

Mengatasi Hambatan Terbesar Segmentasi 3D
:::info Penulis:
(1) George Tang, Massachusetts Institute of Technology;
(2) Krishna Murthy Jatavallabhula, Massachusetts Institute of Technology;
(3) Antonio Torralba, Massachusetts Institute of Technology.
:::
Daftar Tautan
Abstrak dan I. Pendahuluan
II. Latar Belakang
III. Metode
IV. Eksperimen
V. Kesimpulan dan Referensi
\ 
\ Abstrak— Kami mengatasi masalah pembelajaran representasi adegan implisit untuk segmentasi instans 3D dari urutan gambar RGB yang diposisikan. Untuk itu, kami memperkenalkan 3DIML, kerangka kerja baru yang secara efisien mempelajari bidang label yang dapat dirender dari sudut pandang baru untuk menghasilkan masker segmentasi instans yang konsisten. 3DIML secara signifikan meningkatkan waktu pelatihan dan inferensi dari metode berbasis representasi adegan implisit yang ada. Berbeda dengan karya sebelumnya yang mengoptimalkan bidang neural secara self-supervised, yang memerlukan prosedur pelatihan rumit dan desain fungsi kerugian, 3DIML memanfaatkan proses dua fase. Fase pertama, InstanceMap, mengambil masker segmentasi 2D dari urutan gambar yang dihasilkan oleh model segmentasi instans frontend, dan mengaitkan masker yang sesuai di seluruh gambar ke label 3D. Masker pseudolabel yang hampir konsisten ini kemudian digunakan dalam fase kedua, InstanceLift, untuk mengawasi pelatihan bidang label neural, yang menginterpolasi area yang terlewatkan oleh InstanceMap dan menyelesaikan ambiguitas. Selain itu, kami memperkenalkan InstanceLoc, yang memungkinkan lokalisasi masker instans mendekati waktu nyata dengan bidang label terlatih dan model segmentasi gambar siap pakai dengan menggabungkan output dari keduanya. Kami mengevaluasi 3DIML pada urutan dari dataset Replica dan ScanNet dan mendemonstrasikan efektivitas 3DIML di bawah asumsi ringan untuk urutan gambar. Kami mencapai peningkatan kecepatan praktis yang besar dibandingkan metode representasi adegan implisit yang ada dengan kualitas sebanding, menunjukkan potensinya untuk memfasilitasi pemahaman adegan 3D yang lebih cepat dan lebih efektif.
I. PENDAHULUAN
Agen cerdas memerlukan pemahaman adegan pada tingkat objek untuk secara efektif melaksanakan tindakan spesifik konteks seperti navigasi dan manipulasi. Sementara segmentasi objek dari gambar telah mengalami kemajuan luar biasa dengan model yang dapat diskalakan yang dilatih pada dataset skala internet [1], [2], memperluas kemampuan tersebut ke pengaturan 3D tetap menjadi tantangan.
\ Dalam karya ini, kami mengatasi masalah pembelajaran representasi adegan 3D dari gambar 2D yang diposisikan yang memfaktorkan adegan yang mendasarinya menjadi kumpulan objek konstituennya. Pendekatan yang ada untuk mengatasi masalah ini telah berfokus pada pelatihan model segmentasi 3D agnostik kelas [3], [4], yang memerlukan sejumlah besar data 3D beranotasi, dan beroperasi langsung pada representasi adegan 3D eksplisit (misalnya, pointclouds). Kelas pendekatan alternatif [5], [6] telah mengusulkan untuk langsung mengangkat masker segmentasi dari model segmentasi instans siap pakai ke dalam representasi 3D implisit, seperti neural radiance fields (NeRF) [7], memungkinkan mereka untuk merender masker instans yang konsisten secara 3D dari sudut pandang baru.
