi warna atau bentuk dibandingkan dengan data lama. Oleh karena itu, dua masalah harus ditangani dalam pengaturan IIL baru: 1) kelupaan katastrofik yang terkenal karena tidak ada akses ke data lama, dan 2) memperluas batas keputusan yang ada untuk pengamatan baru.
\ Untuk mengatasi masalah di atas dalam pengaturan IIL baru, kami mengusulkan kerangka kerja IIL baru berdasarkan struktur guru-siswa. Kerangka kerja yang diusulkan terdiri dari proses distilasi berbasis batas keputusan (DBD) dan proses konsolidasi pengetahuan (KC). DBD memungkinkan model siswa untuk belajar dari pengamatan baru dengan kesadaran akan batas keputusan antar-kelas yang ada, yang memungkinkan model untuk menentukan di mana memperkuat pengetahuannya dan di mana mempertahankannya. Namun, batas keputusan tidak dapat dilacak ketika ada sampel yang tidak cukup yang terletak di sekitar batas karena tidak ada akses ke data lama dalam IIL. Untuk mengatasi hal ini, kami terinspirasi dari praktik menaburkan tepung di lantai untuk mengungkapkan jejak kaki tersembunyi. Demikian pula, kami memperkenalkan noise Gaussian acak untuk mencemari ruang input dan memanifestasikan batas keputusan yang dipelajari untuk distilasi. Selama melatih model siswa dengan distilasi batas, pengetahuan yang diperbarui lebih lanjut dikonsolidasikan kembali ke model guru secara intermiten dan berulang dengan mekanisme EMA [28]. Menggunakan model guru sebagai model target adalah upaya perintis dan kelayakannya dijelaskan secara teoretis.
\ Sesuai dengan pengaturan IIL baru, kami mengatur ulang set pelatihan dari beberapa dataset yang ada yang umum digunakan dalam CIL, seperti Cifar-100 [11] dan ImageNet [24] untuk menetapkan tolok ukur. Model dievaluasi pada data uji serta data dasar yang tidak tersedia di setiap fase inkremental. Kontribusi utama kami dapat dirangkum sebagai berikut: 1) Kami mendefinisikan pengaturan IIL baru untuk mencari promosi model yang cepat dan hemat biaya pada pengamatan baru dan menetapkan tolok ukur; 2) Kami mengusulkan metode distilasi berbasis batas keputusan baru untuk mempertahankan pengetahuan yang dipelajari serta memperkayanya dengan data baru; 3) Kami secara kreatif mengkonsolidasikan pengetahuan yang dipelajari dari siswa ke model guru untuk mencapai kinerja dan generalisasi yang lebih baik, dan membuktikan kelayakannya secara teoretis; dan 4) Eksperimen ekstensif menunjukkan bahwa metode yang diusulkan mengakumulasi pengetahuan dengan baik hanya dengan data baru sementara sebagian besar metode pembelajaran inkremental yang ada gagal.
\
:::info Makalah ini tersedia di arxiv di bawah lisensi CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
:::info Penulis:
(1) Qiang Nie, Hong Kong University of Science and Technology (Guangzhou);
(2) Weifu Fu, Tencent Youtu Lab;
(3) Yuhuan Lin, Tencent Youtu Lab;
(4) Jialin Li, Tencent Youtu Lab;
(5) Yifeng Zhou, Tencent Youtu Lab;
(6) Yong Liu, Tencent Youtu Lab;
(7) Qiang Nie, Hong Kong University of Science and Technology (Guangzhou);
(8) Chengjie Wang, Tencent Youtu Lab.
:::
\


Anda Mungkin Juga Menyukai

Kandidat Partai Republik sayap kanan dilarang masuk ke Inggris beberapa hari setelah membual akan pergi ke sana

'Dissent yang Menusuk!' Ketanji Brown Jackson Menegur Rekan-rekan Mahkamah Agung




