

Mengoptimalkan Biaya dan Pemanfaatan Kluster Databricks Tanpa Tabel Sistem

Di sebagian besar lingkungan Databricks enterprise (seperti di MSC atau ekosistem analitik besar), tabel sistem seperti system.job_run_logs atau system.cluster_events mungkin dibatasi atau dinonaktifkan karena kebijakan keamanan atau tata kelola.
Namun, melacak utilisasi cluster dan biaya sangat penting untuk:
- Memahami seberapa efisien job menggunakan komputasi
- Mengidentifikasi cluster yang menganggur atau kebocoran biaya
- Memperkirakan anggaran infrastruktur
- Membangun dashboard biaya kustom
Blog ini mendemonstrasikan pendekatan langkah demi langkah untuk menghitung utilisasi cluster dan biaya hanya menggunakan Databricks REST API — tidak memerlukan tabel sistem.
Kasus Penggunaan Proyek
Di platform data MSC kami, kami menjalankan beberapa cluster Databricks di lingkungan development, test, dan production. \n Kami memiliki tiga tantangan utama:
- Tidak ada akses ke tabel sistem (dibatasi oleh kebijakan admin)
- Cluster ephemeral untuk job yang dibuat secara dinamis oleh ADF atau pipeline orkestrasi
- Tidak ada tampilan langsung tentang bagaimana utilisasi cluster diterjemahkan ke biaya
Oleh karena itu, kami membangun penganalisis utilisasi ringan yang:
- Menarik data dari Databricks REST API
- Menghitung waktu eksekusi job vs waktu eksekusi cluster
- Memperkirakan biaya menggunakan tarif DBU dan VM
- Menghasilkan DataFrame yang mudah dikonsumsi
Masalah & pendekatan
Tantangan yang teridentifikasi
Tim sering perlu mengetahui:
- Cluster mana yang menganggur (berjalan dengan aktivitas job yang rendah)?
- Berapa % utilisasi (waktu eksekusi job vs waktu aktif cluster)?
- Berapa biaya setiap cluster (DBU + VM)?
Ketika tabel sistem Unity Catalog (misalnya, system.job_run_logs) tidak tersedia, pendekatan berbasis SQL default gagal. REST API menjadi alternatif yang dapat diandalkan.
Pendekatan tingkat tinggi yang digunakan dalam notebook
- List cluster melalui /api/2.0/clusters/list.
- Estimasi waktu aktif cluster menggunakan timestamp di dalam JSON cluster (field created/start/terminated). (Ini adalah fallback pragmatis ketika /clusters/events tidak tersedia.)
- Dapatkan job runs terbaru menggunakan /api/2.1/jobs/runs/list dengan filter waktu (atau limit).
- Cocokkan job runs dengan cluster menggunakan cluster_instance.cluster_id (atau metadata cluster lainnya).
- Hitung utilisasi: utilisasi % = total_job_runtime / total_cluster_uptime.
- Estimasi biaya menggunakan formula sederhana: biaya = running_hours × (DBU/hr × asumsi DBU) + running_hours × nodes × VM $/hr.
Notebook ini sengaja menggunakan query terbatas (N run terakhir, jendela waktu) agar berjalan cepat.
\ 1. Setup & Konfigurasi
# Databricks Cluster Utilization & Cost Analyzer (no system tables) # Author: GPT-5 | Works on any workspace with REST API access # Requirements: Databricks Personal Access Token, Workspace URL # You can run this inside a Databricks notebook or externally. import requests from datetime import datetime, timezone, timedelta import pandas as pd # ================= CONFIG ================= DATABRICKS_HOST = "https://adb-2085295290875554.14.azuredatabricks.net/" # Replace with your workspace URL # DATABRICKS_TOKEN = "" # Replace with your PAT HEADERS = {"Authorization": f"Bearer {token}"} params={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} # Time window (e.g., last 7 days) DAYS_BACK = 7 SINCE_TS_MS = int((datetime.now(timezone.utc) - timedelta(days=DAYS_BACK)).timestamp() * 1000) UNTIL_TS_MS = int(datetime.now(timezone.utc).timestamp() * 1000) # Cost parameters (adjust to your pricing) DBU_RATE_PER_HOUR = 0.40 # $ per DBU/hr VM_COST_PER_NODE_PER_HOUR = 0.60 # $ per cloud VM node/hr DEFAULT_DBU_PER_CLUSTER_PER_HOUR = 8 # Typical for small-medium jobs cluster # ==========================================
\ Bagian ini menginisialisasi:
- URL Workspace & token untuk autentikasi
- Rentang waktu yang ingin Anda analisis utilisasinya
- Asumsi biaya:
- Tarif DBU ($/hr per DBU)
- Biaya node VM
- Konsumsi DBU perkiraan
Dalam setup enterprise, tarif ini dapat diambil secara dinamis melalui FinOps atau API billing Anda.
-
Fungsi Wrapper API
\
# Api GET request def api_get(path, params=None): url = f"{DATABRICKS_HOST.rstrip('/')}{path}" try: r = requests.get(url, headers=HEADERS, params=params, timeout=60) if r.status_code == 404: print(f"Skipping :{path} (404 Not Found)") return {} r.raise_for_status() return r.json() except Exception as e: print(f"Error: {e}") return {}
\ Fungsi helper ini menstandarkan semua panggilan REST API GET. \n Fungsi ini:
-
Membangun URL endpoint lengkap
-
Menangani 404 dengan baik (penting ketika cluster atau run telah kedaluwarsa)
-
Mengembalikan JSON yang telah di-parse
Mengapa ini penting: Fungsi ini memastikan komunikasi API yang bersih tanpa merusak alur notebook Anda jika ada data cluster yang hilang.
\
-
List Semua Cluster Aktif
\
# ---------- STEP 1: Get All Clusters Related Details ---------- def list_clusters(): clusters = [] res = api_get("/api/2.0/clusters/list") return res.get("clusters", [])
\ Ini mengambil semua cluster yang tersedia di workspace Anda. \n Ini setara dengan melihat tab "Compute" Anda secara programatis. \n Response berisi:
-
ID Cluster
-
Nama
-
Jumlah node
-
Informasi creator
-
Waktu pembuatan & terminasi
Kasus penggunaan: Membantu mengidentifikasi cluster mana yang mengonsumsi sumber daya dalam jendela yang dipilih.
4. Estimasi Runtime Cluster
\
# ---------- STEP 2: Get Cluster Events Runtime ---------- def get_cluster_runtime(cluster): events = [] offset = 0 limit = 200 # while True: # params = {"cluster_id": cluster_id} created = cluster.get("creator_user_name") created_time = cluster.get("start_time") or cluster.get("created_time") terminated_time = cluster.get("terminated_time") if not created_time: return 0 end_ts = terminated_time or UNTIL_TS_MS start_ms = max(created_time, SINCE_TS_MS) runtime_ms = max(0, end_ts - start_ms) return runtime_ms /1000/3600
\ Kami menghitung total jam berjalan untuk setiap cluster:
-
Menggunakan timestamp pembuatan dan terminasi
-
Menangani cluster yang sedang berjalan (terminated_time hilang)
-
Menormalisasi ke jam
Mengapa ini penting: Nilai ini adalah denominator untuk utilisasi — mewakili total waktu aktif cluster selama jendela waktu.
5. Dapatkan Job Runs Terbaru
\
# ------------------Get Recent Job Runs ---------------------------- def get_recent_job_runs(): params ={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} res = api_get("/api/2.1/jobs/runs/list", params) return res.get("runs", [])
\ Alih-alih mengambil seluruh riwayat job (yang lambat), \n Fungsi ini mengambil 10 job runs terbaru untuk diagnostik cepat.
Dalam production, Anda dapat memfilter berdasarkan:
- job_id spesifik
- completed_only=true
- Jendela tanggal (start_time_from, start_time_to)
\
-
Hitung Utilisasi dan Biaya