\ Namun, pendekatan berbasis bidang neural tetap sulit dioptimalkan, dengan [5] dan [6] membutuhkan beberapa jam untuk mengoptimalkan gambar resolusi rendah hingga menengah (misalnya, 300 × 640). Secara khusus, Panoptic Lifting [5] menskalakan secara kubik dengan jumlah objek dalam adegan yang mencegahnya diterapkan pada adegan dengan ratusan objek, sementara Contrastively Lifting [6] memerlukan prosedur pelatihan multi-tahap yang rumit, menghambat kepraktisan untuk digunakan dalam aplikasi robotika.
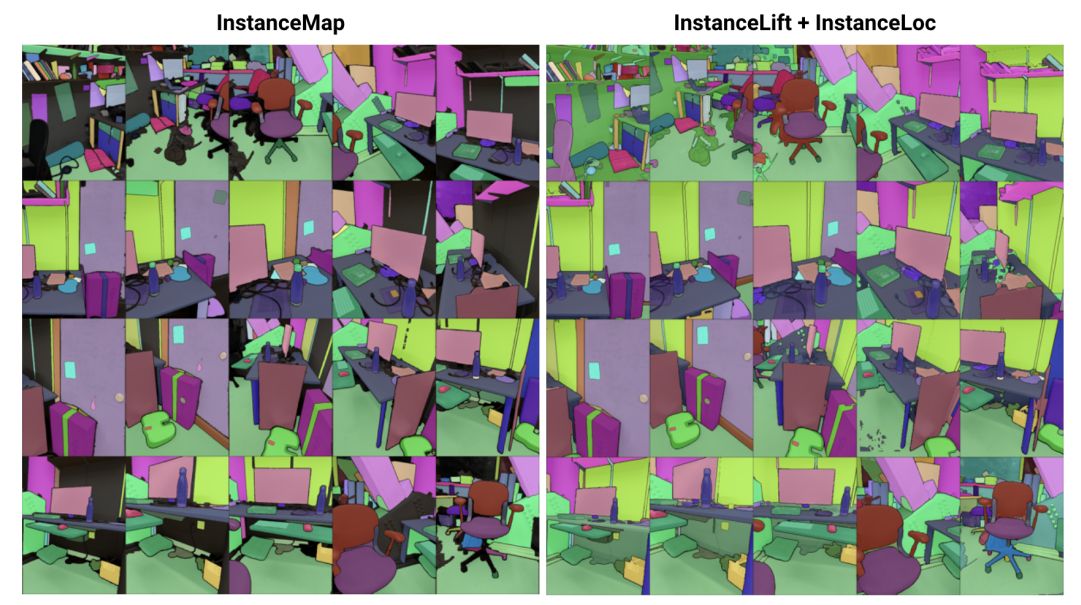
\ Untuk itu, kami mengusulkan 3DIML, teknik efisien untuk mempelajari segmentasi instans yang konsisten secara 3D dari gambar RGB yang diposisikan. 3DIML terdiri dari dua fase: InstanceMap dan InstanceLift. Diberikan masker instans 2D yang tidak konsisten yang diekstrak dari urutan RGB menggunakan model segmentasi instans frontend [2], InstanceMap menghasilkan urutan masker instans yang konsisten. Untuk melakukannya, kami pertama-tama mengaitkan masker di seluruh frame menggunakan kecocokan keypoint antara pasangan gambar yang serupa. Kami kemudian menggunakan asosiasi yang berpotensi berisik ini untuk mengawasi bidang label neural, InstanceLift, yang memanfaatkan struktur 3D untuk menginterpolasi label yang hilang dan menyelesaikan ambiguitas. Tidak seperti karya sebelumnya, yang memerlukan pelatihan multi-tahap dan rekayasa fungsi kerugian tambahan, kami menggunakan satu kerugian rendering untuk supervisi label instans, memungkinkan proses pelatihan untuk konvergen secara signifikan lebih cepat. Total waktu eksekusi 3DIML, termasuk InstanceMap, memakan waktu 10-20 menit, dibandingkan dengan 3-6 jam untuk karya sebelumnya.
\ Selain itu, kami merancang InstaLoc, pipeline lokalisasi cepat yang menerima tampilan baru dan melokalisasi semua instans yang disegmentasi dalam gambar tersebut (menggunakan model segmentasi instans cepat [8]) dengan menanyakan bidang label secara jarang dan menggabungkan prediksi label dengan area gambar yang diekstrak. Akhirnya, 3DIML sangat modular, dan kami dapat dengan mudah menukar komponen metode kami dengan yang lebih berkinerja saat tersedia.
\ Untuk merangkum, kontribusi kami adalah:
\ • Pendekatan pembelajaran bidang neural yang efisien yang memfaktorkan adegan 3D menjadi objek konstituennya
\ • Algoritma lokalisasi instans cepat yang menggabungkan kueri jarang ke bidang label terlatih dengan model segmentasi instans gambar berkinerja untuk menghasilkan masker segmentasi instans yang konsisten secara 3D
\ • Peningkatan waktu eksekusi praktis keseluruhan sebesar 14-24× dibandingkan karya sebelumnya yang diuji pada satu GPU (NVIDIA RTX 3090)
II. LATAR BELAKANG
