

Matting Terpandu Mask yang Robust: Mengelola Input Berisik dan Keserbagunaan Objek
Daftar Tautan
Abstrak dan 1. Pendahuluan
-
Karya Terkait
-
MaGGIe
3.1. Efficient Masked Guided Instance Matting
3.2. Feature-Matte Temporal Consistency
-
Dataset Instance Matting
4.1. Image Instance Matting dan 4.2. Video Instance Matting
-
Eksperimen
5.1. Pra-pelatihan pada data gambar
5.2. Pelatihan pada data video
-
Diskusi dan Referensi
\ Materi Tambahan
-
Detail arsitektur
-
Image matting
8.1. Pembuatan dan persiapan dataset
8.2. Detail pelatihan
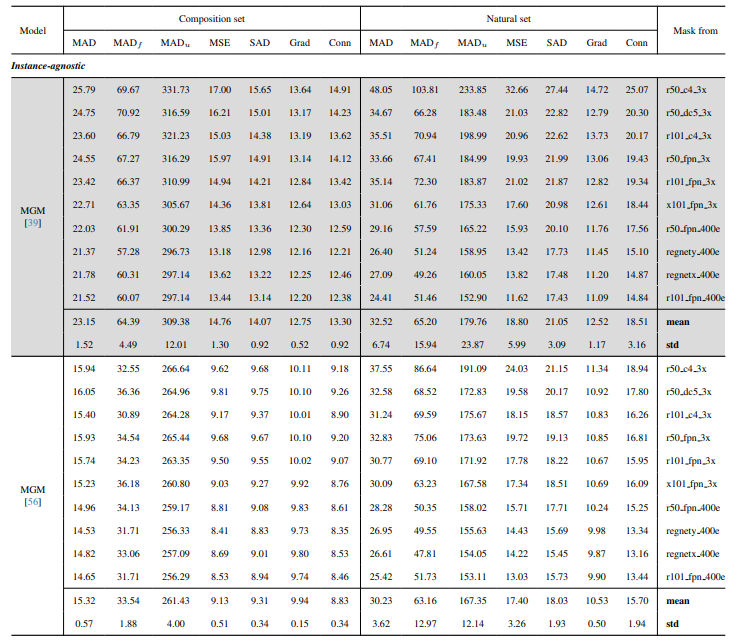
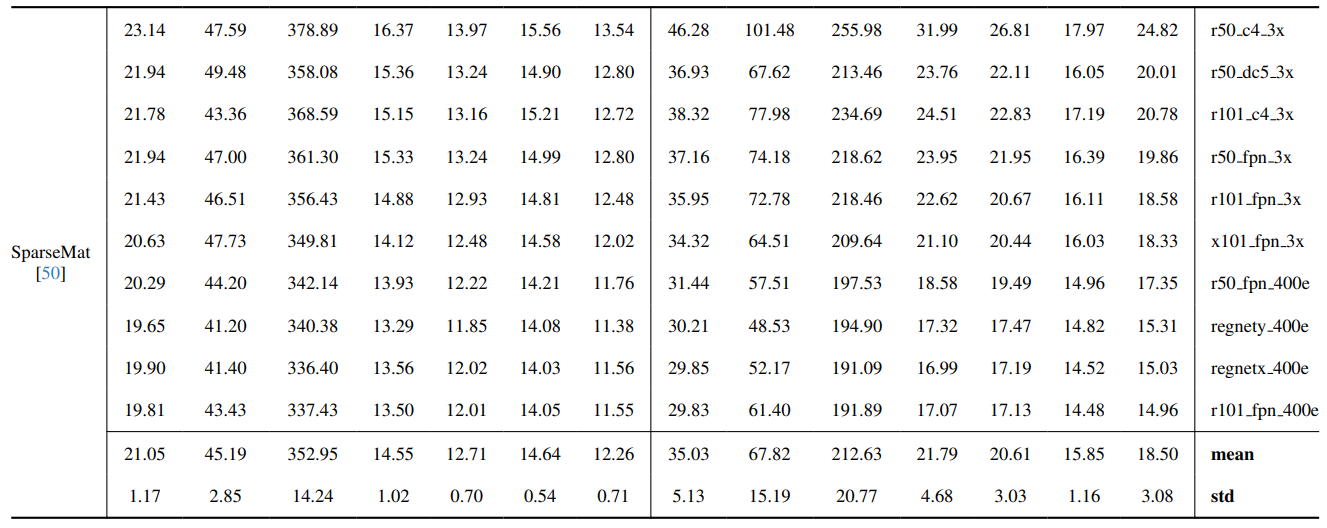
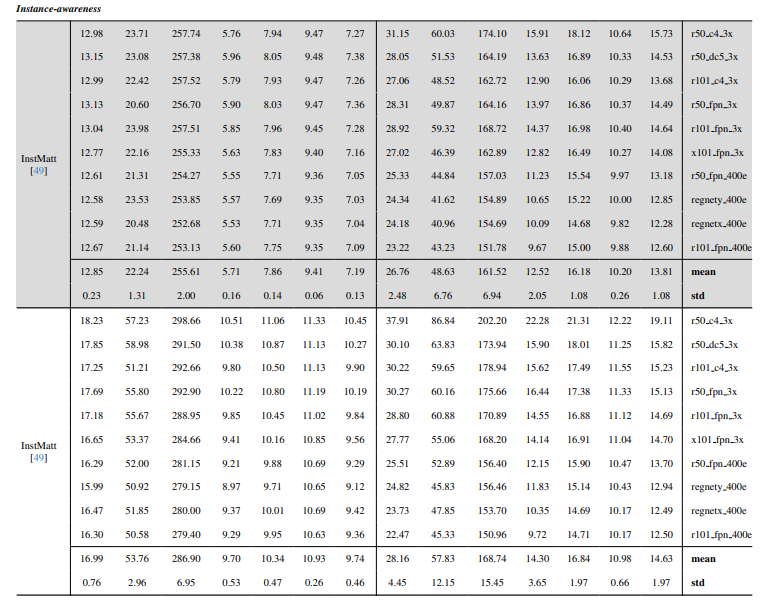
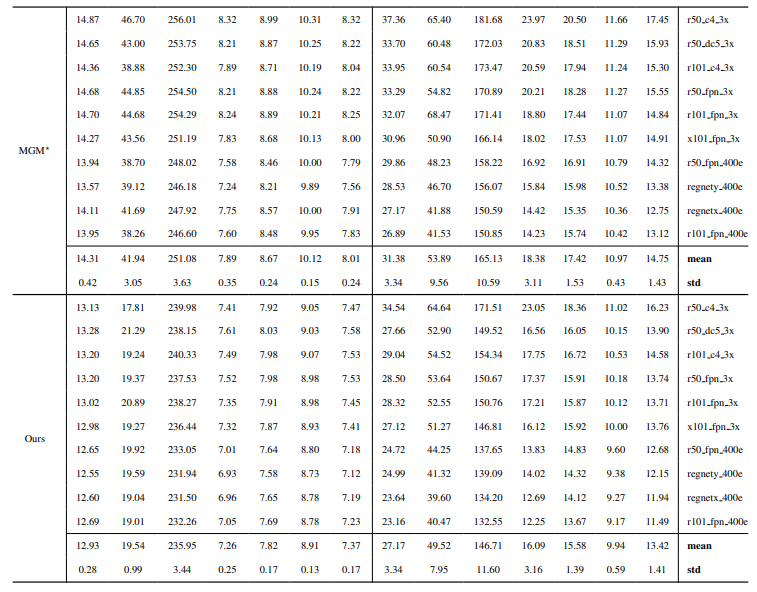
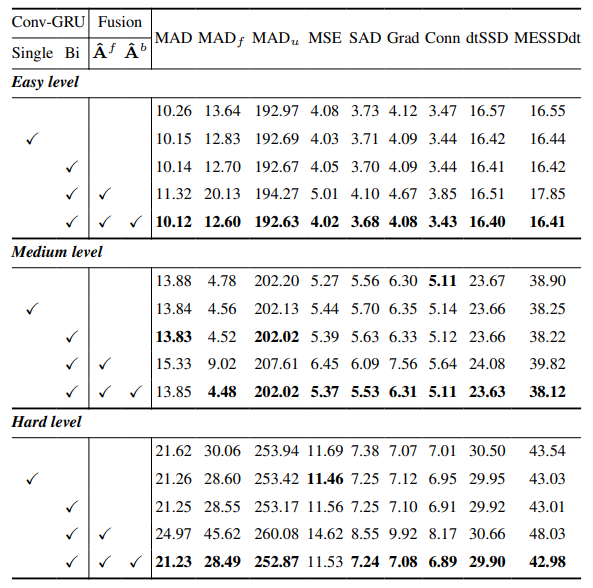
8.3. Detail kuantitatif
8.4. Lebih banyak hasil kualitatif pada gambar alami
-
Video matting
9.1. Pembuatan dataset
9.2. Detail pelatihan
9.3. Detail kuantitatif
9.4. Lebih banyak hasil kualitatif
8.4. Lebih banyak hasil kualitatif pada gambar alami