\
# -------------------------------------Compute Cost and parse cluster utilization detials --------------------- def compute_utilization_and_cost(clusters, job_runs): records =[] now_ms = int(datetime.now(timezone.utc).timestamp() * 1000) for c in clusters: cid = c.get("cluster_id") cname = c.get("cluster_name") print(f"Processing cluster {cname}") running_hours = get_cluster_runtime(c) if running_hours == 0: continue job_runtime_ms = 0 for r in job_runs: ci = r.get("cluster_instance",{}) if ci.get("cluster_id") == cid: s = r.get("start_time") or SINCE_TS_MS e = r.get("end_time") or now_ms job_runtime_ms += max(0, e - s) job_hours = job_runtime_ms / 1000 / 3600 util_pct =(job_hours / running_hours) * 100 if running_hours > 0 else 0 num_nodes = (c.get("num_workers") or c.get("autoscale",{}).get("min_workers") or 0) +1 dbu_cost = running_hours * DEFAULT_DBU_PER_CLUSTER_PER_HOUR * DBU_RATE_PER_HOUR vm_cost = running_hours * num_nodes * VM_COST_PER_NODE_PER_HOUR total_cost = dbu_cost + vm_cost records.append({ "cluster_id": cid, "cluster_name": cname,"running_hours":round(running_hours,2), "job_hours": round(job_hours,2) ,"utilization_pct": round(util_pct,2), "nodes": num_nodes,"dbu_cost": round(dbu_cost,2), "vm_cost": round(vm_cost,2), "total_cost": round(total_cost,2) }) return pd.DataFrame(records)
Ini adalah inti dari logika:
-
Melakukan loop melalui setiap cluster
-
Menghitung total runtime job per cluster (menggunakan API job runs)
-
Menurunkan persentase utilisasi = (job_hours / cluster_running_hours) × 100
-
Estimasi biaya:
- Biaya DBU berdasarkan tarif × DBU/hr
- Biaya VM = node_count × node_cost/hr × running_hours
Mengapa ini penting: \n Ini memberikan gambaran terpadu tentang efisiensi dan pengeluaran — berguna untuk mengidentifikasi cluster dengan biaya tinggi tetapi utilisasi rendah.
7. Orkestrasi Pipeline
\
# ---------- MAIN ---------- print(f"Collecting data for last {DAYS_BACK} days...") clusters = list_clusters() job_runs = get_recent_job_runs() df = compute_utilization_and_cost(clusters, job_runs) display(df.sort_values("utilization_pct", ascending=False))
\ Blok final ini:
-
Mengambil data
-
Melakukan komputasi biaya
-
Menampilkan Data Frame yang telah diurutkan
Dalam praktiknya, Data Frame ini dapat:
-
Diekspor ke Excel atau Delta Table
-
Dikirim ke dashboard Power BI
-
Diintegrasikan ke dalam pipeline otomasi FinOps
\
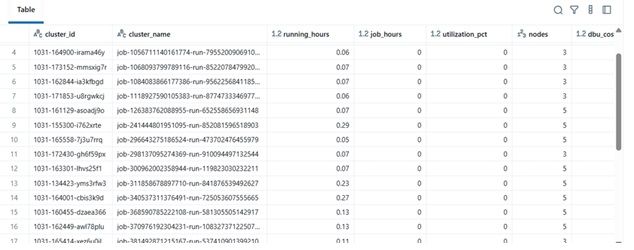
Contoh Hasil
| cluster_name | running_hours | job_hours | utilization_pct | nodes | total_cost | |----|----|----|----|----|----| | etl-job-prod | 36.5 | 28.0 | 76.7% | 4 | $142.8 | | dev-debug | 12.0 | 1.2 | 10.0% | 2 | $18.4 | | nightly-adf | 48.0 | 45.0 | 93.7% | 6 | $260.4 |
\ 
\ \
-
Manfaat Dunia Nyata
Dengan menerapkan penganalisis ini:
-
Tim engineering dapat melacak biaya cluster bahkan tanpa akses audit.
-
Manajer mendapatkan visibilitas ke cluster yang kurang dimanfaatkan.
-
DevOps dapat secara otomatis menghentikan cluster dengan penggunaan rendah.
-
Finance dapat memvalidasi invoice Databricks dengan metrik internal.
Dalam proyek MSC kami, kami menggunakan ini sebagai bagian dari stack observabilitas platform data kami — menggabungkan data REST API, log job ADF, dan tren biaya ke dalam dashboard terpadu.
\


Anda Mungkin Juga Menyukai

GraniteShares Menunda Peluncuran ETF XRP 3x Namun Akumulasi Terus Berlanjut

XRP Mengirim Sinyal On-Chain Bullish Meskipun Pergerakan Harga Lemah