Segmentasi 2D: Prevalensi arsitektur vision transformer dan peningkatan skala dataset gambar telah menghasilkan serangkaian model segmentasi gambar state-of-the-art. Panoptic dan Contrastive Lifting keduanya mengangkat masker segmentasi panoptik yang dihasilkan oleh Mask2Former [1] ke 3D dengan mempelajari bidang neural. Menuju segmentasi open-set, segment anything (SAM) [2] mencapai kinerja yang belum pernah terjadi sebelumnya dengan pelatihan pada satu miliar masker di lebih dari 11 juta gambar. HQ-SAM [9] meningkatkan SAM untuk masker yang lebih detail. FastSAM [8] menyuling SAM ke dalam arsitektur CNN dan mencapai kinerja serupa sambil menjadi lebih cepat beberapa kali lipat. Dalam karya ini, kami menggunakan GroundedSAM [10], [11], yang menyempurnakan SAM untuk menghasilkan segmentasi masker tingkat objek, bukan tingkat bagian.
\ Bidang neural untuk segmentasi instans 3D: NeRF adalah representasi adegan implisit yang dapat secara akurat mengkodekan geometri kompleks, semantik, dan modalitas lainnya, serta menyelesaikan supervisi yang tidak konsisten dari sudut pandang [12]. Panoptic lifting [5] membangun cabang semantik dan instans pada varian NeRF yang efisien, TensoRF [13], memanfaatkan fungsi kerugian Hungarian matching untuk menetapkan masker instans yang dipelajari ke ID objek pengganti yang diberikan masker referensi yang tidak konsisten. Ini menskalakan dengan buruk dengan peningkatan jumlah objek (karena kompleksitas kubik dari Hungarian matching). Contrastive lifting [6] mengatasi ini dengan menggunakan pembelajaran kontrastif pada fitur adegan, dengan hubungan positif dan negatif ditentukan oleh apakah mereka diproyeksikan ke masker yang sama atau tidak. Selain itu, contrastive lifting memerlukan kerugian berbasis clustering slow-fast untuk pelatihan yang stabil, menghasilkan kinerja yang lebih cepat daripada panoptic lifting tetapi memerlukan beberapa tahap pelatihan, yang menyebabkan konvergensi lambat. Bersamaan dengan kami, Instance-NeRF [14] langsung mempelajari bidang label, tetapi mereka mendasarkan asosiasi masker mereka pada penggunaan NeRF-RPN [15] untuk mendeteksi objek dalam NeRF. Pendekatan kami, sebaliknya, memungkinkan penskalaan ke resolusi gambar yang sangat tinggi sambil hanya memerlukan sejumlah kecil (40-60) kueri bidang neural untuk merender masker segmentasi.
\ Structure from Motion: Selama asosiasi masker di InstanceMap, kami terinspirasi dari pipeline rekonstruksi 3D yang dapat diskalakan seperti hLoc [16], termasuk penggunaan deskriptor visual untuk mencocokkan sudut pandang gambar terlebih dahulu, kemudian menerapkan pencocokan keypoint sebagai pendahuluan untuk asosiasi masker. Kami menggunakan LoFTR [17] untuk ekstraksi dan pencocokan keypoint.
\
:::info Makalah ini tersedia di arxiv di bawah lisensi CC by 4.0 Deed (Attribution 4.0 International).
:::
\


Anda Mungkin Juga Menyukai

Bukan celah hukum: Kontrol ekspor AI Singapura memungkinkan Tiongkok mengakses AI AS secara legal

Futures Perpetual Bitcoin: Rasio Long/Short di Bursa Teratas

Ekosistem Token LAB: Panduan Platform Perdagangan Multi-Rantai & Imbalan