Gambar 13 menampilkan kinerja model kami dalam skenario yang menantang, khususnya dalam merender area rambut secara akurat. Framework kami secara konsisten mengungguli MGM⋆ dalam preservasi detail, terutama dalam interaksi instance yang kompleks. Dibandingkan dengan InstMatt, model kami menunjukkan pemisahan instance dan akurasi detail yang superior di area yang ambigu.
\ Gambar 14 dan Gambar 15 mengilustrasikan kinerja model kami dan karya sebelumnya dalam kasus ekstrem yang melibatkan banyak instance. Sementara MGM⋆ kesulitan dengan noise dan akurasi dalam skenario instance yang padat, model kami mempertahankan presisi tinggi. InstMatt, tanpa data pelatihan tambahan, menunjukkan keterbatasan dalam pengaturan kompleks ini.
\ Ketahanan pendekatan mask-guided kami ditunjukkan lebih lanjut pada Gambar 16. Di sini, kami menyoroti tantangan yang dihadapi oleh varian MGM dan SparseMat dalam memprediksi bagian yang hilang pada input mask, yang diatasi oleh model kami. Namun, penting untuk dicatat bahwa model kami tidak dirancang sebagai jaringan segmentasi instance manusia. Seperti ditunjukkan pada Gambar 17, framework kami mematuhi panduan input, memastikan prediksi alpha matte yang presisi bahkan dengan beberapa instance dalam mask yang sama.
\ Terakhir, Gambar 12 dan Gambar 11 menekankan kemampuan generalisasi model kami. Model secara akurat mengekstrak subjek manusia dan objek lainnya dari latar belakang, menunjukkan keserbagunaan di berbagai skenario dan jenis objek.
\ Semua contoh adalah gambar Internet tanpa ground-truth dan mask dari r101fpn400e digunakan sebagai panduan.
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\
:::info Penulis:
(1) Chuong Huynh, University of Maryland, College Park ([email protected]);
(2) Seoung Wug Oh, Adobe Research (seoh,[email protected]);
(3) Abhinav Shrivastava, University of Maryland, College Park ([email protected]);
(4) Joon-Young Lee, Adobe Research ([email protected]).
:::
:::info Makalah ini tersedia di arxiv di bawah lisensi CC by 4.0 Deed (Attribution 4.0 International).
:::
\


Anda Mungkin Juga Menyukai

Bukan celah hukum: Kontrol ekspor AI Singapura memungkinkan Tiongkok mengakses AI AS secara legal

Nigeria menginvestasikan $9 juta dalam penelitian untuk mendorong ambisi ekonomi digital

Futures Perpetual Bitcoin: Rasio Long/Short di Bursa Teratas



